






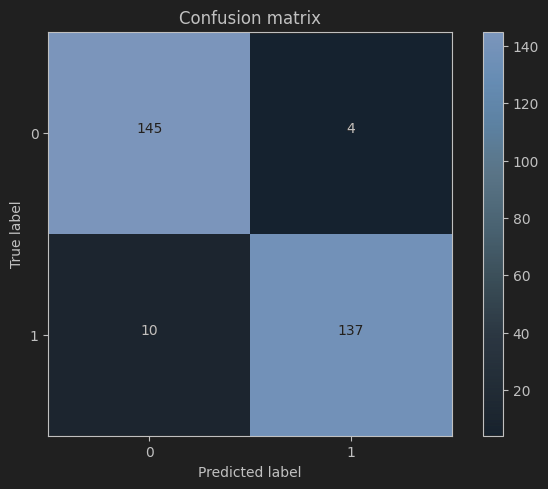
混淆矩阵(Confusion Matrix)是一种用于描述监督学习中分类模型性能的特定表格布局。它提供了直观的方式来理解分类器的性能,特别是对于多类别分类任务。混淆矩阵通过比较实际类别标签与分类器预测的类别标签来展示分类结果。
混淆矩阵的基本组成
假设我们有一个二分类问题,模型试图将数据分为两个类别:“正类”(Positive)和“负类”(Negative)。混淆矩阵包含四个基本元素:
- 真正例(True Positive, TP):实际为正类,且被模型正确预测为正类的实例数。
- 假正例(False Positive, FP):实际为负类,但被模型错误预测为正类的实例数。
- 真负例(True Negative, TN):实际为负类,且被模型正确预测为负类的实例数。
- 假负例(False Negative, FN):实际为正类,但被模型错误预测为负类的实例数。
混淆矩阵的可视化
混淆矩阵通常呈现为如下2x2的表格形式:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | TP | FN |
| 实际为负类 | FP | TN |
基于混淆矩阵的性能指标
通过混淆矩阵,可以定义多种性能指标,包括但不限于:
- 准确率(Accuracy):模型正确预测的样本数占总样本数的比例。
$ \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} $ - 精确率(Precision):模型预测为正类的样本中,实际为正类的比例。
$ \text{Precision} = \frac{TP}{TP + FP} $ - 召回率(Recall 或 Sensitivity):实际为正类的样本中,被模型正确预测为正类的比例。
$ \text{Recall} = \frac{TP}{TP + FN} $ - 特异度(Specificity):实际为负类的样本中,被模型正确预测为负类的比例。
$ \text{Specificity} = \frac{TN}{TN + FP} $ - F1分数(F1 Score):精确率和召回率的调和平均值。
$ \text{F1 Score} = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} $
多类别情况
对于多类别分类问题,混淆矩阵会扩展成更大的矩阵,每一行代表实际类别,每一列表示预测类别。每个单元格中的值表示实际属于该行类别但被预测为该列类别的实例数。在这种情况下,可以计算每一对类别的精确率、召回率等指标。
混淆矩阵不仅有助于评估分类模型的性能,还能帮助发现哪些类别的分类效果不佳,进而指导模型改进的方向。
















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









