







Transformer 发展历史
以下是 Transformer 模型(简短)历史中的一些参考点:
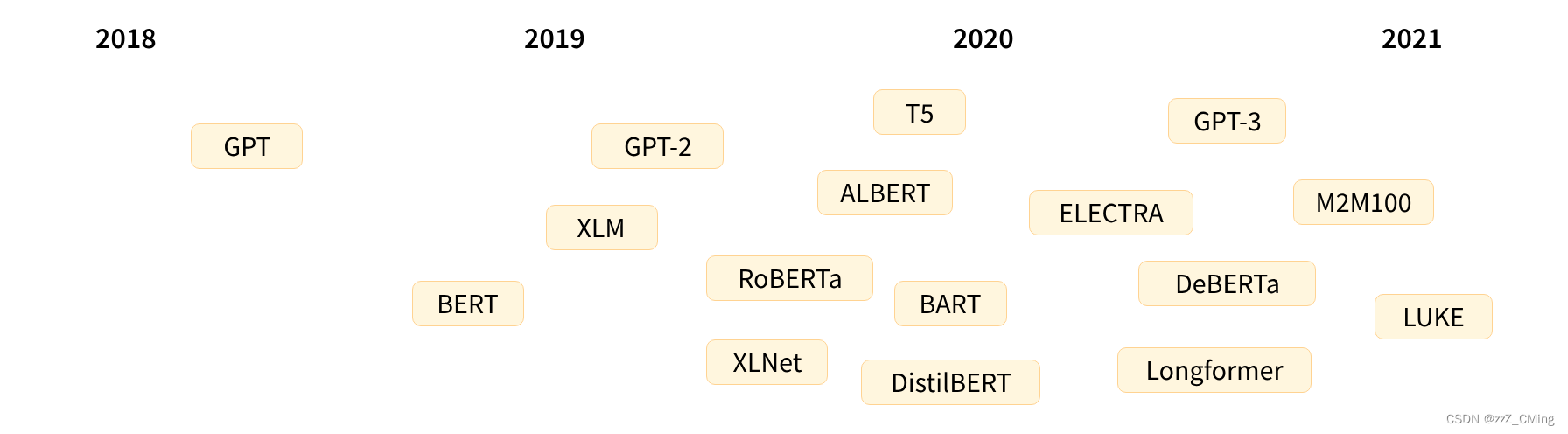
Transformer 架构于2017 年 6 月推出。最初的研究重点是翻译任务。随后推出了几个有影响力的模型,包括:
- 2018年6月:GPT,第一个预训练的Transformer模型,用于各种NLP任务的微调并获得了SOTA的结果;
- 2018 年10月:BERT,另一个大型预训练模型,旨在生成更好的句子摘要;
- 2019年2月:GPT-2,GPT 的改进(和更大)版本,由于道德问题没有立即公开发布;
- 2019年10月:DistilBERT,BERT 的精炼版,速度提高了 60%,内存减少了 40%,但仍然保留了 BERT 97% 的性能;
- 2019年10月:BART、T5,两个大型预训练模型,使用与原始 Transformer 模型相同的架构;
- 2020年5月:GPT-3,GPT-2的更大版本,能够在各种任务上表现良好,无需微调(称为zero-shot零样本学习)
这个列表远非全面,只是为了强调一些不同类型的 Transformer 模型。概括地说,它们可以分为三类:
- 类似 BERT,自编码模型,注意力层都可以访问初始句子中的所有单词。预测文本随机掩码。
- 类似 GPT,自回归模型,注意力层只能访问句子中位于该单词之前的单词。(自左向右或自右向左的、预测上/下一个单词语言模型)
- 类似 BART/T5,也称为序列到序列Transformer 模型。
然而,没有任何一个架构能在三个主流NLP任务上都达到最好(自然语言理解、无条件生成、条件生成)
Transformer架构
2017年之前,NLP领域的Encoder-Decoder架构的计算核多由一个或多个循环网络(RNN、LSTM)单元构成,这样的架构存在两个问题:
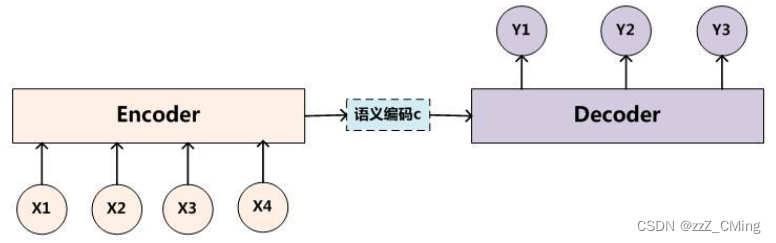
- 不能进行并行计算:循环网络是顺序结构,必须等待上一时刻完成才能开展下一时刻的计算,导致模型不能进行并行计算;
- 超长序列关系微弱:对于超长序列,前后间隔过远的数据之间的联系很难建立。就文本问题,当前时刻可能受过往N个时刻的影响,而循环网络只对较近时刻信息保持敏感,对较远时刻信息很难提取关联。
2017年谷歌发表论文《Attention Is All You Need》,就序列问题(机器翻译、语言模型)继续沿用Encoder-Decoder的经典架构,但是将计算核由循环网络改进为Transformer网络架构,这是Transformer网络架构的首次应用,便在序列问题上超越了之前RNN、LSTM等网络,取得更好的结果表现。
1、Transformer的整体结构
整体还是Encoder-Decoder,只是计算核由神经网络变为Transformer处理。其中Multi-Head Attention(多头注意力)层中的Self-Attention(自注意力)机制是Transformer 架构中重要的部分。
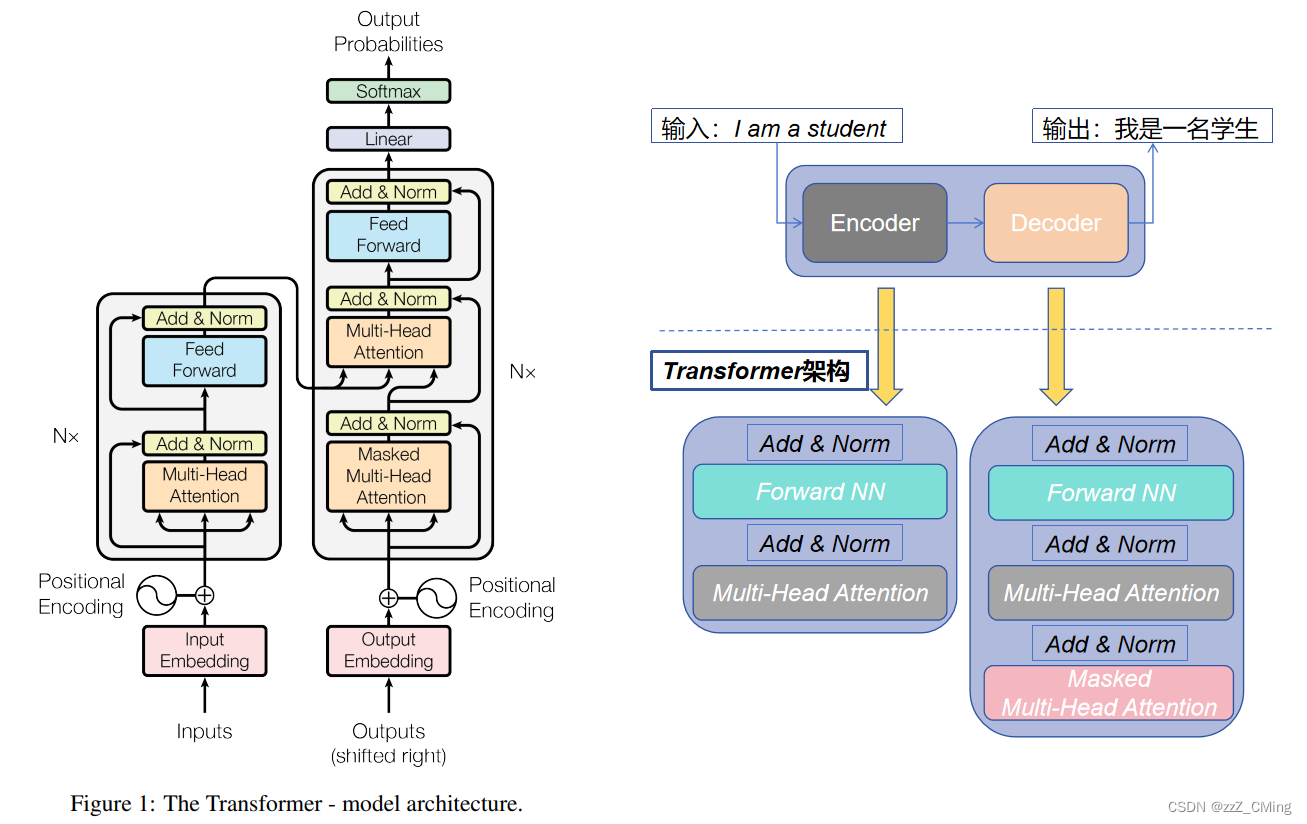
- 左侧是编码器Encoder Block,右侧是解码器Decoder Block;
- 编码器Encoder block有四个部分:多头注意力层MHA + 残差归一化层Add & Norm、多层感知层FNN + 残差归一化层Add & Norm;
- 解码器Decoder block有六个部分:掩码多头注意力层Masked MHA + 残差归一化层Add & Norm + 编码器Encoder block四部分
1.1、结构图示
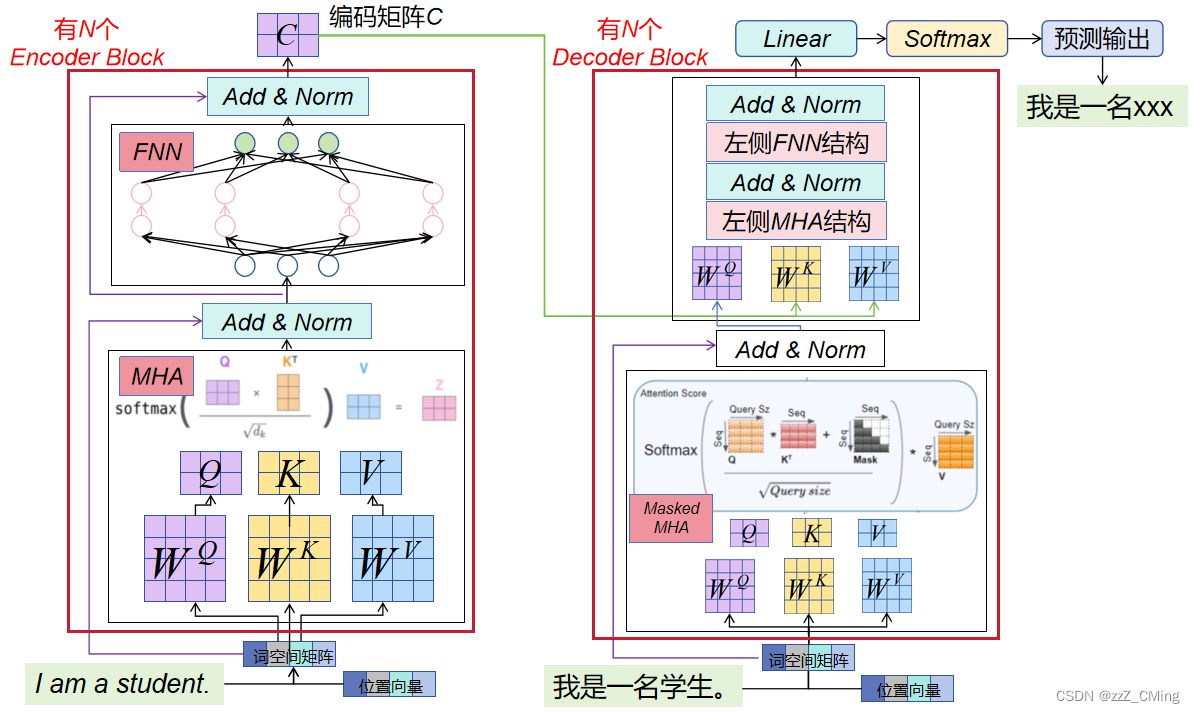
- 左侧是编码器Encoder,右侧是解码器Decoder;
- "I am a student."是输入值,"我是一名学生。"是标签值;
- 输入值经过Encoder Block过程,得到编码矩阵C;编码矩阵C参与Decoder Block 中K、V矩阵的生成;
- 标签值在Decoder Block过程中先经过Masked Multi-Head Attention层,得到的输出参与后续Q矩阵的生成;
- Decoder Block过程的输出再经过Linear层、Softmax层得到预测输出;
1.2、任务分类
编码器,解码器各自的作用:
- 编码器Encoder:接收输入并构建其表示(特征),编码器模型从输入中获取理解;
- 解码器Decoder:使用编码器的表示(特征)以及其他输入来生成目标序列,解码器模型主要是生成输出;
编码器和解码器都可以独立使用,具体取决于任务:
- 自编码模型:仅使用 Transformer 的编码器Encoder,注意力层都可以访问初始句子中的所有单词,适用于需要理解输入的任务,例如句子分类、命名实体识别。代表有BERT;
- 自回归模型:仅使用 Transformer 的解码器Decoder,注意力层只能访问句子中位于该单词之前的单词,适用于文本生成等任务。代表有:GPT;
- Encoder-Decoder模型、序列到序列模型:使用 Transformer 架构的两个部分,适用于需要输入的生成任务,例如翻译或摘要。代表有:BART、T5;

2、Transformer的数据流转
2.1、预处理过程:建立词空间矩阵X(n,d)
输入句子,获取句子中每个单词的词向量text embedding、位置向量path embedding,词向量 + 位置向量经过映射得到词空间向量,词空间向量组合形成词空间矩阵X(n,d)。(n表示句子中单词的个数,d 表示词向量的维度,每一行代表一个词)
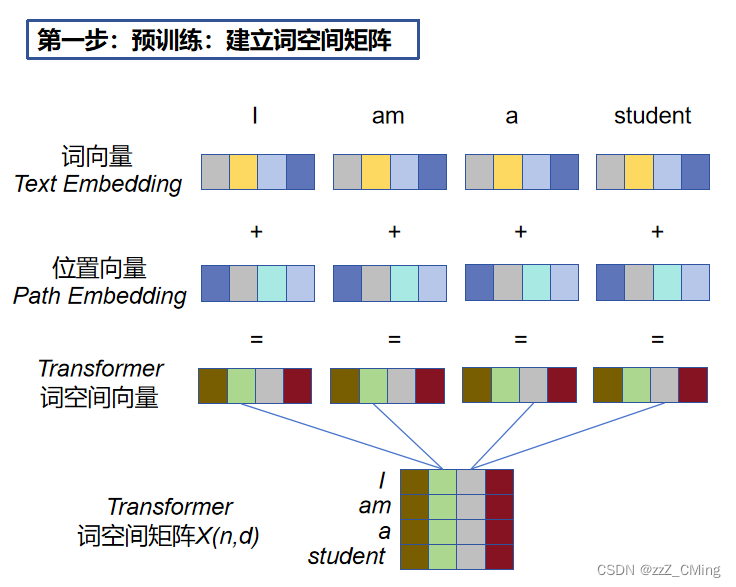
- 词向量 text embedding:有多种方式获取,可用 Word2Vec、Glove 等算法预训练得到,也可以在Transformer中训练得到;
- 位置向量path embedding:位置向量对于NLP来说非常重要。循环网络可直接通过单词的顺序输入得到单词的位置关系,而Transformer 由于不采用循环网络的结构,所以需要额外补充位置向量path embedding,用于保存单词在序列中的相对或绝对位置;
- 词空间向量:是词向量text Embedding 和位置向量path embedding经过映射后得到的,词空间向量也是Transformer的输入;(默许位置向量的作用后可粗略认为:词向量=词空间向量)
- 词空间矩阵X(n,d):由词空间向量联立而成,每一行代表一个词空间向量;
2.2、编码过程:生成编码矩阵C
将得到的词空间矩阵X(n,d)传入Encoder 过程中,Encoder过程经过N轮Encoder Block编码后生成编码矩阵C。如下图。
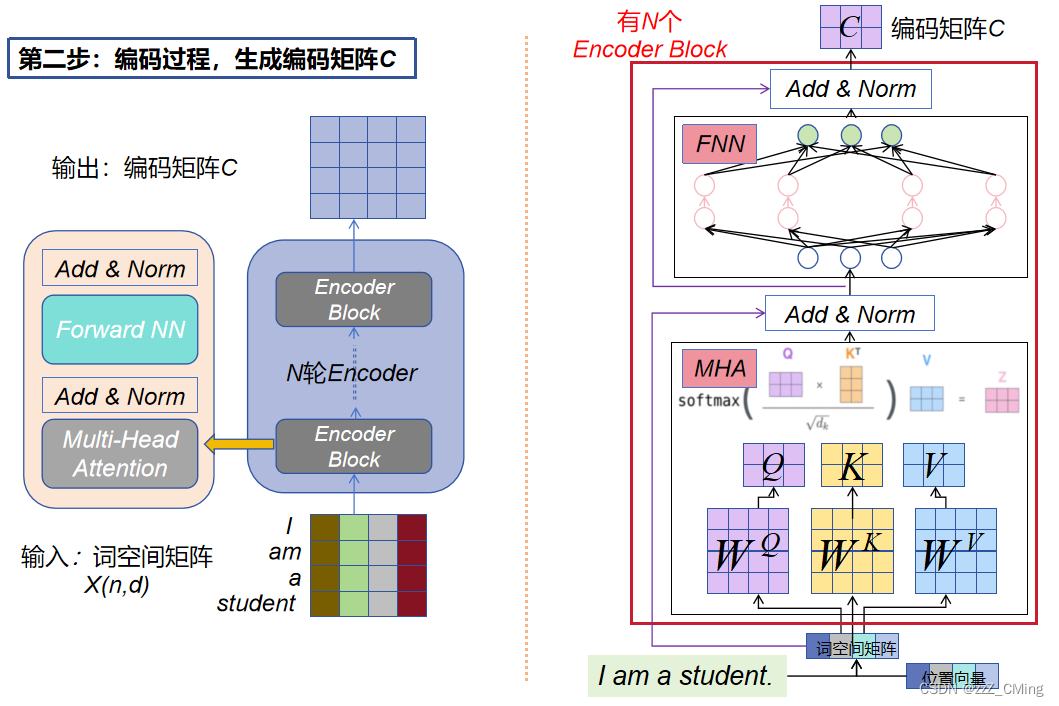
- 每个Encoder block都包含四个部分:MHA + Add & Norm、FNN + Add & Norm;
- MHA + Add & Norm:多头注意力层 + 残差连接 & 归一化;
- FNN + Add & Norm:前馈网络层 + 残差连接 & 归一化
每一个Encoder block输入、输出的矩阵维度都完全一致。(待求证)
2.3、解码过程:Mask掩码预测
- Masked Multi-Head Attention 掩码多头:在第 i 次解码预测中,会Mask掩盖住标签值 i 之后所有的单词用于预测第 i 位的词。
(预测词与真实标签值在词空间上构建损失loss,进行梯度更新训练。)
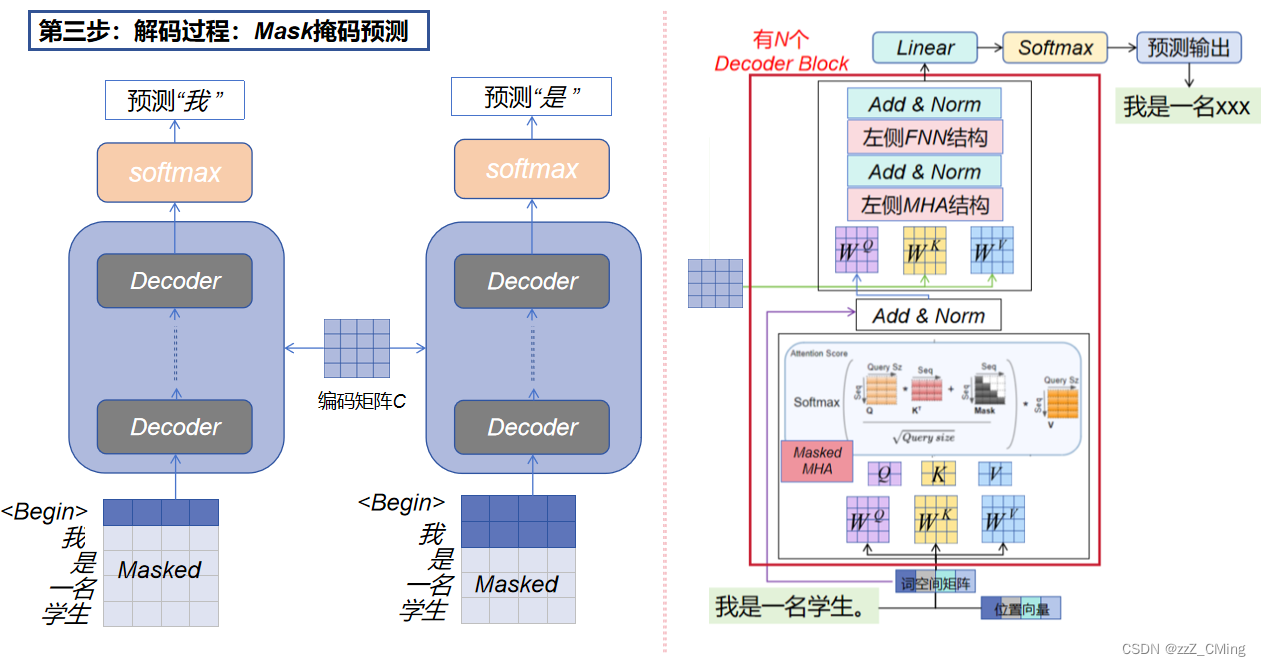
具体的掩码过程:
- 第一次解码标签值矩阵向Decoder 中传入起始符Begin,同时掩盖住Begin后所有的词向量,经过掩码多头(Masked MHA)得到的注意力值,参与后续Q矩阵的计算;
- 编码矩阵C传入Decoder 中,参与K,V 矩阵的计算;
- 得到的Q,K,V 矩阵完成后续的MHA、FNN、Linear、Softmax计算,得到第一次预测值“我”;
- 重复1234,注意掩码位置的变换,直至标签值矩阵预测结束;
3、Self-Attention原理说明
论文《Attention Is All You Need》中公布的Transformer示意图整体还是Encoder-Decoder结构。其中Multi-Head Attention(多头注意力)层中的Self-Attention(自注意力)机制是Transformer 架构中重要的部分。
- 左侧是Encoder过程,包含一个Multi-Head Attention(多头注意力)层,
- 右侧是Decoder过程,包含两个Multi-Head Attention(多头注意力)层,其中一个是用在Masked中。
- Add & Norm 层:Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm表示 Layer Normalization,用于对每一层的激活值进行归一化;
- Feed Forward层:前馈网络层,包含两个全连接层,第一层激活函数为ReLU函数,第二层无激活函数,表达式为: F N N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FNN(x)=max(0,xW_1 + b_1)W_2 + b_2 FNN(x)=max(0,xW1+b1)W2+b2
3.1、Attention的计算公式
右边的 Multi-Head Attention (多头注意力)层包含了多个左边Self-Attention 的计算过程。
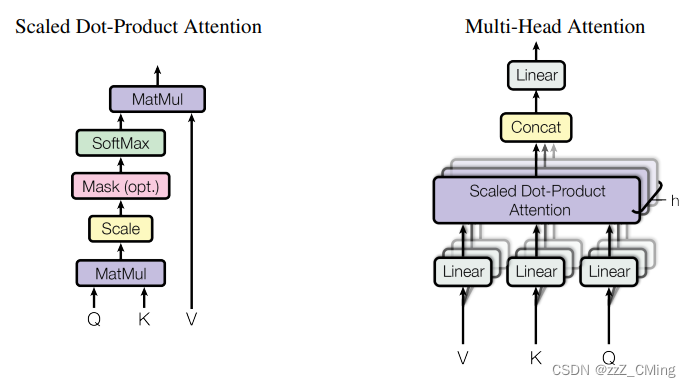
先看左边 Self-Attention的计算图,计算公式为: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⋅ K T d k ) V Attention(Q,K,V)=softmax(\frac{Q·K^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQ⋅KT)V(Q与K的转置做内积,再除以K的维度,经过softmax归一化,最后与V相乘。Q,K,V 皆为矩阵)。经过Self-Attention结构,最后得到的输出被叫做注意力分数。
- Q:querys,查询矩阵
- K:keys,键值矩阵
- V:values,数值矩阵
实际中,Self-Attention接收的输入分两种——词空间矩阵X(n,d),或者上一个Encoder/Decoder block的输出,这两种方式传递的都是词向量 X X X。而 Q, K, V 矩阵都是词向量 X X X进行线性变换后得到的,本质上只是词向量 X X X的变相表达。
3.2、Q,K,V 矩阵的由来
W
Q
、
W
K
、
W
V
W^Q、W^K、W^V
WQ、WK、WV就是词向量
X
X
X做线性变换所用到的参数,它们随机生成并参与梯度训练。

既然Q,K,V 等价于词向量
X
X
X,那为什么不直接使用词向量
X
X
X参与后续运算呢?求取Q,K,V矩阵的意义是什么呢?
答:是为了提升模型的拟合能力。矩阵
W
Q
、
W
K
、
W
V
W^Q、W^K、W^V
WQ、WK、WV是可以变化的,能逼近词向量
X
X
X在某一维度上的边界,相当于是求取词向量
X
X
X的“三视图”。
3.3、注意力分数的意义
上文已经知道注意力分数 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⋅ K T d k ) V Attention(Q,K,V)=softmax(\frac{Q·K^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQ⋅KT)V,其中Q, K, V 是词向量 X X X的线性变换,线性变换只改变外在,不改变实质,所以极限情况可以使Q = K = V = X ,那么计算公式就可以简化为: A t t e n t i o n ( X ) = s o f t m a x ( X ⋅ X T ) X Attention(X)=softmax(X·X^T)X Attention(X)=softmax(X⋅XT)X。这样就方便研究注意力分数的实际意义了。
①、 X ⋅ X T X·X^T X⋅XT的意义,一个矩阵乘以它自身的转置,有什么意义?会得到什么结果?
矩阵是由一个个向量组成,一个矩阵乘以它自身的转置,可以看成其向量分别与其他向量计算内积,内积的几何意义是:表征两个向量的夹角,表征一个向量在另一个向量上的投影大小。我们知道:
- 内积越大,说明投影越大,两者相关性越强;
- 内积等于0,说明两者的向量夹角等于九十度,这两个向量线性无关,完全没有相关性。
下图模拟
X
⋅
X
T
X·X^T
X⋅XT的计算过程:
词向量 “早(12121)” 分别与 “早、上、好” 做内积,得到一个新向量(11,11,10),新向量数值代表相关性大小;
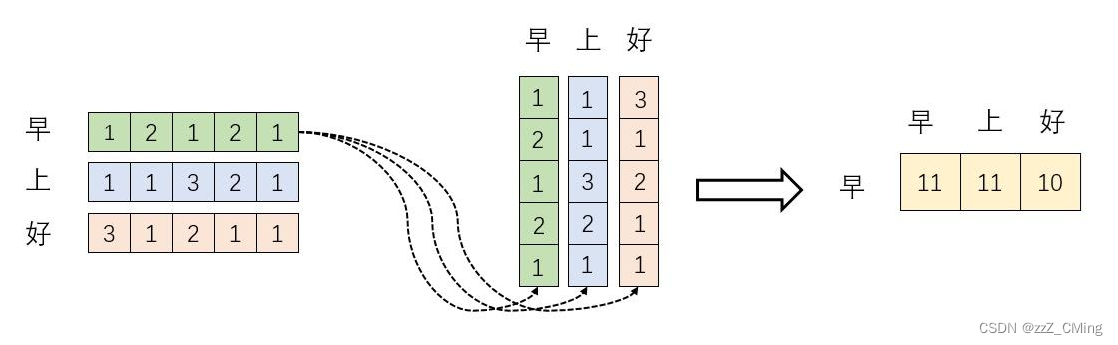
所以:词向量在高维空间做内积得到投影值,投影值越大,说明这两个词的相关性越强,进而在一定程度上说明,在关注词A的同时,也应当给予词B更多的关注;
②、
s
o
f
t
m
a
x
(
X
⋅
X
T
)
softmax(X·X^T)
softmax(X⋅XT)的意义
Self-Attention 翻译为“自注意力”,其本质是依赖词空间
X
(
n
,
d
)
X(n,d)
X(n,d)让每个词向量
X
i
X_i
Xi都能由其他词向量
X
n
X_n
Xn联合表示,联合表示的方法就是进行加权求和,这个“权重”就是上面所求的相关性。而
s
o
f
t
m
a
x
(
)
softmax()
softmax()的意义就是将相关性数值转化成分式表达。
例如下图:
当我们关注"早"这个字的时候,我们应当分配 0.4 的注意力给它本身,0.4 的注意力给"上",0.2 的注意力给"好"。
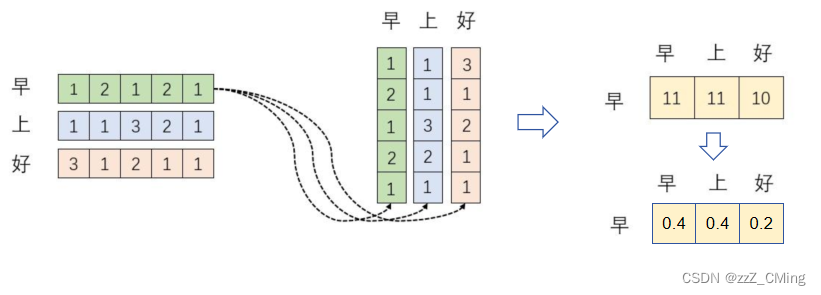
③、 s o f t m a x ( X ⋅ X T ) X softmax(X·X^T)X softmax(X⋅XT)X的意义
上面的计算,已经求取了联合表示的参数,最后再乘上矩阵X,就完成了所有词向量 X X X经过注意力机制加权后,在词空间上的联合表示方法。
例如下图:词向量 “早(12121)” 的权重是 ( 0.4 , 0.4 , 0.2 ) (0.4,0.4,0.2) (0.4,0.4,0.2),与矩阵的每一列相乘,实际是将词向量"早(12121)“每一位进行转化,每一位都用"早、上、好” 联合表示,进而将 "早(12121)"转化成新向量,新向量维度不变,将孤立的词转化成“你中有我,我中有你”的联合表示形式。这个联合表示形式就是Self-Attention的输出,也被叫做注意力分数。

总结:
- X ⋅ X T X·X^T X⋅XT的意义:词空间中,任意两个词向量的相关性大小;
- s o f t m a x ( X ⋅ X T ) softmax(X·X^T) softmax(X⋅XT)的意义:将相关性转化成联合参数;
- s o f t m a x ( X ⋅ X T ) X softmax(X·X^T)X softmax(X⋅XT)X的意义:用联合参数,将每一个词向量都转为联合表达的形式。这就是注意力分数的意义。
补充: d k \sqrt{d_k} dk的意义

3.4、Multi-Head Attention 多头
在多头注意力下,每组注意力单独维护不同的Q, K, V 矩阵。
例如:8组线性变化参数 W ( Q , K , V ) W(Q,K,V) W(Q,K,V)得到8组(Q, K, V )矩阵,进而得到8组注意力 Z ( Z 0 , Z 1 , . . , Z 7 ) Z(Z_0,Z_1,..,Z_7) Z(Z0,Z1,..,Z7)。
- 将8组注意力 ( Z 0 , Z 1 , . . , Z 7 ) (Z_0,Z_1,..,Z_7) (Z0,Z1,..,Z7)拼接起来;
- 将拼接后的矩阵,与一个权值矩阵 W O W^O WO相乘;
- 得到最终的多头分数 Z Z Z,( Z Z Z中包含了所有注意力头的信息),最后输入 F N N FNN FNN中。
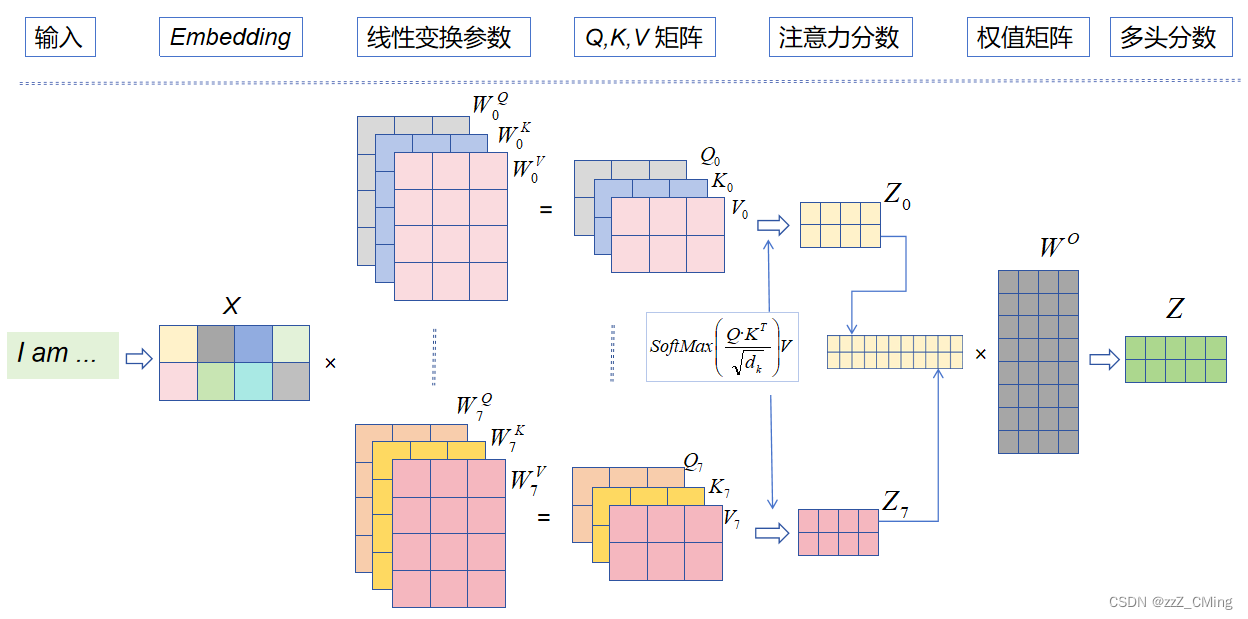
多头注意力层的计算公式:

多头注意力层的实质:
Multi-Head Attention实际寻找了输入序列不同角度的关联关系,经过拼接后,将不同子空间捕捉到的关联关系再综合起来,得到更高维度的连接。
3.5、Masked Multi-Head Attention 掩码多头
掩码多头(Masked Multi-Head Attention )只存在于Decoder过程中,
- 掩码多头的输入:标签值对应的词向量矩阵;
- 掩码多头的输出:也是注意力分数,与普通多头的区别在于会添加额外的掩码操作,使注意力只包含前序词语的影响。(掩码多头的输出,用于后续Q 矩阵的计算)
我们知道Self-Attention的计算公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
⋅
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{Q·K^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQ⋅KT)V,而掩码多头Masked Multi-Head Attention 就是在
s
o
f
t
m
a
x
(
)
softmax()
softmax()之前,添加一层Mask掩码操作。
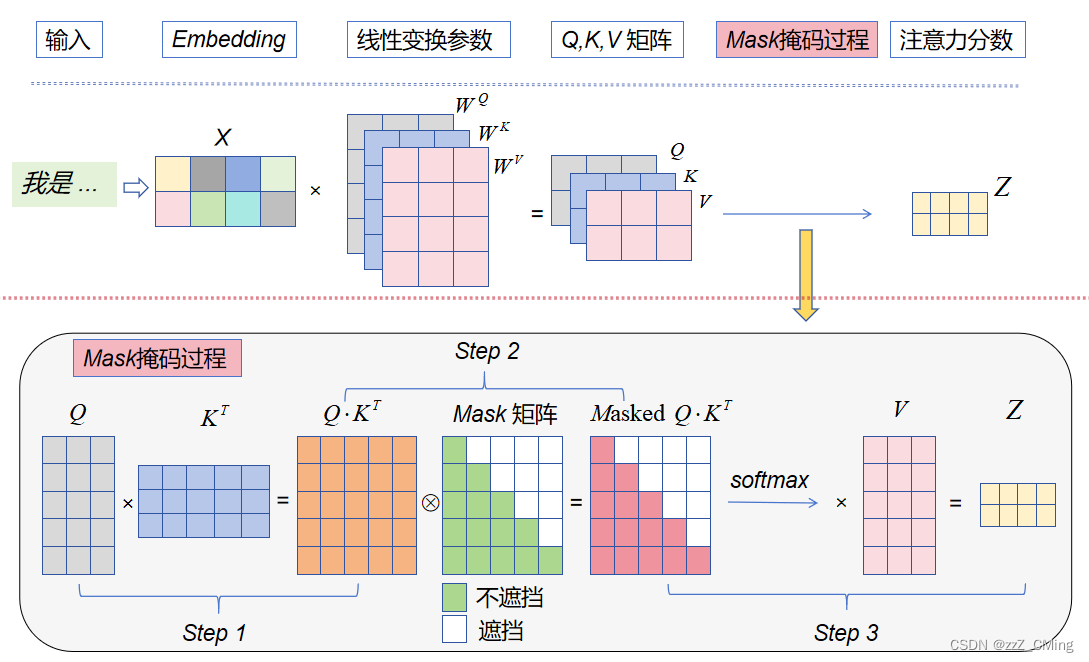
Mask掩码过程:
- Step 1:Q与K的转置做内积,得到 Q ⋅ K T Q·K^T Q⋅KT矩阵;
- Step 2: Q ⋅ K T Q·K^T Q⋅KT矩阵与Mask矩阵对位相乘,得到Masked Q ⋅ K T Q·K^T Q⋅KT矩阵;
- Masked Q ⋅ K T Q·K^T Q⋅KT矩阵经过 S o f t m a x ( ) Softmax() Softmax()操作,再与V相乘,得到掩码多头注意力输出;
Mask矩阵:按行参与计算,预测当下第 i 个词的时候,会掩盖住 i 之后所有的词,保证Mask注意力包含前序词语的影响;
4、其他结构说明
上面已经讲解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分
4.1、Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成:
- Add :表示残差连接 (Residual Connection) ,用于防止网络退化;
- Norm:表示 Layer Normalization,用于对每一层的激活值进行归一化;
计算公式如下:

X X X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出;
- Add 指 X+MultiHeadAttention(X),这是一种残差连接方式,在 ResNet 中经常用到。通常用于解决深层网络训练中梯度易消失的问题,让前部数据也能参与深层网络的训练。
- Norm指 Layer Normalization,会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。

4.2、Feed Forward
Feed Forward ,前馈网络层,比较简单,包含两个全连接层,第一层的激活函数为 ReLU,第二层不使用激活函数,表达式为: F N N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FNN(x)=max(0,xW_1 + b_1)W_2 + b_2 FNN(x)=max(0,xW1+b1)W2+b2
5、热点图展示
下边是两个句子中 it 与上下文单词的关系热点图。
只改变句子的最后一个单词,it 的指代就发生了转变——左图中的 it 与 animal 关系很强,右图 it 与 street 关系很强。
这个结果说明注意力机制是可以很好地学习到上下文的语言信息。

总结
- Transformer 可以并行训练,而RNN/LSTM 网络能并行训练;
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置向量path Embedding,否则 Transformer 就是一个词袋模型;
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输入进行线性变换得到;
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数(注意力分数attention score);
参考:
超详细图解Self-Attention
熬了一晚上,我从零实现了Transformer模型,把代码讲给你听
self-attention自注意力机制
致谢!















 3972
3972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









