






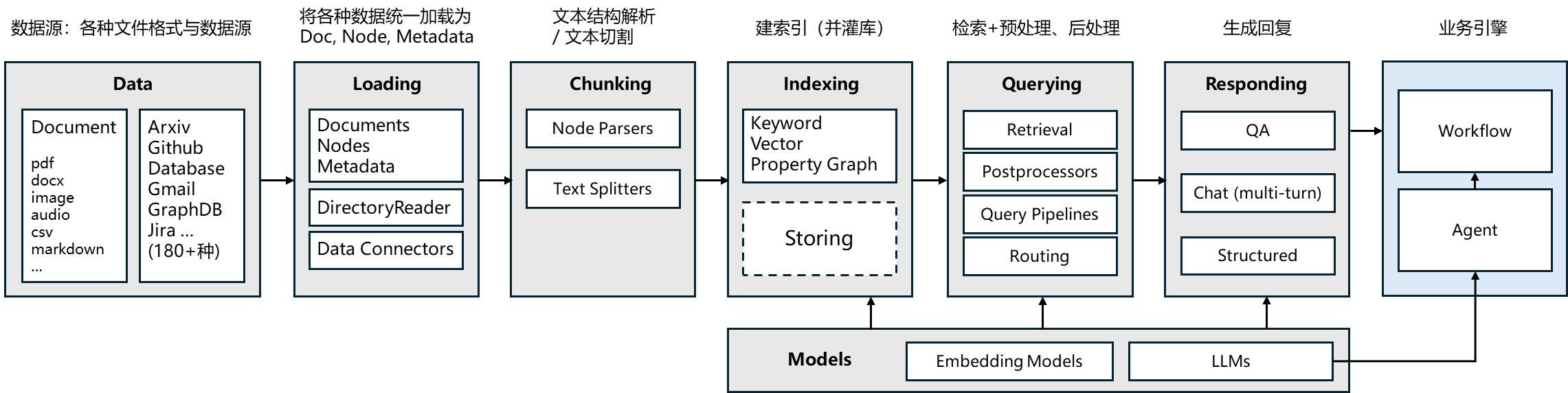
Llamaindex框架主要做RAG,工作流用LangGraph做
换源:
-i https://pypi.mirrors.ustc.edu.cn/simple/
环境搭建:
conda create -n llamaindex python=3.12
conda activate llamaindex
pip install llama-index
pip install llama-cloud-services
pip install llama-index-readers-web
pip install llama-index-vector-stores-qdrant
pip install --upgrade llama-index -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install llama-index-llms-dashscope -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install llama-index-llms-openai-like -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install llama-index-embeddings-dashscope -i https://pypi.mirrors.ustc.edu.cn/simple/
Environment.yml
llamaindex主要阶段分为:
数据读取
构建索引
搜搜引擎
一、模型加载
import os
# setting配置llm的embedding、推理模型
from llama_index.core import Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.llms.dashscope import DashScope
from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels
# LlamaIndex默认使用的大模型被替换为百炼
# Settings.llm = OpenAILike(
# model="qwen-max",
# api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
# is_chat_model=True
# )
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
# LlamaIndex默认使用的Embedding模型被替换为百炼的Embedding模型
Settings.embed_model = DashScopeEmbedding(
# model_name="text-embedding-v1"
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,
# api_key=os.getenv("DASHSCOPE_API_KEY")
)
二、Llamindex基本流程
# RAG加载
from llama_index.core import VectorStoreIndex,SimpleDirectoryReader
documents = SimpleDirectoryReader(r"G:\python_ws_g\code\RAG\qwen_agent\data\docs").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("deepseek v3有多少参数?")
三、数据加载器
Llamaindex内置的文件加载器(读取本地的):
https://llamahub.ai/l/readers/llama-index-readers-file
读取纯文本
自带的SimpleDirectoryReader:
这个读取纯文本还可以
import json
from pydantic.v1 import BaseModel
def show_json(data):
"""用于展示json数据"""
if isinstance(data, str):
obj = json.loads(data)
print(json.dumps(obj, indent=4, ensure_ascii=False))
elif isinstance(data, dict) or isinstance(data, list):
print(json.dumps(data, indent=4, ensure_ascii=False))
elif issubclass(type(data), BaseModel):
print(json.dumps(data.dict(), indent=4, ensure_ascii=False))
def show_list_obj(data):
"""用于展示一组对象"""
if isinstance(data, list):
for item in data:
show_json(item)
else:
raise ValueError("Input is not a list")
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_dir=r"G:\python_ws_g\code\RAG\data\txt", # 目标目录
# input_dir=r"G:\python_ws_g\code\RAG\data\pdf", # 目标目录
recursive=False, # 是否递归遍历子目录
required_exts=[".pdf",".txt"] # (可选)只读取指定后缀的文件
)
documents = reader.load_data()
print(documents[0].text)
show_json(documents[0].json())
读取pdf
- 阿里智能文档技术(主推)
- 自带的PDFReader
注册:https://cloud.llamaindex.ai
# 在系统环境变量里配置 LLAMA_CLOUD_API_KEY=XXX
from llama_cloud_services import LlamaParse
from llama_index.core import SimpleDirectoryReader
import nest_asyncio
nest_asyncio.apply() # 只在Jupyter笔记环境中需要此操作,否则会报错
# set up parser
parser = LlamaParse(
result_type="markdown" # "markdown" and "text" are available
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(input_dir="./data", required_exts=[".pdf"], file_extractor=file_extractor).load_data()
print(documents[0].text)
效果:
Started parsing the file under job_id 0ae4e49a-6b27-4e0c-8ce0-a214c0d1f41d
# DeepSeek-V3 Technical Report
# DeepSeek-AI
research@deepseek.com
# Abstract
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
|DeepSeek-V3|DeepSeek-V2.5|Qwen2.5-72B-Inst|Llama-3.1-405B-Inst|GPT-4o-0513|Claude-3.5-Sonnet-1022| |
|---|---|---|---|---|---|---|
|100|90.2| | | | | |
|80|75.9|71.6|73.3|72.6|78.0| |
| |74.7|80.0|73.8|74.6|78.3| |
|66.2| |65.0| | | | |
|60| |59.1| | | | |
|49.0|51.1|49.9| |51.6|50.8| |
|40|41.3|39.2| |42.0|38.8| |
| | | | |35.6| | |
|20| | | |20.3| | |
| |16.7|16.0| |9.3| | |
|0|MMLU-Pro|GPQA-Diamond|MATH 500|AIME 2024|Codeforces|SWE-bench Verified|
Figure 1 | Benchmark performance of DeepSeek-V3 and its counterparts.
读取网站(读取第三方网站的)
Llamaindex内置的文件加载器(读取本地的):
https://llamahub.ai/l/readers/llama-index-readers-file
from llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://edu.guangjuke.com/tx/"]
)
print(documents[0].text)
Login
__
用户登录

[ 登录](javascript:void\(0\))
[忘记密码?](/user/Users/retrieve_password.html) [立即注册](/reg)
快捷登录 | [__](/index.php?m=plugins&c=QqLogin&a=login)[__](/index.php?m=plugins&c=WxLogin&a=login)[__](/index.php?m=plugins&c=Wblogin&a=login)
[

](https://edu.guangjuke.com)
[首页](https://edu.guangjuke.com)
[全部课程](https://edu.guangjuke.com/shipinkecheng/)
[资源下载](https://edu.guangjuke.com/ziyuanxiazai/)
[系统课](https://edu.guangjuke.com/tx/)
[图书馆](https://edu.guangjuke.com/document.html)
[精选好文](https://edu.guangjuke.com/haowen/)
[聚客社区](https://edu.guangjuke.com/ask.html)
[关于我们](https://www.guangjuke.com/about/)
[登录/注册](https://edu.guangjuke.com/user)

# 锤炼前沿实战精华,独创多领域大模型人才培养方案
Kevin聚客科技联合创始人/技术总监(CTO)
华为高级架构师互联网AI领域专家
互联网后端技术领域15年从业经验,曾任职华为、新一代技术研究院,对Open AI、Azure AI、Google AI等大模型有丰富的实战项目经验。
Aron人工智能研究院研究员
人工智能算法研究员医疗领域AI专家
8年深度学习算法研发经验,精通深度学习框架,有丰富的GPU模型加速,移动端模型加速,模型优化,模型部署经验 。
BoboAI系列课程的布道者
互联网AI技术专家企业高级架构师
互联网后端技术领域15年从业经验,曾在知名企业用友、华电和百丽担任要职。历任高级软件开发工程师、系统架构师及首席技术官(CTO)。
Anny国家工信部AI认证专家
高级Python工程师首批大模型研发者
数十年开发经验,深耕大数据、智能体、大模型垂直应用解决方案、AI应用工程等领域。
Ray深度人工智能教育创始人
高级AI算法工程师深度智谷科技创始人
5年人工智能算法领域研发经验,6年人工智能教学经验,具备扎实的人工智能算法理论基础知识和丰富的项目实战经验.
Cyber
金融大厂架构师互联网连续创业者
AI人工智能领域6年从业经验,对Open AI、Azure AI、Google AI、SD AI等AI大模型有丰富的实战项目经验。
#### 福利一:高性能GPU资源
提供学习阶段进行训练的线上实验室算力资源,帮助学生进行学习阶段的模型训练、练习。
#### 福利二:大模型项目资源库
超值附赠大量大模型项目资源库,包括丰富的代码示例和数据集,供学员在学习过程中使用和参考,加速学员的项目实践和技能提升。
扫码添加专属老师
获取更多福利信息
# 六大模块递进式学习,更顺滑、更高效实现大模型能力跃迁
Hugging Face核心组件使用
模型部署推理
Datasets数据工程
DeepSpeed分布式训练
SFT微调训练
模型合并、打包、部署
模型量化核心算法与最佳实践
模型蒸馏原理及动手实践
模型评估方法和最佳实践
项目
场景
1、基于 Bert 的中文评价情感分析(分类任务) 2、定制化模型输出(生成任务) 3、基于特定数据集训练情绪对话模型
RAG工程化
Embedding Models嵌入模型原理
Vector Store向量存储
LlamaIndex框架深度应用
Dify LLMOps
RAG方案最佳实践
项目
场景
1、基于 DeepSeek + Dify 快速构建私有知识库 2、法律助手 - 基于 LlamaIndex + Chroma 构建法律条文助手
智能体原理深度剖析
强化学习
Dify Agent应用
LangGraph 框架深度学习
项目
场景
1、基于 Dify 快速构建智能体应用 2、基于 LangGraph 构建企业级复杂多代理应用
深入理解DeepSeek设计思想和训练过程
DeepSeek本地部署,多卡联合部署,vLLM多卡推理
DeepSeek微调训练/多卡训练
解锁
技能
掌握 DeepSeek 本地部署及企业落地场景
模态与多模态的概念
多模态机器学习与典型任务
本地私有化部署图文描述模型
本地私有化部署文生视频模型
本地部署 Llama-3.2-11B-Vision-Instruct-GGUF 实现视觉问答
解锁
技能
掌握多模态大模型解决典型任务:跨模态预训练/Language-Audio / Vision-Audio / Vision-Language/定位相关任务
Affect Computing 情感计算/Medical Image 医疗图像模态
多套高薪Offer的AI大模型简历分享及参考
简历项目1对1个性化指导
技术模拟面试1对1指导
解锁
技能
高效写出高含金量的AI技术简历 / 项目场景模拟面试
# 场景化深度落地实践,多重维度构建能力模型

* 基于LlamaIndex构建企业私有知识库(RAG项目)
* 基于Bert的中文评价情感分析(分类任务)
* 中文生成模型定制化(生成任务)
* 基于本地大模型的在线心理问诊系统(微调项目)
* 企业招标采购智能客服系统(RAG+微调项目)
* 基于YOLO的骨龄识别项目(视觉项目)
* 基于RAG的法律咨询智能助手
# 五大全方位闭环硬核服务,为你的学习和面试保驾护航
#### 大家说好,才是真的好
# 无论你是转行、进阶,都是你的不二之选
AI大模型工程师专注于LLM领域的工程师,渴望深入探索大模型的高级应用和解决方案设计。
NLP算法工程师寻求LLM实战经验,提升专业技能,增强大厂面试竞争力。
AI算法工程师希望迅速掌握LLM技术,实现职业转型或深化AI领域技能。
IT转行求职者对现有IT职业不满,寻求向AI领域转型的求职者,寻找技术转型的新起点,快速积累LLM实战经验。
在职提升者在职工程师,希望提升LLM技能,提高工作效率,为职业晋升打下坚实基础。
计算机应届毕业生计算机专业师生和应届毕业生,追求快速掌握LLM技能,增强就业竞争力。
# 学前技术储备
具备良好的编程能力,熟悉Python语言
了解机器学习和深度学习的基本概念
对大模型算法有初步的了解和兴趣
帮助与常见问题
Q:是否有基础要求?
掌握基本的 Python 编程技能即可学习。
Q:是否有详细的课程表?
有的哦,可以联系官方客服领取。
Q:上课形式和课时量是怎样的呢?
课程为全程直播。课时2个月左右
Q:直播是否有回看?
直播的录播视频会上传到官网方便大家回看,但为了更好的学习互动效果,建议各位学员提前预留好时间,准备好问题,准时参加直播。
Q: 课程录播视频的观看期限是多久?
一年有效学习权益
Q:可以跟老师互动交流吗?
当然啦,我们会建立班级社群,群内可以互动交流。同时,大家还可以通过直播向老师提问。
Q:报名缴费后可以退款吗?
付款后 3 个自然日内,如果觉得课程不适合自己,可申请退款,超出 3 个自然日,就不再办理退款啦。退款流程预计为 10 个工作日。
Q:可以分期付款吗?
我们支持花呗信用卡分期付款。
Q: 如何开发票,签合同?
我们可以为学员开具正规的发票和合同。开发票相关事宜,请联系带班班主任。合同相关事宜,请联系报名老师。
大厂标准培训
海量精品课程
汇聚优秀团队
打造完善体系
 

Copyright © 2023-2025 聚客AI 版权所有
网站备案号:[湘ICP备2024094305号-1](https://beian.miit.gov.cn/)
四、文本切分与解析
为方便检索,我们通常把 Document 切分为 Node。
在 LlamaIndex 中,Node 被定义为一个文本的「chunk」。
LlamaIndex 提供了丰富的 TextSplitter,例如:
- SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。底层用的embedding,做向量相似度切片。
4.1、使用 TextSplitters 对文本做(大小块、语义、代码)的切分
例如:TokenTextSplitter 按指定 token 数切分文本
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
from llama_cloud_services import LlamaParse
from llama_index.core import SimpleDirectoryReader
import nest_asyncio
import json
from pydantic.v1 import BaseModel
def show_json(data):
"""用于展示json数据"""
if isinstance(data, str):
obj = json.loads(data)
print(json.dumps(obj, indent=4, ensure_ascii=False))
elif isinstance(data, dict) or isinstance(data, list):
print(json.dumps(data, indent=4, ensure_ascii=False))
elif issubclass(type(data), BaseModel):
print(json.dumps(data.dict(), indent=4, ensure_ascii=False))
def show_list_obj(data):
"""用于展示一组对象"""
if isinstance(data, list):
for item in data:
show_json(item)
else:
raise ValueError("Input is not a list")
# set up parser
parser = LlamaParse(
result_type="markdown" , # "markdown" and "text" are available
api_key="your"
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(input_dir=r"G:\python_ws_g\code\RAG\data\txt", required_exts=[".txt"], file_extractor=file_extractor).load_data()
# print(documents[0].text)
node_parser = TokenTextSplitter(
chunk_size=512, # 每个 chunk 的最大长度
chunk_overlap=200 # chunk 之间重叠长度
)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=False
)
show_json(nodes[8].json())
# show_json(nodes[2].json())
4.2、使用 NodeParsers 对有结构的文档做解析(按照Html、md、json)
将读取的文档Document封装成Node节点(按照Html、md、json)
from llama_index.core.node_parser import HTMLNodeParser
from llama_index.readers.web import SimpleWebPageReader
documents = SimpleWebPageReader(html_to_text=False).load_data(
["https://edu.guangjuke.com/tx/"]
)
# 默认解析 ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"]
parser = HTMLNodeParser(tags=["span"]) # 可以自定义解析哪些标签
nodes = parser.get_nodes_from_documents(documents)
for node in nodes:
print(node.text+"\n")
更多的 NodeParser 包括 MarkdownNodeParser,JSONNodeParser等等。
五、索引、检索
**基础概念:**在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现不是本课程的教学重点,感兴趣的同学可以参考:传统索引、向量索引
5.1、向量检索
5.1.1 VectorStoreIndex 直接在内存中构建一个 Vector Store 并建索引 (可以传入Document、切块方式)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import TokenTextSplitter, SentenceSplitter
# 加载 pdf 文档
documents = SimpleDirectoryReader(
"./data",
required_exts=[".pdf"],
).load_data()
# 定义 Node Parser
node_parser = TokenTextSplitter(chunk_size=512, chunk_overlap=200)
# 切分文档
nodes = node_parser.get_nodes_from_documents(documents)
# 构建 index,默认是在内存中
index = VectorStoreIndex(nodes)
# 另外一种实现方式
# index = VectorStoreIndex.from_documents(documents=documents, transformations=[SentenceSplitter(chunk_size=512)])
# 写入本地文件
# index.storage_context.persist(persist_dir="./doc_emb")
# 获取 retriever
vector_retriever = index.as_retriever(
similarity_top_k=2 # 返回2个结果
)
# 检索
results = vector_retriever.retrieve("deepseek v3数学能力怎么样?")
print(results[0].text)
5.1.2 自定义的VectorStore(可以传入Document、切块方式、向量数据库qdrant、milvus、chromadb)
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
client = QdrantClient(location=":memory:")
collection_name = "demo"
collection = client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
# storage: 指定存储空间
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 创建 index:通过 Storage Context 关联到自定义的 Vector Store
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=1)
# 检索
results = vector_retriever.retrieve("deepseek v3数学能力怎么样")
print(results[0])
5.2、更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
-
关键字检索
BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法KeywordTableGPTRetriever:使用 GPT 提取检索关键字KeywordTableSimpleRetriever:使用正则表达式提取检索关键字KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
-
意图识别:RAG-Fusion
QueryFusionRetriever
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# 加载文档(你可以替换为你自己的劳动法文本)
documents = SimpleDirectoryReader("your_documents_folder").load_data()
# 文本分割
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# 向量索引
index = VectorStoreIndex(nodes)
# 构建基础 retriever
vector_retriever = index.as_retriever(similarity_top_k=3)
# 构建 QueryFusionRetriever
fusion_retriever = QueryFusionRetriever(
retriever=vector_retriever,
query_gen_llm=OpenAI(model="gpt-3.5-turbo"), # 可以替换为你自己的模型接口
num_queries=4 # 控制生成多少个意图(子查询)
)
# 构建 query engine
query_engine = RetrieverQueryEngine(retriever=fusion_retriever)
# 运行查询
response = query_engine.query("员工可以因为什么被公司开除?")
print(response)
- 还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
5.3、检索后处理(rerank)
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 Nodes 做重排序
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=5)
# 检索
nodes = vector_retriever.retrieve("deepseek v3有多少参数?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}\n")
from llama_index.core.postprocessor import LLMRerank
postprocessor = LLMRerank(top_n=2)
nodes = postprocessor.postprocess_nodes(nodes, query_str="deepseek v3有多少参数?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}")
Rerank官网参考:
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
六、生成回复(QA & Chat)
6.1 单轮问答(Query Engine)
qa_engine = index.as_query_engine()
response = qa_engine.query("deepseek v3数学能力怎么样?")
print(response)
流式输出
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("deepseek v3数学能力怎么样?")
response.print_response_stream()
DeepSeek-V3在数学相关基准测试中表现出色,特别是在非长链思维开放源码和闭源模型中处于领先地位。它在某些特定的基准测试,如MATH-500上,甚至超过了o1-preview的表现,这证明了其强大的数学推理能力。
6.2 多轮对话(Chat Engine)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("deepseek v3数学能力怎么样?")
print(response)
流式输出
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?")
# streaming_response.print_response_stream()
for token in streaming_response.response_gen:
print(token, end="", flush=True)
DeepSeek-V3在数学相关基准测试中表现出色,特别是在非长链思维开放源码和闭源模型中处于领先地位。它在某些特定的基准测试,如MATH-500上,甚至超过了o1-preview的表现,这证明了其强大的数学推理能力。
七、底层接口:Prompt、LLM 与 Embedding
7.1 Prompt 模板
PromptTemplate 定义提示词模板
from llama_index.core import PromptTemplate
prompt = PromptTemplate("写一个关于{topic}的笑话")
prompt.format(topic="小明")
ChatPromptTemplate 定义多轮消息模板
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplate
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="你叫{name},你必须根据用户提供的上下文回答问题。",
),
ChatMessage(
role=MessageRole.USER,
content=(
"已知上下文:\n" \
"{context}\n\n" \
"问题:{question}"
)
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
print(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="这是什么"
)
)
system: 你叫小明,你必须根据用户提供的上下文回答问题。
user: 已知上下文:
这是一个测试
问题:这是什么
assistant:
7.2 语言模型
from llama_index.llms.openai import OpenAI
llm = OpenAI(temperature=0, model="gpt-4o")
response = llm.complete(prompt.format(topic="小明"))
print(response.text)
response = llm.complete(
text_qa_template.format(
name="小明",
context="这是一个测试",
question="你是谁,我们在干嘛"
)
)
print(response.text)
连接DeepSeek
import os
from llama_index.llms.deepseek import DeepSeek
llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)
response = llm.complete("写个笑话")
print(response)
from llama_index.core import Settings
Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)
集成其他模型
除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations
7.3 Embedding 模型
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局设定
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)
八、 基于 LlamaIndex 实现一个功能较完整的 RAG 系统
功能要求:
- 加载指定目录的文件
- 支持 RAG-Fusion
- 使用 Qdrant 向量数据库,并持久化到本地
- 支持检索后排序
- 支持多轮对话
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
EMBEDDING_DIM = 1536
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"
client = QdrantClient(path=PATH)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizer
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import LLMRerank, SimilarityPostprocessor
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
# 1. 指定全局llm与embedding模型
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX,api_key=os.getenv("DASHSCOPE_API_KEY"))
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)
# 2. 指定全局文档处理的 Ingestion Pipeline
Settings.transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=200)]
# 3. 加载本地文档
documents = SimpleDirectoryReader("./data").load_data()
if client.collection_exists(collection_name=COLLECTION_NAME):
client.delete_collection(collection_name=COLLECTION_NAME)
# 4. 创建 collection
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 5. 创建 Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
# 6. 指定 Vector Store 的 Storage 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
# 7. 定义检索后排序模型
reranker = LLMRerank(top_n=2)
# 最终打分低于0.6的文档被过滤掉
sp = SimilarityPostprocessor(similarity_cutoff=0.6)
# 8. 定义 RAG Fusion 检索器
fusion_retriever = QueryFusionRetriever(
[index.as_retriever()],
similarity_top_k=5, # 检索召回 top k 结果
num_queries=3, # 生成 query 数
use_async=False,
# query_gen_prompt="", # 可以自定义 query 生成的 prompt 模板
)
# 9. 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker],
response_synthesizer=get_response_synthesizer(
response_mode = ResponseMode.REFINE
)
)
# 10. 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# condense_question_prompt="" # 可以自定义 chat message prompt 模板
)
# 测试多轮对话
# User: deepseek v3有多少参数
# User: 每次激活多少
while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")
AI: DeepSeek V3总共有671亿个参数。
AI: DeepSeek V3每次激活370亿个参数。
九、Text2SQL / NL2SQL / NL2Chart / ChatBI
9.1 基本介绍
Text2SQL 是一种将自然语言转换为SQL查询语句的技术。
这项技术的意义:让每个人都能像对话一样查询数据库,获取所需信息,而不必学习SQL语法。
9.2 典型应用场景
-
业务分析师的数据自助服务
-
智能BI与数据可视化
-
客服与内部数据库查询
-
跨部门数据协作与分享
-
运营数据分析与决策支持
9.3 Text2SQL核心能力与挑战
一个成熟的Text2SQL系统需要具备以下关键能力:
| 核心能力 | 说明 | 技术挑战 |
|---|---|---|
| 语义理解 | 理解用户真正的查询意图 | 处理歧义、上下文推断 |
| 数据库结构感知 | 了解表结构、字段关系 | 自动映射字段与实体 |
| 复杂查询构建 | 支持多表连接、聚合等 | 子查询、嵌套逻辑转换 |
| 上下文记忆 | 理解多轮对话中的指代 | 维护查询状态 |
| 错误处理 | 识别并修正错误输入 | 模糊匹配、容错机制 |
9.4 实现Text2SQL的技术架构
-
架构一:基于Workflow工作流方案
-
架构二:基于LangChain的数据库链方案
-
架构三:企业级解决方案
-
Vanna(开源)
- 官网:https://vanna.ai/
-
阿里云(商业)
-
腾讯云(商业)
- ChatBI产品 https://cloud.tencent.com/document/product/590/107689
-
十、工作流(WorkFlow)
10.1 工作流(Workflow)简介
工作流顾名思义是对一些列工作步骤的抽象。
LlamaIndex 的工作流是事件(event)驱动的:
- 工作流由
step组成 - 每个
step处理特定的事件 step也会产生新的事件(交由后继的step进行处理)- 直到产生
StopEvent整个工作流结束
LlamaIndex Workflows:https://docs.llamaindex.ai/en/stable/module_guides/workflow/
10.2 工作流设计
使用自然语言查询数据库,数据库中包含多张表
工作流设计:

分步说明:
- 用户输入自然语言查询
- 系统先去检索跟查询相关的表
- 根据表的 Schema 让大模型生成 SQL
- 用生成的 SQL 查询数据库
- 根据查询结果,调用大模型生成自然语言回复
10.3 数据准备
# 下载 WikiTableQuestions
# WikiTableQuestions 是一个为表格问答设计的数据集。其中包含 2,108 个从维基百科提取的 HTML 表格
# !wget "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip" -O wiki_data.zip
# !unzip wiki_data.zip
1.遍历目录加载表格
import pandas as pd
from pathlib import Path
data_dir = Path("./WikiTableQuestions/csv/200-csv")
csv_files = sorted([f for f in data_dir.glob("*.csv")])
dfs = []
for csv_file in csv_files:
print(f"processing file: {csv_file}")
try:
df = pd.read_csv(csv_file)
dfs.append(df)
except Exception as e:
print(f"Error parsing {csv_file}: {str(e)}")
processing file: WikiTableQuestions\csv\200-csv\0.csv
processing file: WikiTableQuestions\csv\200-csv\1.csv
processing file: WikiTableQuestions\csv\200-csv\10.csv
processing file: WikiTableQuestions\csv\200-csv\11.csv
processing file: WikiTableQuestions\csv\200-csv\12.csv
processing file: WikiTableQuestions\csv\200-csv\14.csv
processing file: WikiTableQuestions\csv\200-csv\15.csv
Error parsing WikiTableQuestions\csv\200-csv\15.csv: Error tokenizing data. C error: Expected 4 fields in line 16, saw 5
processing file: WikiTableQuestions\csv\200-csv\17.csv
Error parsing WikiTableQuestions\csv\200-csv\17.csv: Error tokenizing data. C error: Expected 6 fields in line 5, saw 7
processing file: WikiTableQuestions\csv\200-csv\18.csv
processing file: WikiTableQuestions\csv\200-csv\20.csv
processing file: WikiTableQuestions\csv\200-csv\22.csv
processing file: WikiTableQuestions\csv\200-csv\24.csv
processing file: WikiTableQuestions\csv\200-csv\25.csv
processing file: WikiTableQuestions\csv\200-csv\26.csv
processing file: WikiTableQuestions\csv\200-csv\28.csv
processing file: WikiTableQuestions\csv\200-csv\29.csv
processing file: WikiTableQuestions\csv\200-csv\3.csv
processing file: WikiTableQuestions\csv\200-csv\30.csv
processing file: WikiTableQuestions\csv\200-csv\31.csv
processing file: WikiTableQuestions\csv\200-csv\32.csv
processing file: WikiTableQuestions\csv\200-csv\33.csv
...
processing file: WikiTableQuestions\csv\200-csv\48.csv
processing file: WikiTableQuestions\csv\200-csv\7.csv
processing file: WikiTableQuestions\csv\200-csv\8.csv
processing file: WikiTableQuestions\csv\200-csv\9.csv
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
2.为每个表生成一段文字表述(用于检索),保存在 WikiTableQuestions_TableInfo 目录
from llama_index.core.prompts import ChatPromptTemplate
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.core.llms import ChatMessage
class TableInfo(BaseModel):
"""Information regarding a structured table."""
table_name: str = Field(
..., description="table name (must be underscores and NO spaces)"
)
table_summary: str = Field(
..., description="short, concise summary/caption of the table"
)
prompt_str = """
Give me a summary of the table with the following JSON format.
- The table name must be unique to the table and describe it while being concise.
- Do NOT output a generic table name (e.g. table, my_table).
Do NOT make the table name one of the following: {exclude_table_name_list}
Table:
{table_str}
Summary: """
prompt_tmpl = ChatPromptTemplate(
message_templates=[ChatMessage.from_str(prompt_str, role="user")]
)
tableinfo_dir = "WikiTableQuestions_TableInfo"
# !mkdir {tableinfo_dir}
import json
def _get_tableinfo_with_index(idx: int) -> str:
results_gen = Path(tableinfo_dir).glob(f"{idx}_*")
results_list = list(results_gen)
if len(results_list) == 0:
return None
elif len(results_list) == 1:
path = results_list[0]
with open(path, 'r') as file:
data = json.load(file)
return TableInfo.model_validate(data)
else:
raise ValueError(
f"More than one file matching index: {list(results_gen)}"
)
table_names = set()
table_infos = []
for idx, df in enumerate(dfs):
table_info = _get_tableinfo_with_index(idx)
if table_info:
table_infos.append(table_info)
else:
while True:
df_str = df.head(10).to_csv()
table_info = llm.structured_predict(
TableInfo,
prompt_tmpl,
table_str=df_str,
exclude_table_name_list=str(list(table_names)),
)
table_name = table_info.table_name
print(f"Processed table: {table_name}")
if table_name not in table_names:
table_names.add(table_name)
break
else:
# try again
print(f"Table name {table_name} already exists, trying again.")
pass
out_file = f"{tableinfo_dir}/{idx}_{table_name}.json"
json.dump(table_info.dict(), open(out_file, "w"))
table_infos.append(table_info)
3.将上述表格存入 SQLite 数据库
# put data into sqlite db
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
)
import re
# Function to create a sanitized column name
def sanitize_column_name(col_name):
# Remove special characters and replace spaces with underscores
return re.sub(r"\W+", "_", col_name)
# Function to create a table from a DataFrame using SQLAlchemy
def create_table_from_dataframe(df: pd.DataFrame, table_name: str, engine, metadata_obj):
# Sanitize column names
sanitized_columns = {col: sanitize_column_name(col) for col in df.columns}
df = df.rename(columns=sanitized_columns)
# Dynamically create columns based on DataFrame columns and data types
columns = [
Column(col, String if dtype == "object" else Integer)
for col, dtype in zip(df.columns, df.dtypes)
]
# Create a table with the defined columns
table = Table(table_name, metadata_obj, *columns)
# Create the table in the database
metadata_obj.create_all(engine)
# Insert data from DataFrame into the table
with engine.connect() as conn:
for _, row in df.iterrows():
insert_stmt = table.insert().values(**row.to_dict())
conn.execute(insert_stmt)
conn.commit()
# engine = create_engine("sqlite:///:memory:")
engine = create_engine("sqlite:///wiki_table_questions.db")
metadata_obj = MetaData()
for idx, df in enumerate(dfs):
tableinfo = _get_tableinfo_with_index(idx)
print(f"Creating table: {tableinfo.table_name}")
create_table_from_dataframe(df, tableinfo.table_name, engine, metadata_obj)
10.4 构建基础工具
10.4.1 创建基于表的描述的向量索引
- ObjectIndex 是一个 LlamaIndex 内置的模块,通过索引 (Index)检索任意 Python 对象
- 这里我们使用 VectorStoreIndex 也就是向量检索,并通过 SQLTableNodeMapping 将文本描述的 node 和数据库的表形成映射
- 相关文档:https://docs.llamaindex.ai/en/stable/examples/objects/object_index/#the-objectindex-class
import os
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
from llama_index.core.objects import (
SQLTableNodeMapping,
ObjectIndex,
SQLTableSchema,
)
from llama_index.core import SQLDatabase, VectorStoreIndex
# 设置全局模型
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)
sql_database = SQLDatabase(engine)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)
for t in table_infos
] # add a SQLTableSchema for each table
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
10.4.2 创建 SQL 查询器
from llama_index.core.retrievers import SQLRetriever
from typing import List
sql_retriever = SQLRetriever(sql_database)
def get_table_context_str(table_schema_objs: List[SQLTableSchema]):
"""Get table context string."""
context_strs = []
for table_schema_obj in table_schema_objs:
table_info = sql_database.get_single_table_info(
table_schema_obj.table_name
)
if table_schema_obj.context_str:
table_opt_context = " The table description is: "
table_opt_context += table_schema_obj.context_str
table_info += table_opt_context
context_strs.append(table_info)
return "\n\n".join(context_strs)
10.4.3 创建 Text2SQL 的提示词(系统默认模板),和输出结果解析器(从生成的文本中抽取SQL)
from llama_index.core.prompts.default_prompts import DEFAULT_TEXT_TO_SQL_PROMPT
from llama_index.core import PromptTemplate
from llama_index.core.llms import ChatResponse
def parse_response_to_sql(chat_response: ChatResponse) -> str:
"""Parse response to SQL."""
response = chat_response.message.content
sql_query_start = response.find("SQLQuery:")
if sql_query_start != -1:
response = response[sql_query_start:]
# TODO: move to removeprefix after Python 3.9+
if response.startswith("SQLQuery:"):
response = response[len("SQLQuery:") :]
sql_result_start = response.find("SQLResult:")
if sql_result_start != -1:
response = response[:sql_result_start]
return response.strip().strip("```").strip()
text2sql_prompt = DEFAULT_TEXT_TO_SQL_PROMPT.partial_format(
dialect=engine.dialect.name
)
print(text2sql_prompt.template)
10.4.4 创建自然语言回复生成模板
response_synthesis_prompt_str = (
"Given an input question, synthesize a response from the query results.\n"
"Query: {query_str}\n"
"SQL: {sql_query}\n"
"SQL Response: {context_str}\n"
"Response: "
)
response_synthesis_prompt = PromptTemplate(
response_synthesis_prompt_str,
)
llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
10.4.5 定义工作流
from llama_index.core.workflow import (
Workflow,
StartEvent,
StopEvent,
step,
Context,
Event,
)
# 事件:找到数据库中相关的表
class TableRetrieveEvent(Event):
"""Result of running table retrieval."""
table_context_str: str
query: str
# 事件:文本转 SQL
class TextToSQLEvent(Event):
"""Text-to-SQL event."""
sql: str
query: str
class TextToSQLWorkflow1(Workflow):
"""Text-to-SQL Workflow that does query-time table retrieval."""
def __init__(
self,
obj_retriever,
text2sql_prompt,
sql_retriever,
response_synthesis_prompt,
llm,
*args,
**kwargs
) -> None:
"""Init params."""
super().__init__(*args, **kwargs)
self.obj_retriever = obj_retriever
self.text2sql_prompt = text2sql_prompt
self.sql_retriever = sql_retriever
self.response_synthesis_prompt = response_synthesis_prompt
self.llm = llm
@step
def retrieve_tables(
self, ctx: Context, ev: StartEvent
) -> TableRetrieveEvent:
"""Retrieve tables."""
table_schema_objs = self.obj_retriever.retrieve(ev.query)
table_context_str = get_table_context_str(table_schema_objs)
print("====\n"+table_context_str+"\n====")
return TableRetrieveEvent(
table_context_str=table_context_str, query=ev.query
)
@step
def generate_sql(
self, ctx: Context, ev: TableRetrieveEvent
) -> TextToSQLEvent:
"""Generate SQL statement."""
fmt_messages = self.text2sql_prompt.format_messages(
query_str=ev.query, schema=ev.table_context_str
)
chat_response = self.llm.chat(fmt_messages)
sql = parse_response_to_sql(chat_response)
print("====\n"+sql+"\n====")
return TextToSQLEvent(sql=sql, query=ev.query)
@step
def generate_response(self, ctx: Context, ev: TextToSQLEvent) -> StopEvent:
"""Run SQL retrieval and generate response."""
retrieved_rows = self.sql_retriever.retrieve(ev.sql)
print("====\n"+str(retrieved_rows)+"\n====")
fmt_messages = self.response_synthesis_prompt.format_messages(
sql_query=ev.sql,
context_str=str(retrieved_rows),
query_str=ev.query,
)
chat_response = llm.chat(fmt_messages)
return StopEvent(result=chat_response)
workflow = TextToSQLWorkflow1(
obj_retriever,
text2sql_prompt,
sql_retriever,
response_synthesis_prompt,
llm,
verbose=True,
)
response = await workflow.run(
query="What was the year that The Notorious B.I.G was signed to Bad Boy?"
)
print(str(response))
10.4.6 可视化工作流
# !pip install llama-index-utils-workflow
from llama_index.utils.workflow import draw_all_possible_flows
draw_all_possible_flows(
TextToSQLWorkflow1, filename="text_to_sql_table_retrieval.html"
)
十一、响应合成器
合成(synthesize)阶段的响应合成器(response synthesizer)会引导LLM生成响应,将用户查询与检索到的文本块混合在一起,并给出一个精心设计的答案。
LlamaIndex官方为我们提供了多种响应合成器:
- Refine: 这种方法遍历每一段文本,一点一点地精炼答案。
- Compact: 是Refine的精简版。它将文本集中在一起,因此需要处理的步骤更少。
- Tree Summarize: 想象一下,把许多小的答案结合起来,再总结,直到你得到一个主要的答案。
- Simple Summarize: 只是把文本片段剪短,然后给出一个快速的总结。
- No Text: 这个问题不会给你答案,但会告诉你它会使用哪些文本。
- Accumulate: 为每一篇文章找一堆小答案,然后把它们粘在一起。
- Compact Accumulate: 是“Compact”和“Accumulate”的合成词。
现在,我们选择一种retriever和一种response synthesizer。retriever选择SimilarityPostprocessor,response synthesizer选择Refine。
import logging
import sys
import torch
from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex, get_response_synthesizer
from llama_index.core.callbacks import LlamaDebugHandler, CallbackManager
from llama_index.core.indices.vector_store import VectorIndexRetriever
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
# 定义日志
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 定义system prompt
SYSTEM_PROMPT = """You are a helpful AI assistant."""
query_wrapper_prompt = PromptTemplate(
"[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)
# 使用 llama_index_llms_huggingface 调用本地大模型
Settings.llm = HuggingFaceLLM(
context_window = 4096,
max_new_tokens = 2048,
generate_kwargs = {"temperature": 0.0, "do_sample": False},
query_wrapper_prompt = query_wrapper_prompt,
tokenizer_name = "/home/kevin/projects/models/Qwen/Qwen1.5-7B-Chat",
model_name = "/home/kevin/projects/models/Qwen/Qwen1.5-7B-Chat",
device_map = "auto",
model_kwargs = {"torch_dtype": torch.float16},
)
# 使用LlamaDebugHandler构建事件回溯器,以追踪LlamaIndex执行过程中发生的事件
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
Settings.callback_manager = callback_manager
# 使用llama-index-embeddings-huggingface构建本地embedding模型
Settings.embed_model = HuggingFaceEmbedding(
model_name="/home/kevin/projects/models/BAAI/bge-base-zh-v1.5"
)
# 读取文档并构建索引
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
# 构建retriever
retriever = VectorIndexRetriever(
index = index,
similarity_top_k = 5,
)
# 构建response synthesizer
response_synthesizer = get_response_synthesizer(
response_mode = ResponseMode.REFINE
)
# 构建查询引擎
query_engine = RetrieverQueryEngine(
retriever = retriever,
response_synthesizer = response_synthesizer,
node_postprocessors = [SimilarityPostprocessor(similarity_cutoff=0.6)]
)
# 查询获得答案
response = query_engine.query("不耐疲劳,口燥、咽干可能是哪些证候?")
print(response)
# get_llm_inputs_outputs返回每个LLM调用的开始/结束事件
event_pairs = llama_debug.get_llm_inputs_outputs()
print(event_pairs[0][1].payload["formatted_prompt"])

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









