







一、NLP 自然语言处理
NLP 是机器学习在语言学领域的研究,专注于理解与人类语言相关的一切。NLP 的目标不仅是要理解每个单独的单词含义,而且也要理解这些单词与之相关联的上下文之间的意思。
常见的NLP 任务列表:
- 对整句的分类:如获取评论的好坏、垃圾邮件的分类,如判断两个句子的逻辑相关性;
- 对句中单词的分类:如单词的语法构成(名词、动词、形容词)、单词的实体命名(人、地点、时间)
- 文本内容的生成:如文章续写、屏蔽词填充;
- 文本答案的提取:给定问题,根据上下文信息提前答案;
- 从提示文本生成新句子:如文本翻译、文本总结;
NLP 并不局限于书面文本,它也能解决语音识别、计算机视觉方方面的问题,如生成音频样本的转录、图像的描述等;
二、Transformer 架构
2.1、Transformer 发展历史
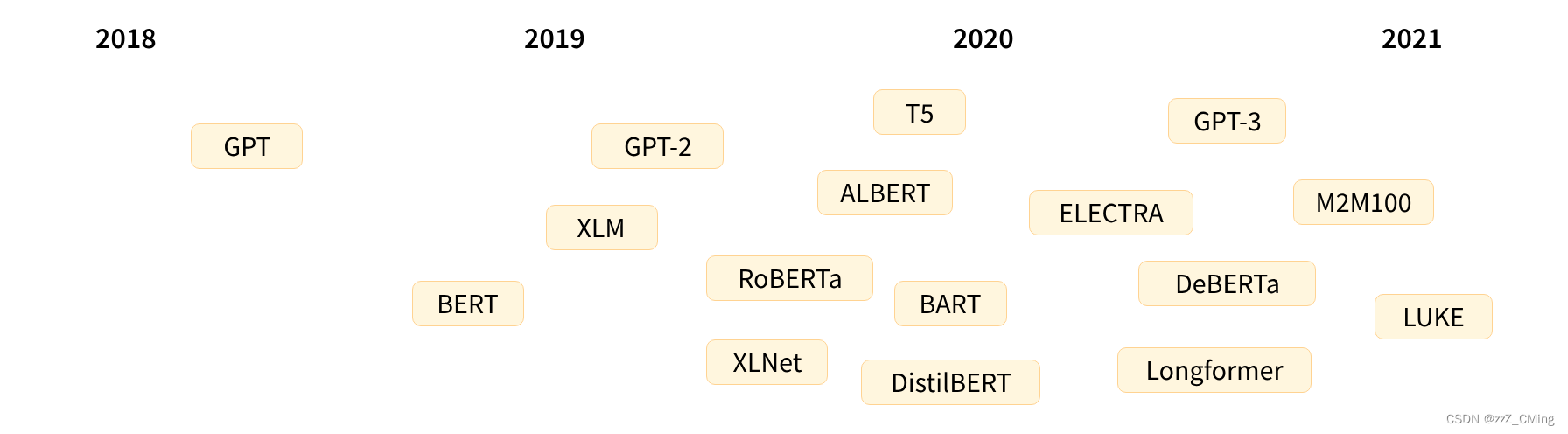
Transformer 架构于2017 年 6 月推出。最初的研究重点是翻译任务。随后推出了几个有影响力的模型,包括:
- 2018年6月:GPT,第一个预训练的Transformer模型,用于各种NLP任务的微调并获得了SOTA的结果;
- 2018 年10月:BERT,另一个大型预训练模型,旨在生成更好的句子摘要;
- 2019年2月:GPT-2,GPT 的改进(和更大)版本,由于道德问题没有立即公开发布;
- 2019年10月:DistilBERT,BERT 的精炼版,速度提高了 60%,内存减少了 40%,但仍然保留了 BERT 97% 的性能;
- 2019年10月:BART、T5,两个大型预训练模型,使用与原始 Transformer 模型相同的架构;
- 2020年5月:GPT-3,GPT-2的更大版本,能够在各种任务上表现良好,无需微调(称为zero-shot零样本学习)
上面提到的所有Transformer 模型(GPT、BERT、BART、T5 等)都是预训练语言模型(以自监督的方式接受了大量原始文本的训练),预训练模型可以对其所训练的语言进行统计理解,但对于特定的实际任务来说并不是很有用。正因如此,一般的预训练模型还要经历一个迁移学习的过程,针对具体的任务微调出不同的模型。
预训练模型
- 权重随机初始化,在没有任何先验知识的情况下开始训练;
- 需要大量的数据用于训练,训练时间很久;
微调模型
- 是在预训练模型的基础上进行的训练;
- 使用满足需求的小型数据集,微调训练的时间不会很久;
- 微调模型在时间、数据、财务、硬件等方面的成本较低,容易部署;
所以在实际应用中,应该始终尝试去寻找与实际任务接近的预训练模型,再搭配满足任务需求的小样本数据集,以监督学习的方式微调这个预训练模型,最终得到满足需求的定向模型,以此完成下游任务。
2.2、Transformer 详细原理
详细原理请看链接:Transformer 模型原理。详细原理具体包括:
- 编码器Encoder部分
- 解码器Decoder部分
- Self-Attention 自注意力原理
- Multi-Head Attention 多头注意力机制
2.3、Transformer 能做什么
Transformer 最初的研究重点是NLP 的翻译任务,现在发展到有关语言学的模型,都会用到Transformers 库。
# # 安装
pip install transformers
# # 导入
import transformers
Transformers库的优势:
- 简单:Transformers只提供一个 API,只需两行代码即可下载、加载和使用 NLP 模型进行推理;
- 灵活:所有模型的核心都是 PyTorch 的nn.Module 类或 TensorFlow 的tf.keras.Model 类;
- 独立:模型之间相互独立,每个模型拥有的层都在一个模型文件内。这个是与其他 ML 库截然不同的。
Transformers 库中最基本的对象是pipeline() 函数,它将必要的预处理和后处理连接起来,使我们能直接输入文本并获取对应需求的答案。常见的NLP 场景都有一些可用的pipeline() 管道模型与之对应:
- ner:实体命名识别
- fill-mask:掩码填充
- translation:翻译
- summarization:文章总结
- text-generation:文本生成
- question-answering:问题回答
- sentiment-analysis:情绪分析
- zero-shot-classification:零样本分类
- feature-extraction:获取文本的向量表示
from transformers import pipeline
# # # 实体命名识别
# ner = pipeline("ner", grouped_entities=True)
# print(ner("My name is Sylvain and I work at Hugging Face in Brooklyn."))
# # # 掩码填充
# fill_mask = pipeline("fill-mask")
# print(fill_mask("The cat is <mask> on the mat."))
# # # 翻译
# translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
# print(translator("Ce cours est produit par Hugging Face."))
# # # 文章总结
# summarizer = pipeline("summarization")
# print(summarizer("xxxxxxxxxxxxxxxxxx"))
# # # 文本生成
# generator = pipeline("text-generation")
# print(generator("In this course, we will teach you how to"))
# # # 指定hugging face Hub网站中任意模型
# generator = pipeline("text-generation", model="distilgpt2")
# print(generator("In this course, we will teach you how to", max_length=30, num_return_sequences=2))
# # # 问题回答
# question_answerer = pipeline("question-answering")
# print(question_answerer(question="Where do I work?", context="My name is Sylvain and I work at Hugging Face in Brooklyn"))
# # 情绪分析
classifier = pipeline("sentiment-analysis") # # (该库只能输入英文。)
print(classifier(["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]))
# # # 零样本分类zero-shot-classification
# classifier = pipeline("zero-shot-classification")
# print(classifier("This is a course about the Transformers library", candidate_labels=["education", "politics", "business"]))
# # # 获取文本的向量表示
# feature_extraction = pipeline("feature-extraction")
# print(feature_extraction("i am a studet"))
三、Transformers 库
Hugging Face 社区是最大的Transformer开发者的交流地,里面免费共享了数万个预训练模型、数据集,任何人都可以直接下载和使用。而Transformers 库提供了加载和使用这些共享模型、数据集的功能。请多多关注Hugging Face 社区,最新的研究都会在这里更新。
3.1、总流程
NLP 在处理具体问题时,主要涉及三个步骤:
- 将人类可理解的文本,经过预处理,转变成模型可理解的数据格式;
- 模型可理解的数据传至模型,模型做出预测;
- 模型的预测再经过后处理,输出返回人类可理解的文本。
例如:
from transformers import pipeline
# # 情绪分析
classifier = pipeline("sentiment-analysis") # # (该模型只能处理英文。)
print(classifier(["This course is amazing.", "I hate this so much!"]))
# # 结果
# [{'label': 'POSITIVE', 'score': 0.9989047137260437},
# {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
pipeline() 管道函数将预处理、模型预测、后处理三个步骤组合在了一起;
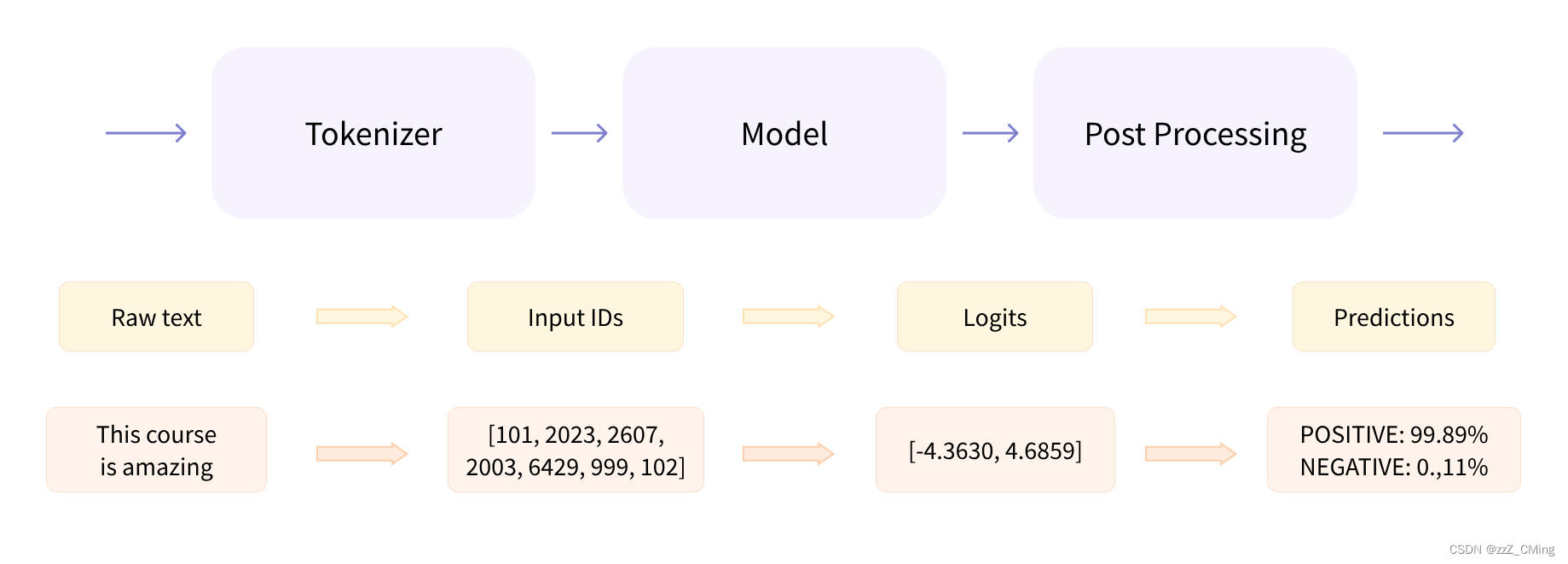
3.1.1、预处理:文本标志化
人类可理解原始文本raw text,机器可理解数字格式,标志器tokenizer(也叫分词器)便是两种数据之间转换的桥梁。
和其他神经网络一样,Transformer 也无法直接处理原始文本。所以第一步要使用标志器tokenizer将输入的原始文本raw text 转换为模型可理解的数字类型,它具体负责:
- 将输入的原始文本raw text 转换为tokens(单词words、子单词subwords、符号symbols 都算)
- 将每个tokens 与一个整数做映射,得到Input IDs;
- 同时也会添加可能对模型有用的额外输入,比如起始字符、隔断字符等;
同一个单词在不同模型的tokenizer下得到的Input IDs数值可能不同,而Input IDs数值必须要与当前使用的预训练模型保持通用。为此,AutoModel 和AutoTokenizer 请共用一个模型检查点checkpoint,如下第456行:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# # 加载标志器,模型
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
有了标志器,我们就可以直接将句子传递给它,标志器对输入文本进行编码;
raw_text = ["This is first sentence, so long!",
"This is second sentence.",
"I am a student.",
"me too!"]
tokens = tokenizer(raw_text, padding=True, truncation=True, max_length = 10, return_tensors="pt")
print(tokens)
- padding:填充,确保所有样本在序列长度上是一致的,如果样本的长度小于既定长度,将用填充字符进行补齐;
- truncation:截断,确保所有样本序列长度不超过既定长度,若超过,进行截断处理;
- max_length :既定长度,默认为True,不同模型的既定长度可能不一样,也可以用数值指定;
- return_tensors:指定返回的张量类型,“pt”:PyTorch,“tf”:TensorFlow ,“np”:NumPy;
编码后的结果tokens 的PyTorch 张量结构如下:
{
'input_ids': tensor([
[101, 2023, 2003, 2034, 6251, 1010, 2061, 2146, 999, 102],
[101, 2023, 2003, 2117, 6251, 1012, 102, 0, 0, 0],
[101, 1045, 2572, 1037, 3076, 1012, 102, 0, 0, 0],
[101, 2033, 2205, 999, 102, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
])
}
不同标志器编码输出的张量结构也存在一定差异,这个是包含两个键的字典:
- input_ids:每一行代表一个编码后的句子,0 表示填充字符
- attention_mask:1 表示要注意该位标记,0 表示不注意该位标记(即忽略该位),主要用于self-attention层
3.1.2、模型预测
和标志器tokenizer 一样,Transformers 也提供了一个AutoModel 类和from_pretrained() 方法——在使用该模型检查点checkpoint 时,自动下载、加载、使用该模型。
from transformers import AutoModel
# # 下载模型
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
而在具体任务中,模型需要根据不同的任务需求,选择加载不同的模型头model head。模型头是附加组件,通常由一层或几层组成,用于将预测转换为特定任务的输出,下面是一个非详尽的模型头列表:(下表里的 -xxx 表示省略,请与前文保存一致)
- *ForCausalLM:因果语言模型,用于文本生成、对话生成,例如GPT2ForCausalLM,XLNetForCausalLM;
- *ForMaskedLM:掩码模型,用于理解语言的上下文和语境,例如BERTForMaskedLM、RobertaForMaskedLM;
- *ForMultipleChoice:多项选择模型,常见于问答系统,例如BertForMultipleChoice、XLNetForMultipleChoice;
- *ForQuestionAnswering:问答模型,例如BertFor-xxx、DistilBertFor-xxx、XLNetForQ-xxx;
- *ForSequenceClassification:序列分类模型,常见于文本分类、情感分析,例如BertFor-xxx、DistilBertFor-xxx、XLNetFor-xxx;
- *ForTokenClassification:标记分类模型,常见于命名实体识别,例如BertFor-xxx、DistilBertFor-xxx、XLNetFor-xxx;
- *Model:用于检索模型架构的隐藏状态
- 其他
对于我们的示例,我们需要模型具有序列分类的能力(能够将句子分类为正例或负例),因此我们实际不会使用AutoModel 用于初始化,而是会根据具体需求使用AutoModelForSequenceClassification 这个模型头;
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_text = ["This is first sentence, so long!",
"This is second sentence.",
"I am a student.",
"me too!"]
tokens = tokenizer(raw_text, padding=True, truncation=True, max_length= 10, return_tensors="pt")
outputs = model(**tokens)
print(outputs.logits)
# tensor([[ 2.4987, -2.1341],
# [ 1.8418, -1.6359],
# [-2.2480, 2.3552],
# [-3.8088, 4.1025]], grad_fn=<AddmmBackward0>)
3.1.3、后处理
我们从模型中获得的输出值本身并不一定有意义,例如上例中的输出,它并不是概率,而是logits,要转换为概率,还需要经过SoftMax层,这样就可以看到输出的概率;
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
# tensor([[9.9037e-01, 9.6337e-03],
# [9.7004e-01, 2.9956e-02],
# [9.9205e-03, 9.9008e-01],
# [3.6646e-04, 9.9963e-01]], grad_fn=<SoftmaxBackward0>)
再配合每个位置对应的标签:
model.config.id2label
# # {0: 'NEGATIVE', 1: 'POSITIVE'}
数值与标签的结合,就可以得出结论,该模型预测了如下内容:
- 第一句:有99.04%的概率是NEGATIVE,只有0.96%的概率是POSITIVE
- 第四句:有0.04%的概率是NEGATIVE,有99.96%的概率是POSITIVE
3.2、有关模型model 的细节
上面我们介绍了用AutoModel类实例化模型。实际上AutoModel 类是Transformers 库中可用的所有模型的API 包装器,这个包装器非常的聪明,它可以自动适配当前检查点checkpoint 的模型架构(自动适配具体的任务),再加载必要参数,进而实例化模型。
但如果你知道要使用的模型类型(比如使用BERT 模型),加载还是不加载预训练模型权重呢?
- 使用from_pretrained() 方法加载预训练模型权重直接用于下游任务或微调;——推荐
- 只是使用其定义的网络结构,以随机权重加载网络,用于全新网络的训练;——不推荐
3.2.1、加载模型
以BERT 模型为例,使用from_pretrained() 方法加载已经训练好的Transformer 模型:
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
- 在Hugging Face 资料卡中可以找到每个模型的具体信息,根据任务需求选择适当模型;
- from_pretrained() 方法加载检查点checkpoint的所有权重并进行初始化,可以用于推理,也可以对新需求用数据集进行微调;
- from_pretrained() 方法下载的模型会默认存放在 ~/.cache/huggingface/transformers路径下,可以通过设置HF_HOME环境变量来自定义缓存地址;
3.2.2、创建模型、保存模型
创建模型
还是以BERT 模型为例,使用配置参数BertConfig 创建模型,以随机数权重进行初始化;
可以输出BERT 模型的配置参数,这些参数包含许多用于构建模型的基本属性信息;
from transformers import BertConfig, BertModel
# # 读取配置参数
config = BertConfig()
print(config)
# # 配置参数构建模型
model = BertModel(config) # # 模型是随机初始化的!
# BertConfig {
# [...]
# "hidden_size": 768, # # 隐藏层中神经元的数量
# "intermediate_size": 3072, # # FNN前馈网络中间层的维度
# "max_position_embeddings": 512, # # 最大序列长度,也是位置矩阵的长度
# "num_attention_heads": 12, # # 注意力头的数量
# "num_hidden_layers": 12, # # 隐藏层的数量
# [...]
# }
上述创建模型的方式是使用随机权重进行的初始化,相当于创建了一个全新的、未训练的模型。该状态下的模型也可以使用,但会输出乱码,需要注入数据 + 需要时间训练——不必重复造轮子,请使用共享的、已经训练好的预训练模型吧!
保存模型
保存模型就像加载模型一样简单,保存模型用:
model.save_pretrained("model_path")
将会有两类文件保存在model_path目录下,这两类文件缺一不可;
配置文件:保存模型架构,权重文件:保存模型权重(权重文件可能有多个)。
config.json # # 配置文件:保存构建模型架构所需的所有属性
pytorch_model.bin # # 权重文件:保存模型所有的权重数值,可能有多个.bin文件
3.3、有关标志器tokenizer 的细节
标志器tokenizer 是NLP 管道的核心组件之一。
标志器tokenizer 的目的只有一个:人类可理解的文本类型与机器可理解的数字类型的相互转换。
在NLP任务中,一般处理的数据是原始文本raw text,例如:I am a student,有很多方法可以将原始文本转换为数字,但我们希望得到一个高质量的标志器——除了能完成对数据的转换,同时希望它也是占位最小的表示方法。介绍三种分词方法(当然不止这三种)
3.3.1、文本分割方式
1、基于单词(word-based)
例如,通过Python split() 函数,使用空格将文本分割;
tokenized_text = "I am a student".split()
print(tokenized_text)
# # ["I", "am", "a", "studet"]
基于单词的这种tokenizer 最终可以得到一个相当大的“词汇表”,每个词分配一个 ID,从零开始累加直至词汇表末尾,模型使用这些 ID 与每个词对应。
如果想用这种标志器完全覆盖一种语言,这将生成大量的标记词汇。英语就有超过 500,000 个单词,如果以此构建ID,需要跟踪的数据太过庞大。除此之外,例如student 和students 这样的词,意思相近但表示ID不同,模型最初无法建立注意力,会将这两个词识别为不相关,从而引入不必要的误差。
除此之外,我们还需要有自定义标记来表示不在词汇表中的词,这种词被叫做unknown token,通常用 [UNK] 或者 " " 表示。如果看到标记器正在大量生成此类标记,这通常是一个坏兆头,因为它无法检索单词的合理表示,并且会在此过程中丢失信息。
2、基于字符(character-based)
基于字符的标志器是将文本拆分为字符,而不在是单词,这样的做法有两个优点一个缺点 :
- 词汇表内的词汇量要小得多;
- 词汇表外的未知词汇也少得多,因为每个单词都可以由字符构建的;
空格、标点符号难以处理;

这种方法也不尽完美。根据语言的不同,拉丁文语言如果拆成字符,每个字符本身并没有多大意义,字符的组合才具有意义,而像中文这样的语言,即便拆成单独的字也依然携带很多信息。
以上两种标志器:
基于单词的标志器一个单词只有一个标记,
基于字符的标志器一个单词就轻松地变成10个或更多标记,
充分利用这两种方法,提出基于子词subword-based 的标志器。
3、基于子词(subword-based)
子词标志器依赖于这样的原则:经常使用的词不应该被分割成更小的子词,但罕见的词应该被分解成有意义的子词。

这些子词最终提供了很多语义含义。例如在上面的示例中,tokenization 被拆分为token + ization,这两个标记都具有语义含义,同时节省了空间(只需要两个标记的组合来表示一个长单词)。这使我们能够用较小的词汇量获得相对较好的覆盖率,并且几乎没有未知的标记。
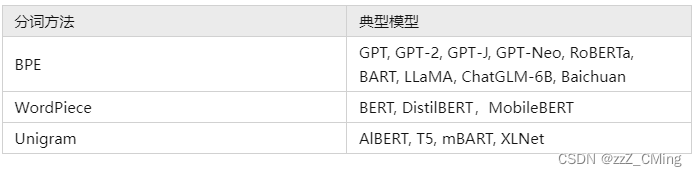
4、其他方法
除了以上三种分词方法,毫无意外还有更多方法,仅举几例:
3.3.2、标志器的加载与保存
标志器的加载和保存与模型一样使用from_pretrained() 和save_pretrained() 方法,以BERT 模型为例:
加载
from transformers import BertTokenizer, AutoTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") # # 也可用
print(tokenizer("This is the first sentence.", "This is the second one."))
# {
# 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# }
与AutoModel 类似,AutoTokenizer 也会根据检查点名称在库中获取正确的标志器类;
- input_ids:代表编码后的输出IDs;
- token_type_ids:是在BERT模型中用于表示不同句子的标识符,标识哪些部分是前句子,哪些部分是后句子;
- attention_mask:主要用于self-attention层。1 表示要注意相应位置的标记,0 表示忽略相应位置的标记。
保存
tokenizer.save_pretrained("my_path")
3.3.3、tokenizer 编-解码的过程
标志器的目的:将人类可理解的文本类型与机器可理解的数字类型相互转换。
文本类型——> 数字类型:编码过程,编码分两步:先分词,再对应ID;
数字类型——> 文本类型:解码过程,ID 直接用decode() 方法;
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# # # 编码过程:
# # 1、分词:raw text ——> tokens
raw_text= "I am a student."
tokens = tokenizer.tokenize(raw_text)
print(tokens) # # ['I', 'am', 'a', 'student', '.']
# # 2、对应:tokens ——> IDs
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids) # # [146, 1821, 170, 2377, 119]
# # # 解码过程:IDs ——> raw text
decoded_str = tokenizer.decode(ids)
print(decoded_str) # # I am a student.
3.3.4、特殊字符与多序列处理
特殊字符
观察下面两组标志化的方法,第7行和第13行,第9行和第15行,相同的raw_text 输入,但是输出却存在一点点差异;
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
raw_text = "I am a student."
inputs = tokenizer(raw_text)
print(inputs["input_ids"]) # # [101, 146, 1821, 170, 2377, 119, 102]
decoder_str1 = tokenizer.decode(inputs["input_ids"])
print(decoder_str1) # # [CLS] I am a student. [SEP]
tokens = tokenizer.tokenize(raw_text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids) # # [146, 1821, 170, 2377, 119]
decoded_str2 = tokenizer.decode(ids)
print(decoded_str2) # # I am a student.
第一种方法是直接使用tokenizer 来标记文本,文本就会被添加 [CLS] 、[SEP] 特殊字符。
- [CLS] :起始字符,后面跟的是表示文本的实际字符;
- [SEP] :分隔字符,表示文本的分隔以及结尾;
第一种方法是常用的!因为在实际应用中,需要依赖各式特殊字符来引导、定位、区分不同段落的数据,除了 [CLS] 起始字符、[SEP] 分隔字符外,还有几种特殊字符;
- [UNK] :未知字符,表示不在词汇表中的词;
- [PAD] :填充字符,短序列补齐长度时用到的字符;
- [MASK]:掩码字符,掩盖该位的字符;
多序列处理
多序列输入时,由于分隔字符 [SEP] 的存在使得模型能够同时处理多个句子的信息,如下示例:
from transformers import BertTokenizer
bert_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text1 = "This is first sentence."
text2 = "This is second sentence."
# # 获取token IDs
tokens1 = bert_tokenizer.tokenize(text1)
tokens2 = bert_tokenizer.tokenize(text2)
# # 添加 [CLS] 和 [SEP] 标记
tokens = ["[CLS]"] + tokens1 + ["[SEP]"] + tokens2 + ["[SEP]"]
print("Tokens:", tokens)
# # ['[CLS]', 'this', 'is', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'second', 'sentence', '.', '[SEP]']
四、微调
这一节研究针对自己的数据集如何微调预训练模型,大致包括:
- 如何在Hugging Face社区准备大型数据集;
- 如何调用高级TrainerAPI 来微调模型;
- 如何使用自定义训练循环;
- 如何利用Accelerate 库在任何分布式设备上运行自定义训练;
针对上面的示例代码,数据还需要补齐标签labels 属性(第15行),以及选择优化器optimizer ,就可以开启训练:
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
# # 以下是新加的
# # batch数据主要包含input_ids、labels、token_type_ids、attention_mask等值
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
for i in range(11):
loss = model(**batch).loss
loss.backward()
optimizer.step()
if i%2 == 0:
print("i= %s, loss= %s"%(i, loss))
# i= 0, loss= tensor(0.5429, grad_fn=<NllLossBackward0>)
# i= 2, loss= tensor(0.0080, grad_fn=<NllLossBackward0>)
# i= 4, loss= tensor(0.0017, grad_fn=<NllLossBackward0>)
# i= 6, loss= tensor(8.9284e-05, grad_fn=<NllLossBackward0>)
# i= 8, loss= tensor(2.7418e-06, grad_fn=<NllLossBackward0>)
# i= 10, loss= tensor(4.1723e-07, grad_fn=<NllLossBackward0>)
只有两条数据很容易拟合,而且也不会产生很好的效果,所以需要准备更大的数据集,并完善 【训练–验证–loss输出–模型保存】 的过程
4.1、数据处理
4.1.1、数据加载
在Hugging face 社区的数据集页面,有公开共享的数万组数据集,你可以根据你的需求找到合适的数据用于后续的微调;
使用MRPC(微软研究释义的语料库)数据集作为示例,这个数据集由 5,801 个句子对组成,带有一个标签(是或否)用于指示前句与后句的意思是否相同;
读取数据集,读取方式在数据集页面有提示代码:
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
print(raw_datasets)
# DatasetDict({
# train: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 3668
# })
# validation: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 408
# })
# test: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 1725
# })
# })
- 数据集包含3668条训练数据、408条验证数据和1725条测试数据;
- 每条数据包含sentence1句式1、sentence2句式2、label 标签、idx 行号;
- 数据集地址默认在 ~/.cache/huggingface/datasets;
可以通过索引访问具体每条数据,也可以通过features 检查每条数据的属性;
raw_train_datasets = raw_datasets["train"]
print(raw_train_datasets[7])
# {
# 'sentence1': 'The DVD-CCA then appealed to the state Supreme Court .',
# 'sentence2': 'The DVD CCA appealed that decision to the U.S. Supreme Court .',
# 'label': 1,
# 'idx': 7
# }
print(raw_train_datasets.features)
# {
# 'sentence1': Value(dtype = 'string', id = None),
# 'sentence2': Value(dtype = 'string', id = None),
# 'label': ClassLabel(names = ['not_equivalent', 'equivalent'], id = None),
# 'idx': Value(dtype = 'int32', id = None)
# }
标签label 类型为ClassLabel,0对应于not_equivalent(前后句意思不相同),1对应于equivalent(前后句意思相同);
4.1.2、数据预处理
将文本转换为数字类型,就需要用到标志器tokenizer,
同时,transformers的model输入只需要凑齐 [input_ids、token_type_ids、attention_mask、labels] 四列即可;
所以需要对数据进行一定的处理,得到这四列数据;
# # 伪代码
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_datasets = load_dataset("glue", "mrpc")
# # 弃用
# tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
# tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
# # 使用map方式一次性处理
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator)
- 第6行:load_dataset() 方式读取得到一个字典A,其下包含sentence1、sentence2、label 、idx 四列数据;
- 第12/13/14/15/16行:用map() 方式将sentence1、sentence2 联立作为输入,经过tokenizer编码生成input_ids、token_type_ids、attention_mask 等数据(sentence1 、sentence2 已转化为input_ids);所以删除sentence1、sentence2 、idx 三列;再将原列名label 改为labels;
- 第17/18行:最后将数据集的格式设置为 PyTorch 格式,改为DataLoader方式按batch_size分块读取数据;
4.2、训练
指定GPU、指定训练轮数、选择优化器、设置学习率、学习率衰减
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 10
optimizer = AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler("linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_epochs)
4.2.1、一次完整的训练
import torch
import evaluate
from tqdm.auto import tqdm
from datasets import load_dataset
from torch.utils.data import DataLoader
from transformers import AdamW, get_scheduler, DataCollatorWithPadding
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
raw_datasets = load_dataset("glue", "mrpc")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator)
eval_dataloader = DataLoader(tokenized_datasets["validation"], shuffle=True, batch_size=8, collate_fn=data_collator)
num_epochs = 10
optimizer = AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler("linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_epochs)
for epoch in range(num_epochs):
# # 训练
model.train()
for batch in tqdm(train_dataloader):
batch = {k: v.to(device) for k, v in batch.items()}
# print("batch=", batch)
loss = model(**batch).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# # 学习率更新、模型保存
lr_scheduler.step()
model.save_pretrained("model_/")
tokenizer.save_pretrained("model_/")
# # 验证
metric = evaluate.load("glue", "mrpc")
model.eval()
for batch in tqdm(eval_dataloader):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions = predictions, references= batch["labels"])
BLEU_sorce = metric.compute()
print("epoch= %s, lr= %s, loss_train= %s, BLEU_score= %s"%(epoch, optimizer.param_groups[0]["lr"], loss.item(), BLEU_sorce))
# # epoch= 2, lr= 4.5e-05, loss_train= 0.009236547164618969, BLEU_score= {'accuracy': 0.8455882352941176, 'f1': 0.891566265060241}
- 第61行:metric.add_batch() 的目的是将批次的预测值和真实标签添加到指标对象中,以便在训练或评估过程结束时计算整体指标;
- 第62行:metric.compute() 方法计算整体准确率;BLEU_score 包含两个参数,accuracy是准确率,f1是综合考虑模型精度和召回率参数,f1=2*(精度*召回率)/(精度+召回率);
4.2.2、Trainer 类的使用
Transformers 库提供了一个Trainer 类来帮助我们微调任何预训练模型。
在TrainingArguments 类中指定与训练相关的参数,再传递给Trainer 对象开启训练,主要有如下三步:
import torch
import evaluate
import numpy as np
from tqdm.auto import tqdm
from datasets import load_dataset
from transformers import DataCollatorWithPadding
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
data_collator = DataCollatorWithPadding(tokenizer = tokenizer)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# # 1、设置训练参数
training_args = TrainingArguments(
output_dir="./model_", # # 模型和日志的根目录
num_train_epochs = 10, # # 训练的轮数
per_device_train_batch_size = 8, # # 每个设备上的训练批量大小
per_device_eval_batch_size = 8, # # 每个设备上的评估批量大小
save_steps=100, # # 每隔多少步保存一次模型、优化器和学习率调度器所有参数
learning_rate = 5e-5, # # 学习率
weight_decay = 0.01, # # 学习率衰减比例
warmup_steps = 300, # # 学习率预热步数
evaluation_strategy="steps", # # 指定何时进行评估 steps:每个eval_steps步长后评估,epoch:每个epoch结束后评估
eval_steps = 100, # # 评估的步长
)
# # 2、创建Trainer对象
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# # 3、开启训练
trainer.train()
# # 保存最后的模型
trainer.save_model("model_/last_model/")
验证的方式是通过在TrainingArguments中设置evaluation_strategy类型,在Trainer对象中以compute_metrics方式调用验证程序;
得到的loss输出如下,第一个字典是train_loss,第二个字典是eval_loss;
{
'loss': 0.1211,
'learning_rate': 3.2500000000000004e-05,
'epoch': 4.35
} {
'eval_loss': 0.7873289585113525,
'eval_accuracy': 0.8553921568627451,
'eval_f1': 0.8940754039497307,
'eval_runtime': 6.28,
'eval_samples_per_second': 64.968,
'eval_steps_per_second': 4.14,
'epoch': 4.35
}
4.2.3、Accelerator分布式加速
开启训练请执行:
accelerate launch xxx.py
import torch
import evaluate
from tqdm.auto import tqdm
from datasets import load_dataset
from torch.utils.data import DataLoader
from transformers import AdamW, get_scheduler, DataCollatorWithPadding
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from accelerate import Accelerator
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
raw_datasets = load_dataset("glue", "mrpc")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator)
eval_dataloader = DataLoader(tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator)
# # 创建 Accelerator 对象
accelerator = Accelerator()
# # 使用 Accelerator 包装模型和数据集
num_epochs = 10
optimizer = AdamW(model.parameters(), lr=5e-5)
lr_scheduler = get_scheduler("linear", optimizer = optimizer, num_warmup_steps = 0, num_training_steps = num_epochs)
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)
for epoch in range(num_epochs):
# # 训练
model.train()
for batch in tqdm(train_dataloader):
loss = model(**batch).loss
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
# # 学习率更新、模型保存
lr_scheduler.step()
# accelerator.save_model(model, "model_/") # # 只保存模型.bin文件
accelerator.save_state(output_dir = "model_/") # # 保存模型、优化器和学习率调度器所有参数
# # 验证
metric = evaluate.load("glue", "mrpc")
model.eval()
for batch in tqdm(eval_dataloader):
with torch.no_grad():
logits = model(**batch).logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions= predictions, references= batch["labels"])
BLEU_sorce = metric.compute()
print("epoch= %s, lr= %s, loss_train= %s, BLEU_score= %s"%(epoch, optimizer.param_groups[0]["lr"], loss.item(), BLEU_sorce))
4.3、测试
将下面的checkpoint 修改成自己模型的路径,就可以引用自己训练的模型了;
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "model_/"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
raw_data0 = ["I am s student.", "I am still in school."]
raw_data1 = ["I am s student.", "you are so beautiful."]
used_raw = raw_data1
tokens = tokenizer(used_raw[0], used_raw[1], truncation=True, return_tensors="pt").to(device)
print("tokens=", tokens)
logits = model(**tokens).logits
predictions = torch.argmax(logits, dim=-1).item()
print("predictions=", predictions)
这只是一个简单的分类例子。在不同的需求下,对数据的处理、模型的选用、训练的时长、模型的调用方式都不一样,请在Hugging Face 社区完成更伟大的创作吧。
最后的最后:
本篇绝大多数知识点、数据来源于Hugging Face 社区,谢鸣!















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









