







Re-rank Coarse Classification with Local Region Enhanced Features for Fine-Grained Image Recognition
字节跳动AI实验室
文章目录
摘要
- 本文认为细粒度图像识别的难点是:捕获语义全局特征和区分性局部特征,两个特征不易集成,甚至冲突。
- 本文提出了一种基于检索的由粗到细的框架,通过使用局部区域增强的嵌入特征对 T o p N TopN TopN分类结果进行重新排序,以提高 T o p 1 Top1 Top1的准确性。
- 为了获得区分细粒度图像的区分区域,引入了一种弱监督方法来训练仅具有图像级标签的边框生成分支。
- 为了学习更有效的语义全局特征,在自动构建的层次类别结构上设计了多级损失。
- 实验在三个基准上达到了最先进的性能,还提供了可视化和分析。
由粗到细的用topN增强top1特别像之前看到过的梯度损失增强的方法,论文《Fine-grained Recognition: Accounting for Subtle Differences between Similar Classes》,但是这里是计算相似度。
1 引言
提出了一种同时学习全局特征和局部特征的基于检索的模型,称为CCFR,将生成局部区域增强特征以对传统全局池化特征预测的分类结果进行重新排序。一条分支根据全局特征选择topn分类结果,另一条分支学习与全局特征相融合的有区别的局部特征,以进行搜索,对粗分类结果进行重新排名。
模型的关键是如何准确定位可区分的部分区域:提出了一种弱监督方法,以仅使用图像级标签有效地定位可区分的部分区域。利用特征金字塔网络生成一系列多尺度区域,其中triplet loss用于使局部区域更具区分性。相对于信息量最高的整个对象区域,具有区别性的局部区域更重要。为了学习更有效的全局语义特征,利用一种无监督的方法来自动构建层次结构类别结构,设计了一个多级损失训练模型。
文章贡献:
- 建立一个CCFR架构,通过重新排名同时使用全局特征和零件特征。
- 有效地选择可区分局部区域的无监督方法
- 利用一种无监督的方法自动构建层次类别结构,以学习更有效的全局语义特征
3 方法
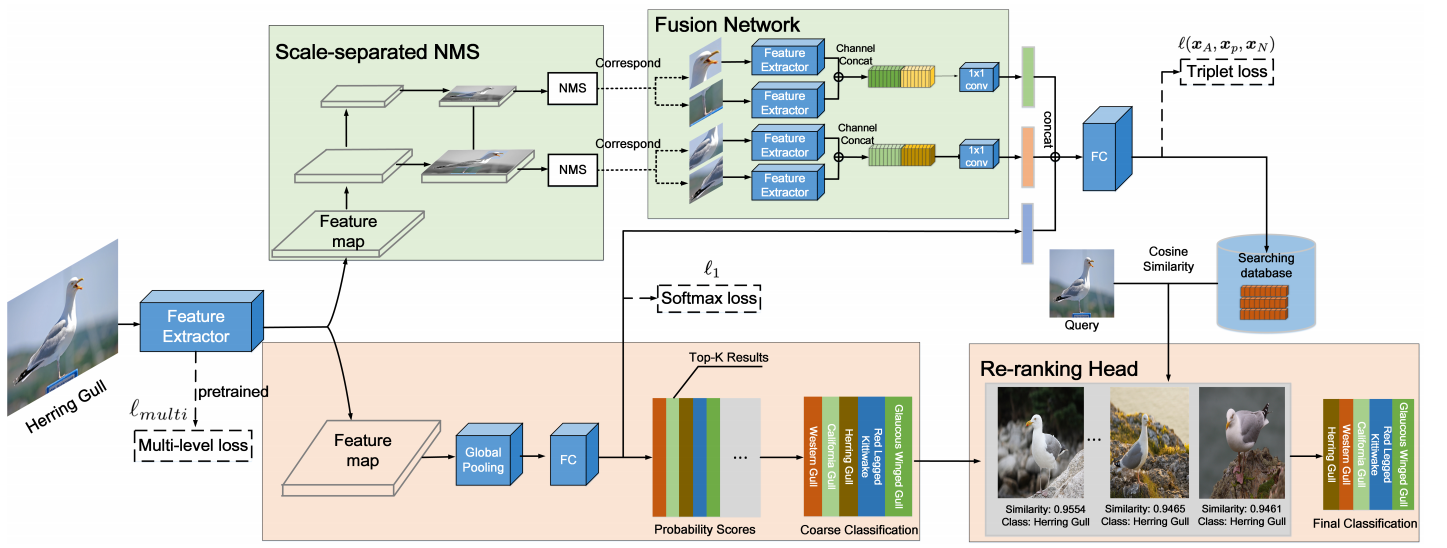
- 顶部分支提取用于增强全局特征的可区分局部特征,构建数据库以进行重新排名
- 底部分支获取具有全局特征的topn分类结果,然后使用数据库对其进行重新排名,获得最终结果
CCFR是基于检索的方法,可以结合topn分类和搜索结果来有效纠正错误分类的图像
3.1 全局特征的多层次损失
灵感来源:人在识别时是从粗到细的,比如先看出是鸟,后看出是哪种鸟。为了模仿这种过程,根据视觉外观将类别分为多级损失:
-
首先通过视觉特征聚类自动构建层次分类系统
-
使用多级损失以利用构造的类别系统。在原始的子类和聚类构造的超类上采用两个标准的Softmax损失,然后在这两个类别之间设计约束损失:
l 1 = − ∑ i = 1 C y i log p i l 2 = − ∑ j = 1 C f y j log p j l h = max ( 0 , p c h i l d r e n − p p a r e n t ) l m u l t i = l 1 + λ ∗ l 2 + l h l_1=-\sum^{C}_{i=1}\mathbf{y_i}\log{\mathbf{p_i}}\\ l_2=-\sum^{C_f}_{j=1}\mathbf{y_j}\log{\mathbf{p_j}}\\ l_h=\max(0,\mathbf{p_{children}}-\mathbf{p_{parent}})\\ l_{multi}=l_1+\lambda*l_2+l_h l1=−i=1∑Cyilogpil2=−j=1∑Cfyjlogpjlh=max(0,pchildren−pparent)lmulti=l1+λ∗l2+lh
p i p_i pi是子类别概率, p j p_j pj是超类别概率, p c h i l d r e n p_{children} pchildren是同一超类下所有子类别可能性的均值, p p a r e n t p_{parent} pparent是超类概率。
3.2 弱监督区别性区域定位
为了选择有区别的局部区域,利用特征金字塔(FPN)启发的横向连接检测网络,采用自上而下的路径。可获得一系列具有不同空间分辨率的特征图。通过使用这些多尺度特征图,可以在不同尺度和比率之间生成局部区域。具体来说,对于大小为448的输入图像,我们将边界框尺度设置为{96,192},纵横比设置为1:1。假设对象的不同部分具有不同的比例,则对所有比例的框执行NMS可能会导致较大的框抑制较小的框。 因此,分别在每个尺度上执行NMS(称为尺度分离NMS)。然后,将选定的框调整为预定义的尺寸输入到特征提取器中获取局部特征。
为防止过拟合,全局特征提取和局部特征提取参数共享。为了更好地捕获不同区域之间的空间关系,对于每个尺度,将通道方向上的局部特征串联起来,经过1×1卷融合(称为为Fusion Network)。
采用triplet loss来学习区别性局部特征:
l
(
x
A
,
x
P
,
x
N
)
=
f
(
s
i
m
(
x
A
,
x
P
)
−
s
i
m
(
x
A
,
x
N
)
−
a
)
l(x_A,x_P,x_N)=f(sim(x_A,x_P)-sim(x_A,x_N)-a)
l(xA,xP,xN)=f(sim(xA,xP)−sim(xA,xN)−a)
s
i
m
sim
sim是余弦相似度,
f
(
y
)
=
max
(
0
,
−
y
)
f(y)=\max(0,-y)
f(y)=max(0,−y)。
最终损失:
l
=
−
∑
i
=
1
C
y
i
log
p
i
+
μ
∗
l
(
x
A
i
,
x
P
i
,
x
N
i
)
l=-\sum^C_{i=1}y_i\log p_i+ \mu*l(x_A^i,x_P^i,x_N^i)
l=−i=1∑Cyilogpi+μ∗l(xAi,xPi,xNi)
3.3 通过检索实现重排序
现在获得了topn概率分数和判别性局部增强特征
构造搜索数据库:我们将需要重新组织的图像视为查询q,并通过计算查询和搜索数据库之间的余弦相似度来获得带有标签的topm相似度得分。最终根据这些相似度得分和标签对分类结果进行重新排序。
- 令 X = { x k c } X = \{x^c_k\} X={xkc}是选定的训练样本作为搜索数据库,其中 x k c x^c_k xkc是局部增强特征向量(k是样本序号,c是类别序号)
- 令 s i m ( q , X ) = { s i m ( q , x k c ) } sim(q,X)=\{sim(q,x^c_k)\} sim(q,X)={sim(q,xkc)}是测试样本q和数据库中所有训练样本之间的相似性。 r a n k ( q , X , t o p m ) rank(q,X,topm) rank(q,X,topm)是最像测试样本的topm个训练样本
最终的重排序分数:
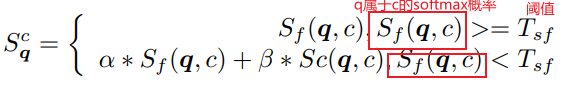
如果测试图片属于某一类分数特别大,那么不做修正,反之,查询数据库做修正:
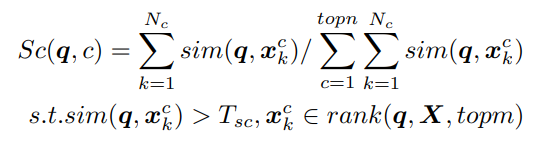
假设是该图片真实类别最可能在前topn个类中,后面的类别不予考虑。统计图片和数据库这一类的topm个最相似的相似度,再做归一化。
4 实验
4.2 实现细节
每个图像预处理为448×448,每个比例选择2个局部区域,并将NMS阈值设置为0.25。先利用排名损失进行训练FPN获得好的检测性能,再使用Softmax损失和Triplet损失来训练模型。topn设置为5,α设置为0,将β设置为1,这意味着仅在Softmax概率较低时才使用搜索相似性。
4.3 定量分析
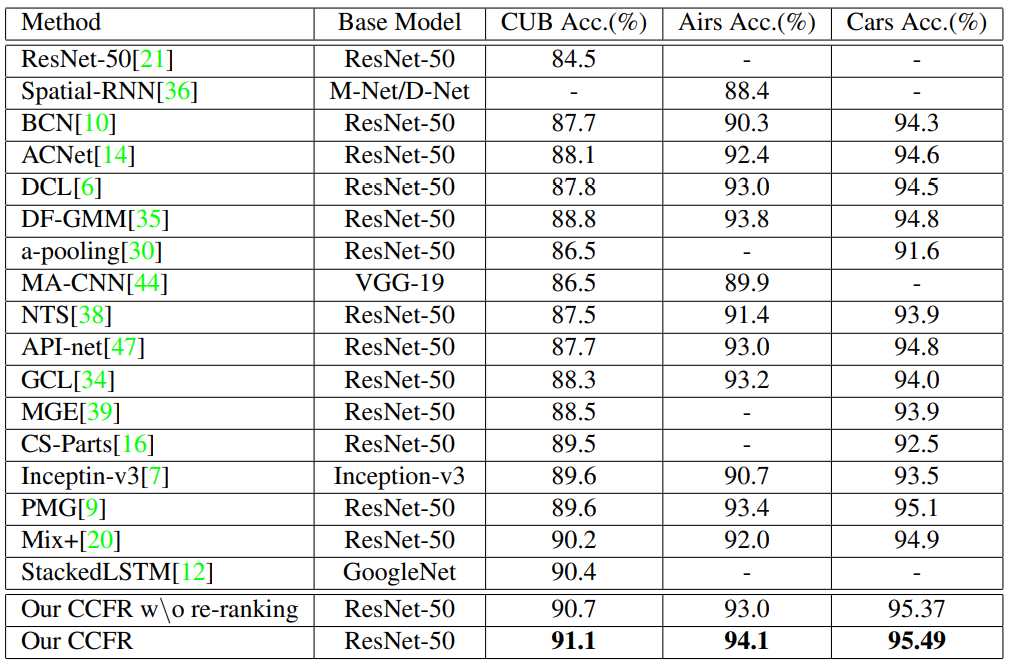
从最后两行可以明显看出,重新排名可以进一步提高Top1的准确性。
4.4 消融实验
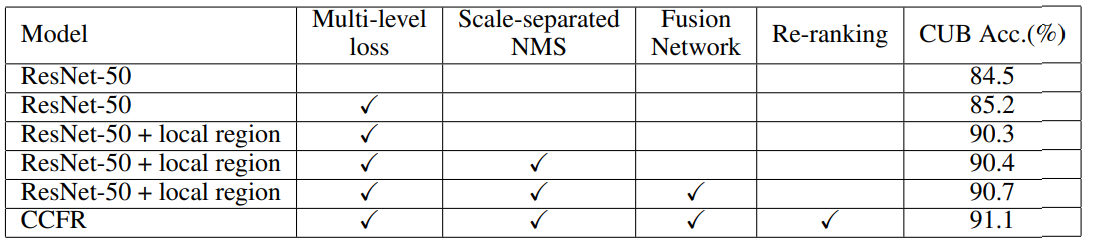
5 结论
- 提出了CCFR框架
- 其中生成了局部区域增强特征以对topn分类进行重新排序结果由语义全局特征预测。
- 设计了一种有效的结构来整合局部和全局特征,并使用triplet loss来发现更多区分区域
- 为了学习更有效的语义全局特征,设计了一种基于自动聚类的分层类别结构的多级损失,以进行骨干网预训练















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









