






目录
第1部分 代码练习
1.1 pytorch基础练习
PyTorch是一个python库,它主要提供了两个高级功能:
- GPU加速的张量计算
- 构建在反向自动求导系统上的深度神经网络
1.1.1 定义数据
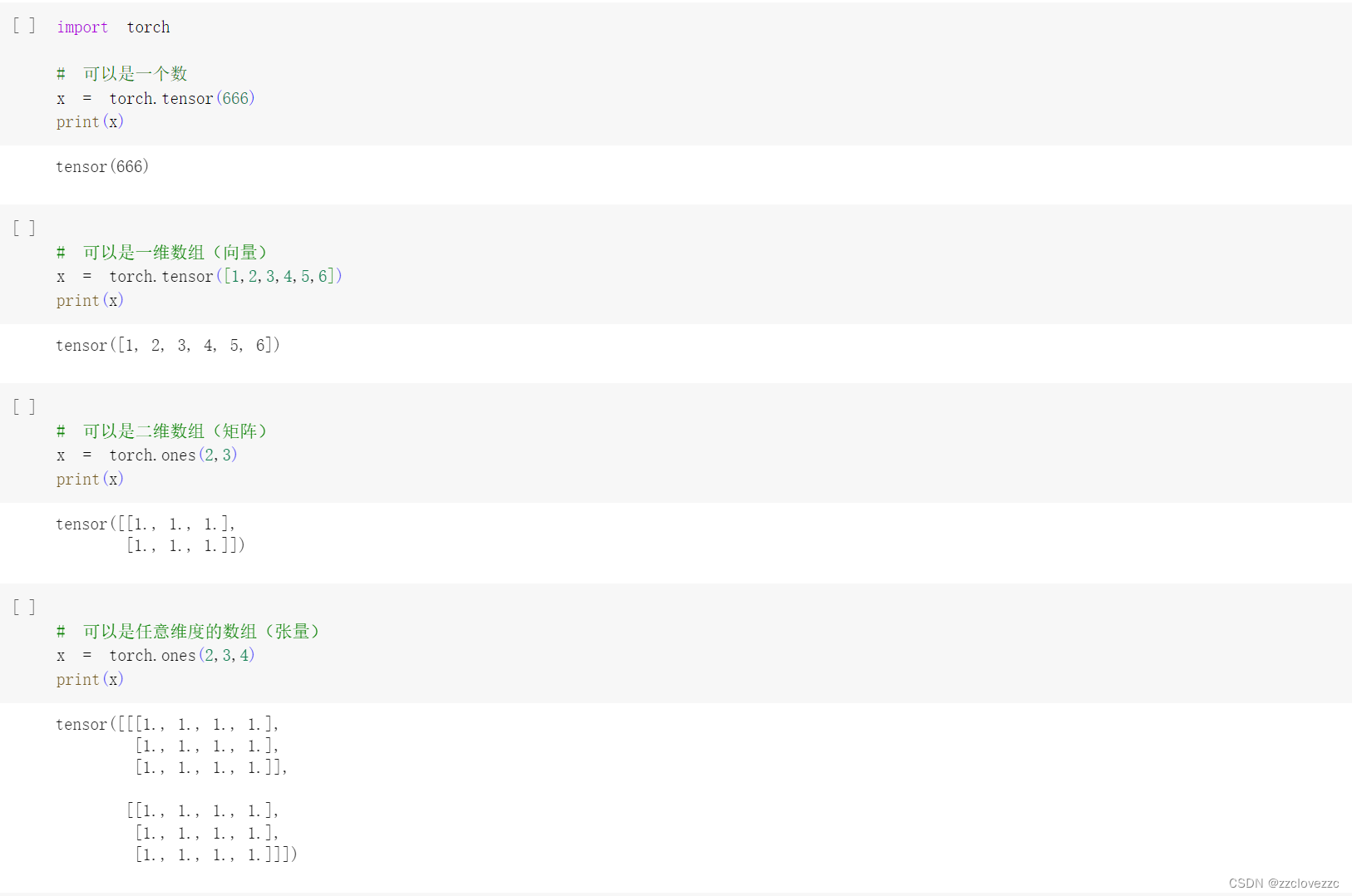
Tensor支持各种各样类型的数据,包括:torch.float32, torch.float64, torch.float16, torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64,此处代码展示了整数、向量、矩阵、张量等类型的定义及输出

创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm, 此处代码对空张量、随机初始化张量、类型为long的全0张量、基于现有张量创建的张量以及重新定义了dtype的张量进行了一个创建及输出
1.1.2 定义操作
凡是用Tensor进行各种运算的,都是Function
最终,还是需要用Tensor来进行计算的,计算无非是
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等
布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等

这里创建了一个2x4的tensor并输出了该tensor第一第二行以及整个tensor的size,并尝试返回不同所需的元素及属性
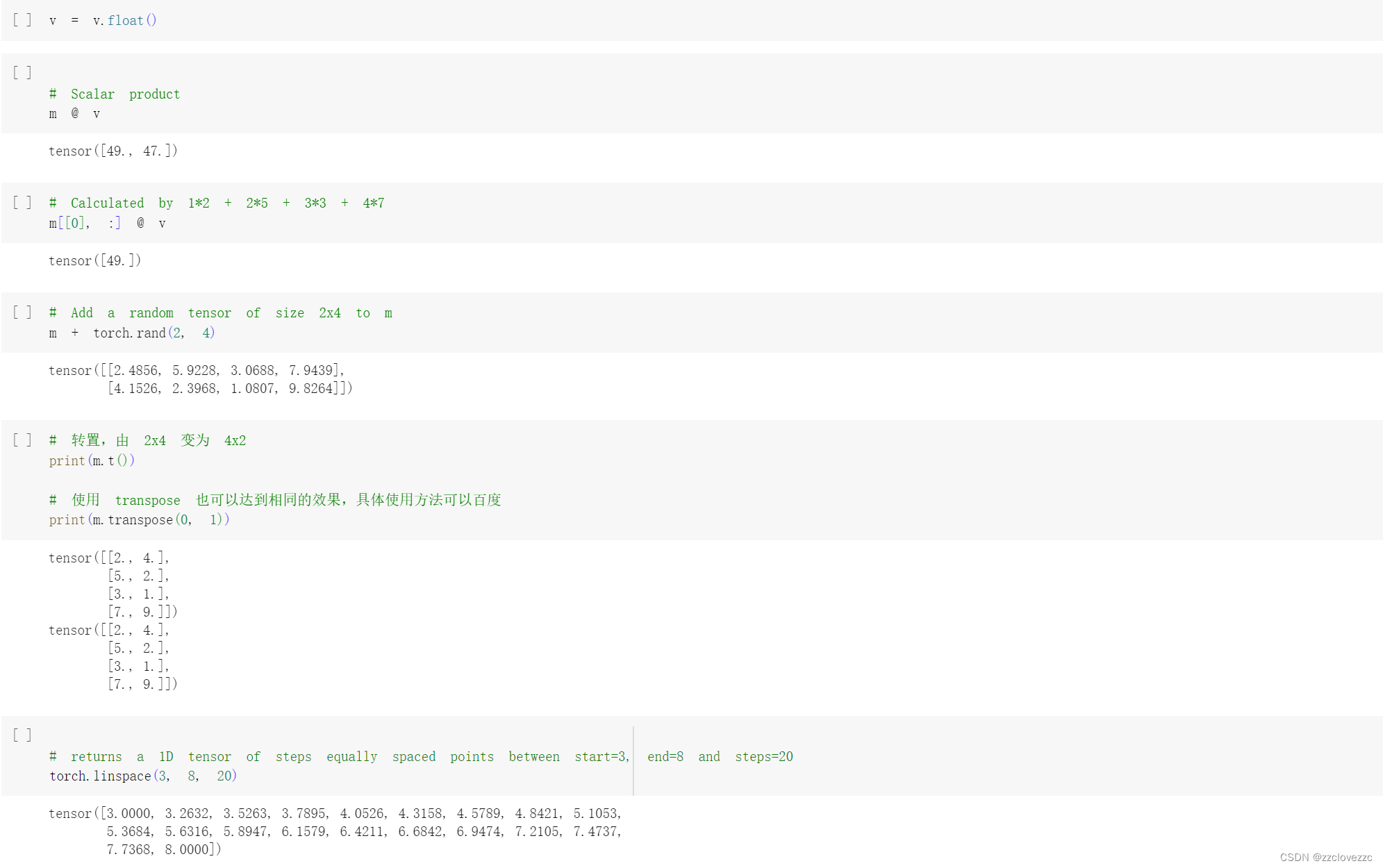 这里第一段代码是v和m的每一行逐个相乘的和,第二段代码是v和m的第一行相乘,第三段代码是m加上一个0到1均匀分布的随机数,第四段代码是转置的操作,第五段是生成20个3-8构成的等差数列
这里第一段代码是v和m的每一行逐个相乘的和,第二段代码是v和m的第一行相乘,第三段代码是m加上一个0到1均匀分布的随机数,第四段代码是转置的操作,第五段是生成20个3-8构成的等差数列
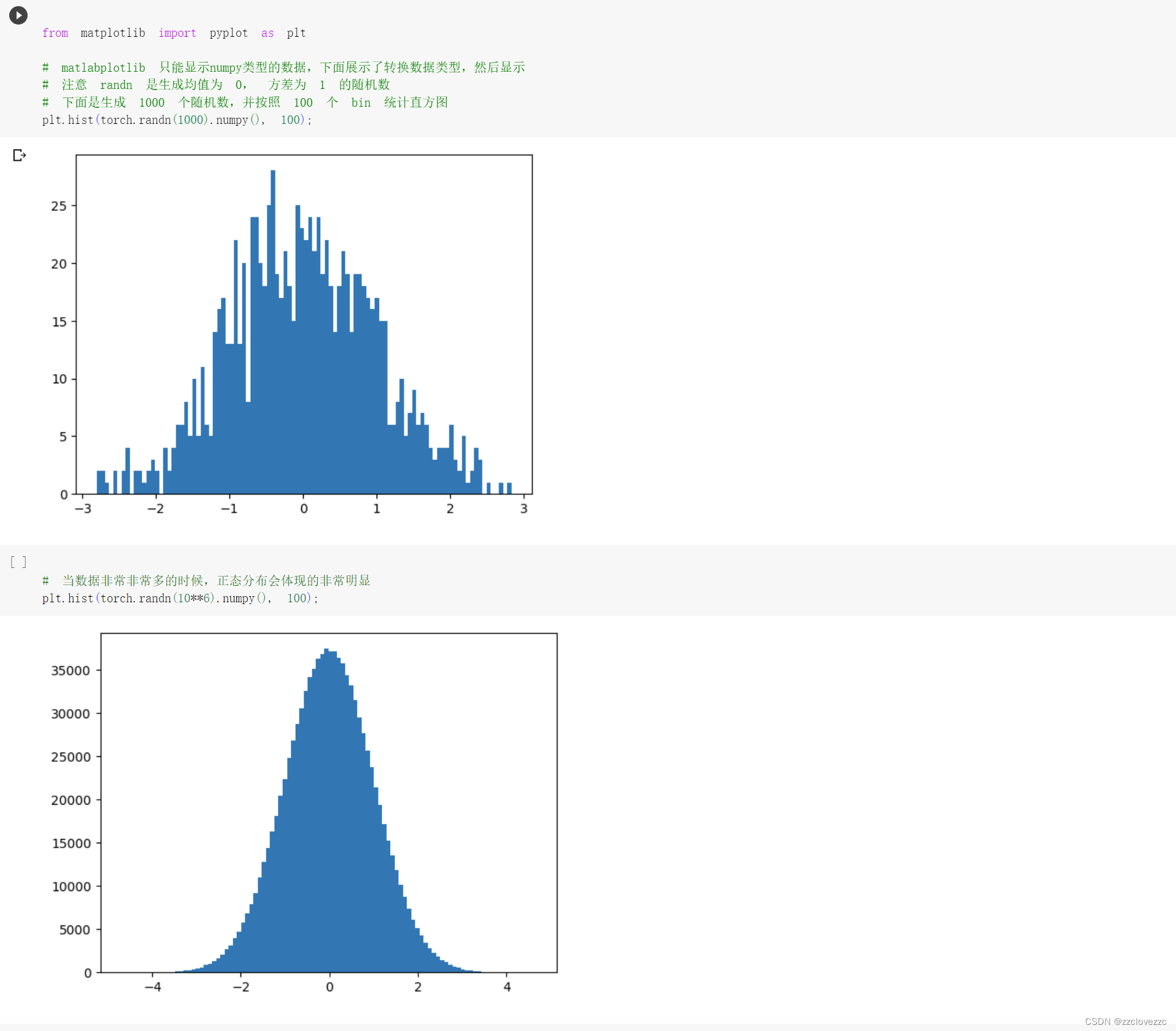 分别生成1000个和1000000个随机数,并按照100个bin统计直方图如图所示
分别生成1000个和1000000个随机数,并按照100个bin统计直方图如图所示
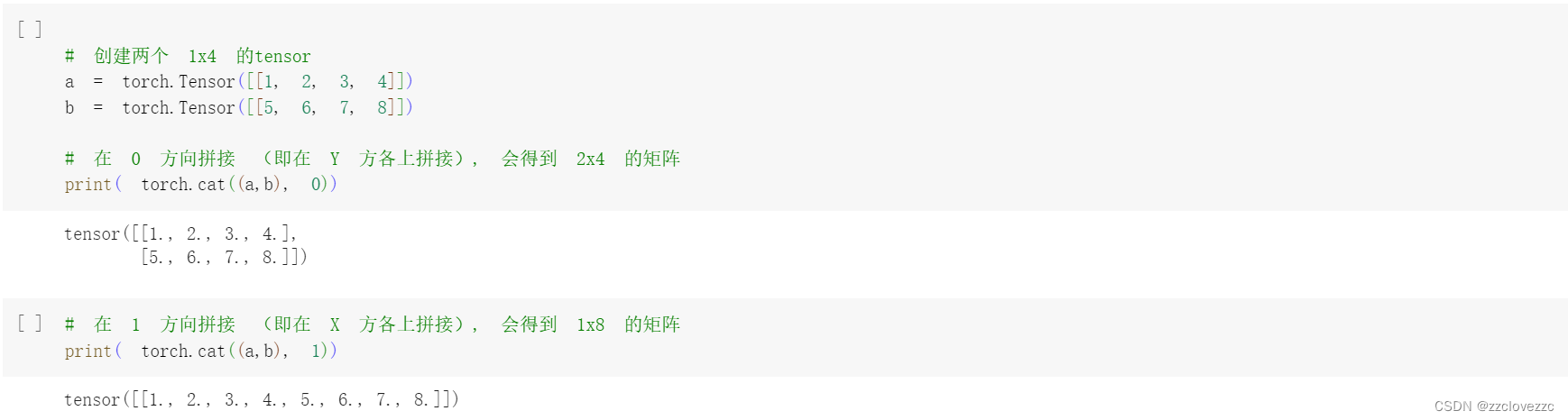 创建两个1x4的tensor,分别在0和1方向拼接,得到2x4和1x8的矩阵
创建两个1x4的tensor,分别在0和1方向拼接,得到2x4和1x8的矩阵
1.2 螺旋数据分类
先下载绘图函数到本地,然后再引入库和初始化重要参数,初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签,之后再对3000个样本特征进行初始化
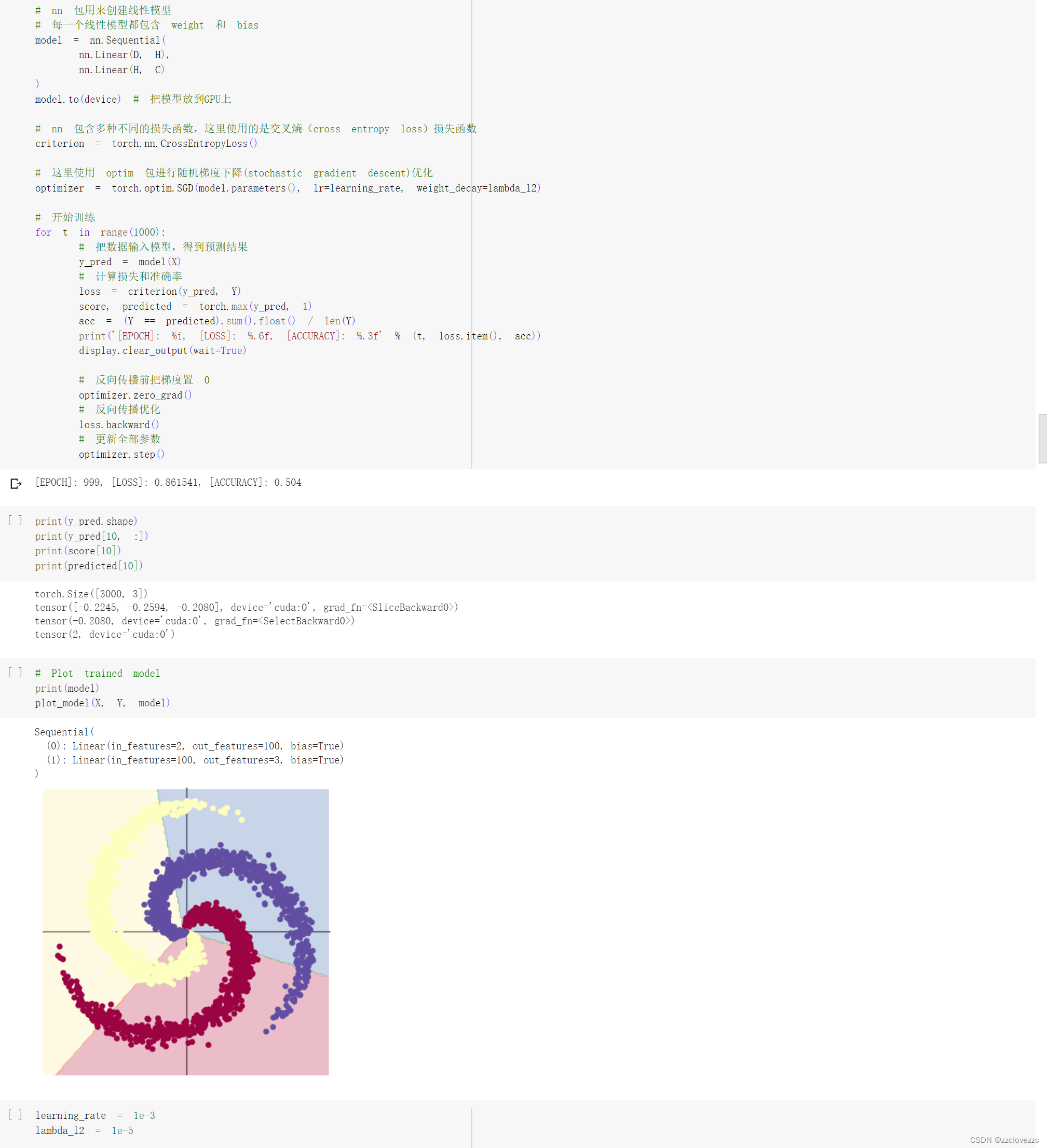
用线性模型进行预测,可以看到将数据输入模型后,训练1000次左右的损失率为86%,准确率为50%
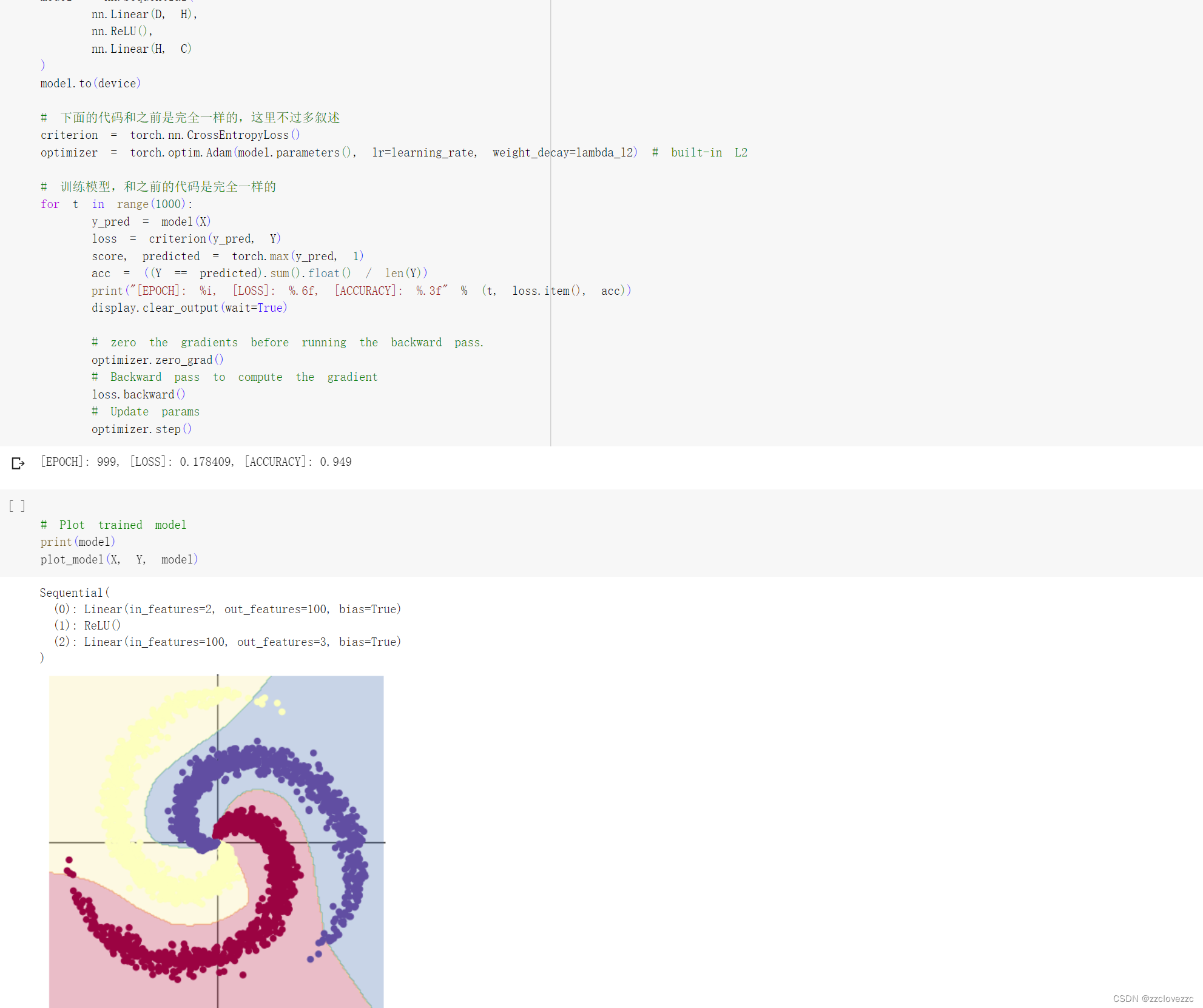
用两层神经网络模型进行预测,加入ReLU激活函数后,可以看到将数据输入模型后,训练1000次左右的损失率为18%,准确率为95%,准确率得到显著提高
第2部分 问题总结
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
(1)使用ReLU作为激活函数,加快了收敛速度。
(2)使用dropout避免过拟合。
(3)使用data augmentation扩增数据集。
(4)使用重叠池化,有利于防止过拟合。
(5)使用LRN增强了模型的泛化能力
(6)使用双GPU训练,加快了训练速度。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时AlexNet用了三种方法改进模型训练:1.数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。2.使用Dropout抑制过拟合3.使用ReLU激活函数减少梯度消失现象
2、激活函数有哪些作用?
(1)当输入为正时,导数为1,一定程度上改善了梯度消失问题,加速梯度下降的收敛速度;
(2)计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
(3)被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度可以非常高)
3、梯度消失现象是什么?
梯度消失现象是指在深度学习模型训练中,参数的梯度值变得非常小,接近于零,导致模型参数更新缓慢,从而影响模型的训练效果
4、神经网络是更宽好还是更深好?
神经网络一般来说不是越深越好,也不是越宽越好,并且由于计算量的限制或对于速度的需求,如何用更少的参数获得更好的准确率无疑是一个永恒的追求。就目前来说提升同样的效果需要增加的宽度远远超过需要增加的深度,一般情况下优先增加深度
5、为什么要使用Softmax?
与标准归一化相比,Softmax有一个不错的属性。它对神经网络的低刺激(思维模糊的图像)具有相当均匀的分布做出反应,而对高刺激(即大量的数字,认为图像清晰)的概率接近0和1。只要比例相同,标准规范化就无关紧要
6、SGD 和 Adam 哪个更有效?
Adam在很多情况下算作默认工作性能比较优秀的优化器,实现简单,计算高效,对内存需求少,参数的更新不受梯度的伸缩变换影响,超参数具有很好的解释性,且通常无需调整或仅需很少的微调。当然也要具体情况具体分析,SGD后期学习效率高,更容易达到全局最优解















 55
55











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









