







转自:http://blog.csdn.net/shuzfan/article/details/51678499
本次介绍的是一种压缩神经网络模型大小的方法,来自《2014 arxiv:Compressing Deep Convolutional Networks using Vector Quantization》。该方法和很多之前的神经网络压缩方法一样,基本只对全连接层有效,因此这里权作了解。
由论文名可以看出,主要是对密集权重矩阵进行量化编码来实现压缩。
论文做了很多种量化方法的对比试验,不过都只针对全连接层,至于为什么不处理卷积层,大家可以考虑一下。下面就简单介绍一下这些方法。
SVD分解
全连接层的权重矩阵记作 W∈Rm×n ,首先对 W 进行 SVD 分解,如下:
W=USVT
为了能够用两个较小的矩阵来表示 W ,我们可以取奇异值的前 K 个分量。于是,W可以通过下式重建:
W^=U^S^V^T,其中U^∈Rm×kV^∈Rn×k
我们唯一需要保存的就是3个比较小的矩阵 U,S,V ,我们可以简单算一下压缩比为 mn/k(m+n+1)
二值化
这种量化方法的想法来自于Dropconnect,量化如下:
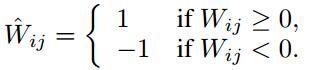
假设原来的 W 是 float 型数据,则压缩比为 32
K-Mmeans 标量量化
首先把 W∈Rm×n 整成标量 w∈R1×mn ,然后进行K均值,于是每一个 Wij 都可以用距离其最近的聚类中心表示,于是我们需要存储的只有 m×n 个索引,以及 K 个聚类中心。
乘积量化
乘积量化就是把原始数据划分成若干个子空间,在每个子空间中分别进行K-Means。
比如原来的 W 是 m×n 维的,我们可以把列(or 行)分成S份,即 W=[W1,…WS] ,然后对每一个 Ws 进行K-Means。
残差量化
残差量化可以看做是一种分层量化、迭代量化。
首先对原始的 W 使用K-Means的,然后用聚类中心对其进行表示 Wc1 ,然后计算残差 W′=W−Wc1 。对 W′ 继续K-means,重复上述过程。于是, Wi 可以表示为多级聚类中心之和:
Wi=c1j+c2j+…+ctj
对比试验
接下来就是大量的对比试验,这里只列举一部分:(试验都在AlexNet的全连接层进行操作)
下图的横坐标是PQ的子空间分割数,K代表子空间中聚类的个数。
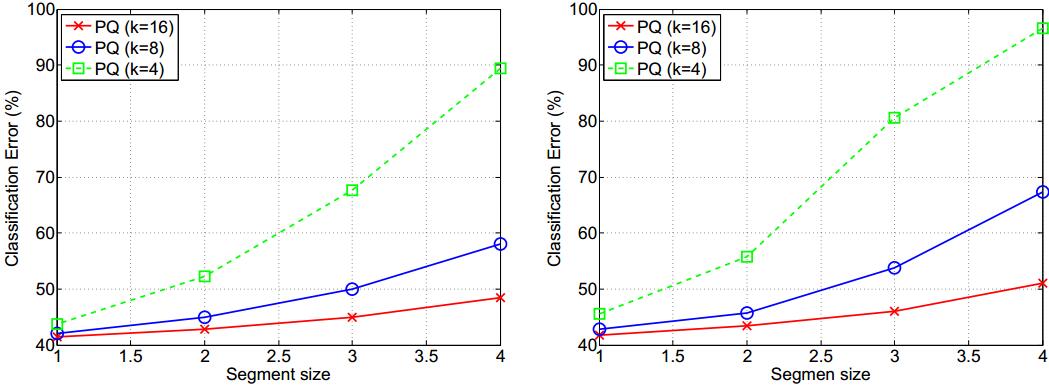
下图是不同方法的对比,结果发现PQ较好。此外为了综合考量准确率与压缩比,这里PQ中K=8。
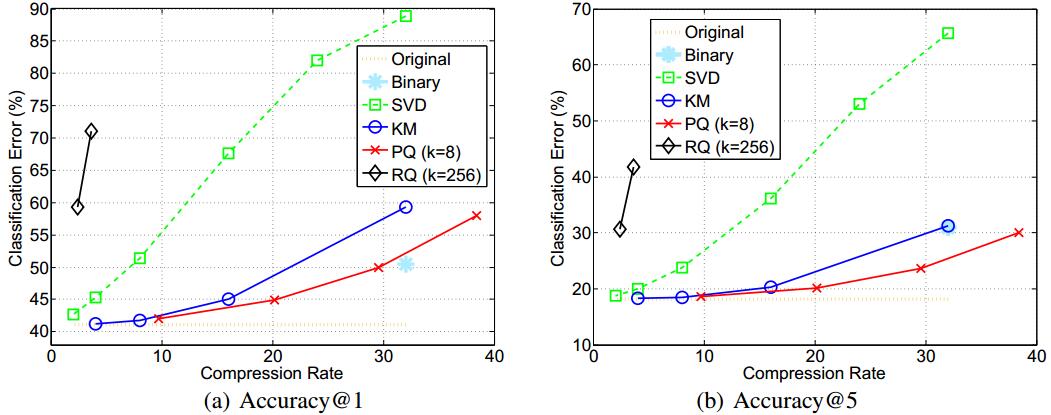
总结
论文是Facebook投到2015ICLR的,估计是被拒了,因为通篇只有对比试验而没有自己原创内容。此外,我们唯一可以收获的是了解了一些简单的量化方法,而这些方法是可以作为其它高级方法的基础的。















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









