







文章目录
STN的作用
之前参加过一个点云数据分类的比赛,主要借鉴了PointNet的网络结构,在PointNet中使用到了两次STN。点云数据存在两个主要问题:1、无序性:点云本质上是一长串点(nx3矩阵,其中n是点数)。在几何上,点的顺序不影响它在空间中对整体形状的表示,例如,相同的点云可以由两个完全不同的矩阵表示。2、旋转性:相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化,我们希望不论点云在怎样的坐标系下呈现,网络都能正确的识别出。
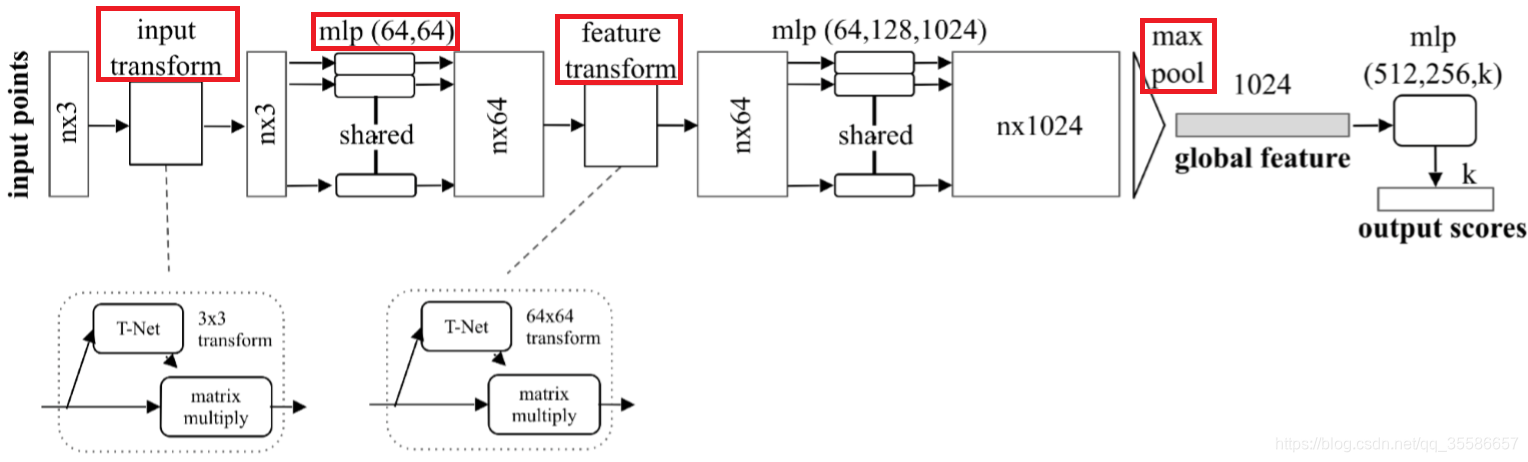
上图是PointNet的网络结构,网络对每个点进行了一定程度的特征提取之后,maxpooling可以对点云的整体提取出global feature,从而解决了无序性的问题。PointNet采用了两次STN解决旋转行问题,第一次input transform是对空间中点云进行调整,直观上理解是旋转出一个更有利于分类或分割的角度,比如把物体转到正面;第二次feature transform是对提取出的64维特征进行对齐,即在特征层面对点云进行变换。PointNet是第一篇直接使用原始点云数据作为输入进行分类和分割任务的论文,有兴趣的可以看一下原文PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
PointNet中的STN实现了三位点云的旋转,而最初出自这篇Spatial Transformer Networks论文的STN是针对图片提出的,但其目的是一致的,都是为了实现旋转不变性。
熟悉卷积网络和池化过程的人应该知道,普通的CNN能够显式的学习平移不变性,以及隐式的学习旋转不变性,那为什么还需要STN? Attention机制告诉了我们,与其让网络隐式的学习到某种能力,不如为网络设计一个显式的处理模块,专门处理所需的各种变换。STN把裁剪、平移、缩放等过程加入了训练,使其可以求解梯度,参与网络的反向传播,有利于End-to-end网络的设计与实现。
STN的基本结构
STN的核心结构如下图所示:
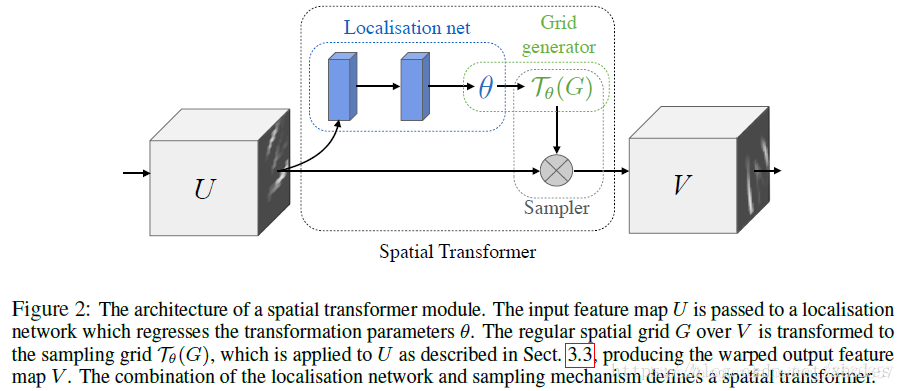
主要由三个部分组成:1、参数预测:Localisation net ;2、坐标映射:Grid generator ;3、像素的采集:Sampler
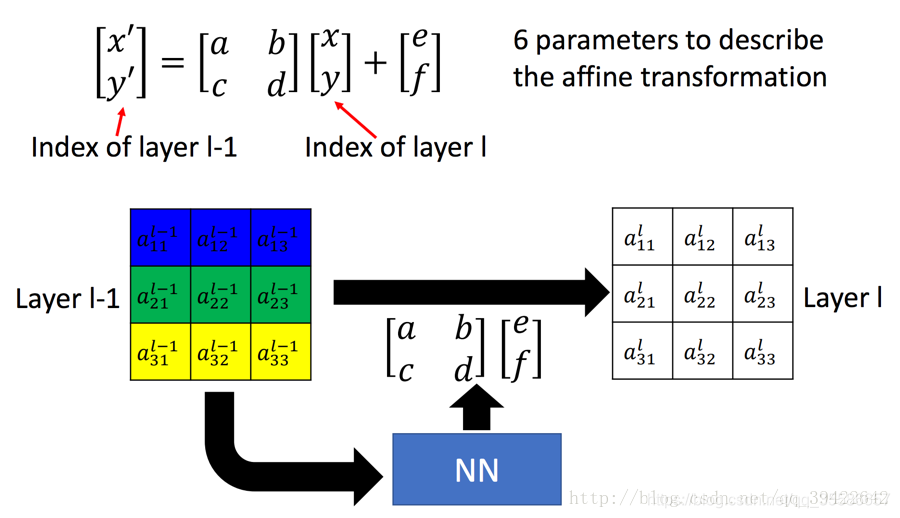
关于平移、缩放和旋转的具体转换原理,这篇博客里有更详细的介绍,这里只需要知道通过六个参数就可以实现这些操作即可,因此STN的输出也就是一个2x3的转换矩阵,转换公式如下:
而在论文中公式写作:

需要注意的是,(xti,yti)是输出的目标图片的坐标,(xsi,ysi)是原图片的坐标,Aθ表示仿射关系即STN矩阵,也就是说转换矩阵是目标图片到原图片的映射。比较合理的解释是:坐标映射的作用是让目标图片在原图片上采样,每次从原图片上不同坐标采集像素到目标图片上,原图片上会有多余的信息,而目标图片最终一定会被填满。每次目标图片的坐标要遍历一遍,是固定的,而采集原图的坐标是不固定的。通过拼图的例子会更容易理解:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









