







大数据-Spark调优(三)
Spark在Driver上对Application的每一个stage的task进行分配之前,都会计算出每个task要计算的是哪个分片数据,RDD的某个partition;Spark的task分配算法,优先会希望每个task正好分配到它要计算的数据所在的节点,这样的话就不用在网络间传输数据;
但是通常来说,有时事与愿违,可能task没有机会分配到它的数据所在的节点,为什么呢,可能那个节点的计算资源和计算能力都满了;所以这种时候,通常来说,Spark会等待一段时间,默认情况下是3秒(不是绝对的,还有很多种情况,对不同的本地化级别,都会去等待),到最后实在是等待不了了,就会选择一个比较差的本地化级别,比如说将task分配到距离要计算的数据所在节点比较近的一个节点,然后进行计算。
本地化级别
(1)PROCESS_LOCAL:进程本地化
代码和数据在同一个进程中,也就是在同一个executor中;计算数据的task由executor执行,数据在executor的BlockManager中;性能最好
(2)NODE_LOCAL:节点本地化
代码和数据在同一个节点中;比如说数据作为一个HDFS block块,就在节点上,而task在节点上某个executor中运行;或者是数据和task在一个节点上的不同executor中;数据需要在进程间进行传输;性能其次
(3)RACK_LOCAL:机架本地化
数据和task在一个机架的两个节点上;数据需要通过网络在节点之间进行传输; 性能比较差
(4) ANY:无限制
数据和task可能在集群中的任何地方,而且不在一个机架中;性能最差。
数据本地化等待时长
spark.locality.wait,默认是3s
首先采用最佳的方式,等待3s后降级,还是不行,继续降级...,最后还是不行,只能够采用最差的。
如何调节参数并且测试
修改spark.locality.wait参数,默认是3s,可以增加
下面是每个数据本地化级别的等待时间,默认都是跟spark.locality.wait时间相同,
默认都是3s(可查看spark官网对应参数说明,如下图所示)
spark.locality.wait.node
spark.locality.wait.process
spark.locality.wait.rack

在代码中设置:
new SparkConf().set("spark.locality.wait","10")
然后把程序提交到spark集群中运行,注意观察日志,spark作业的运行日志,推荐大家在测试的时候,先用client模式,在本地就直接可以看到比较全的日志。
日志里面会显示,starting task .... PROCESS LOCAL、NODE LOCAL.....
例如:
Starting task 0.0 in stage 1.0 (TID 2, 192.168.200.102, partition 0, NODE_LOCAL, 5254 bytes)
观察大部分task的数据本地化级别
如果大多都是PROCESS_LOCAL,那就不用调节了。如果是发现,好多的级别都是NODE_LOCAL、ANY,那么最好就去调节一下数据本地化的等待时长。应该是要反复调节,每次调节完以后,再来运行,观察日志
看看大部分的task的本地化级别有没有提升;看看整个spark作业的运行时间有没有缩短。
注意:
在调节参数、运行任务的时候,别本末倒置,本地化级别倒是提升了, 但是因为大量的等待时长,spark作业的运行时间反而增加了,那就还是不要调节了。
基于Spark内存模型调优
spark中executor内存划分
Executor的内存主要分为三块
- 第一块是让task执行我们自己编写的代码时使用;
- 第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用
- 第三块是让RDD缓存时使用
spark的内存模型
在spark1.6版本以前 spark的executor使用的静态内存模型,但是在spark1.6开始,多增加了一个统一内存模型。
通过spark.memory.useLegacyMode 这个参数去配置
默认这个值是false,代表用的是新的动态内存模型;
如果想用以前的静态内存模型,那么就要把这个值改为true。
静态内存模型

实际上就是把我们的一个executor分成了三部分,
一部分是Storage内存区域,
一部分是execution区域,
还有一部分是其他区域。如果使用的静态内存模型,那么用这几个参数去控制:
spark.storage.memoryFraction:默认0.6
spark.shuffle.memoryFraction:默认0.2
所以第三部分就是0.2
如果我们cache数据量比较大,或者是我们的广播变量比较大,
那我们就把spark.storage.memoryFraction这个值调大一点。
但是如果我们代码里面没有广播变量,也没有cache,shuffle又比较多,那我们要把spark.shuffle.memoryFraction 这值调大。
静态内存模型的缺点
我们配置好了Storage内存区域和execution区域后,我们的一个任务假设execution内存不够用了,但是它的Storage内存区域是空闲的,两个之间不能互相借用,不够灵活,所以才出来我们新的统一内存模型。
统一内存模型

动态内存模型先是预留了300m内存,防止内存溢出。动态内存模型把整体内存分成了两部分,由这个参数表示spark.memory.fraction 这个指的默认值是0.6 代表另外的一部分是0.4,然后spark.memory.fraction 这部分又划分成为两个小部分。这两小部分共占整体内存的0.6 .这两部分其实就是:Storage内存和execution内存。由spark.memory.storageFraction 这个参数去调配,因为两个共占0.6。如果spark.memory.storageFraction这个值配的是0.5,那说明这0.6里面 storage占了0.5,也就是executor占了0.3 。
- 统一内存模型有什么特点呢?
Storage内存和execution内存 可以相互借用。不用像静态内存模型那样死板,但是是有规则的。
- 场景一
Execution使用的时候发现内存不够了,然后就会把storage的内存里的数据驱逐到磁盘上。
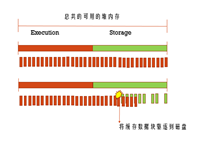
- 场景二
一开始execution的内存使用得不多,但是storage使用的内存多,所以storage就借用了execution的内存,但是后来execution也要需要内存了,这个时候就会把storage的内存里的数据写到磁盘上,腾出内存空间。
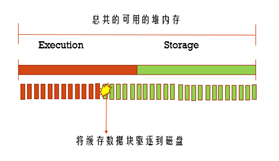
为什么受伤的都是storage呢?是因为execution里面的数据是马上就要用的,而storage里的数据不一定马上就要用。
此博文仅供学习参考,如有错误欢迎指正。
上一篇《大数据-Spark调优(二)》
下一篇《大数据-MaxWell》
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









