







参考:
机器学习算法与Python实践之(七)逻辑回归(Logistic Regression) http://blog.csdn.net/dongtingzhizi/article/details/15962797
Logistic回归总结(非常好的机器学习总结资料)
http://download.csdn.net/detail/lewsn2008/654746
看了原文之后, 大致了解了logistic 回归的公式,和最佳回归系数的确定,以及原代码,看完之后 一头雾水。
看了上述两篇博客之后, 可以理解
Stanford的Andrew Ng老师的机器学习公开课中关于Logistic Regression的讲解,结合《机器学习实战》中的LogisticRegression代码,发现python 的代码非常的简洁。
《机器学习实战》一书在介绍原理的同时将全部的算法用源代码实现,非常具有操作性,可以加深对算法的理解,但是美中不足的是在原理上介绍的比较粗略,很多细节没有具体介绍。所以,对于没有基础的朋友(包括我)某些地方可能看的一头雾水,需要查阅相关资料进行了解。所以说,该书还是比较适合有基础的朋友。
基本的函数形式
该函数的输出必须是两个值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
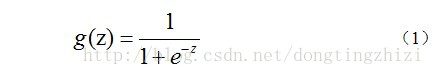
对应的函数图像是一个取值在0和1之间的S型曲线(图1)。
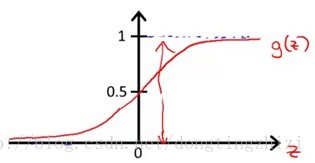
多项式方程式,线性方程:
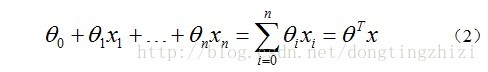
构造预测函数为:
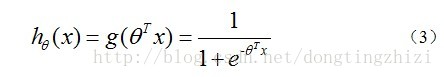
hθ(x)函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
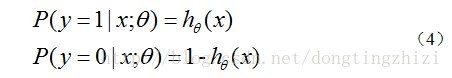
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
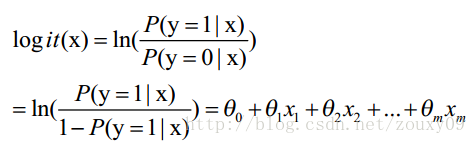
对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离。
以上算法书,都只讲到这里(我也没有深究,所以一直都在基础入门。)
---------------------------------
以下是概率论的知识
有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
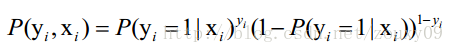
上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):
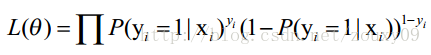
在这里可以把
上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数,使上式取得最大值。
对上述函数求对数:
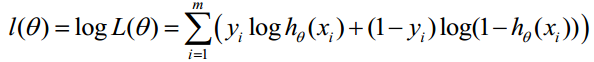
最大似然估计就是求使上式取最大值时的θ,这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。在Andrew Ng的课程中将J(θ)取为下式,即:J(θ)=-(1/m)l(θ),J(θ)最小值时的θ则为要求的最佳参数。通过梯度下降法求最小值。θ的初始值可以全部为1.0,更新过程为:
(j表样本第j个属性,共n个;a表示步长--每次移动量大小,可自由指定)
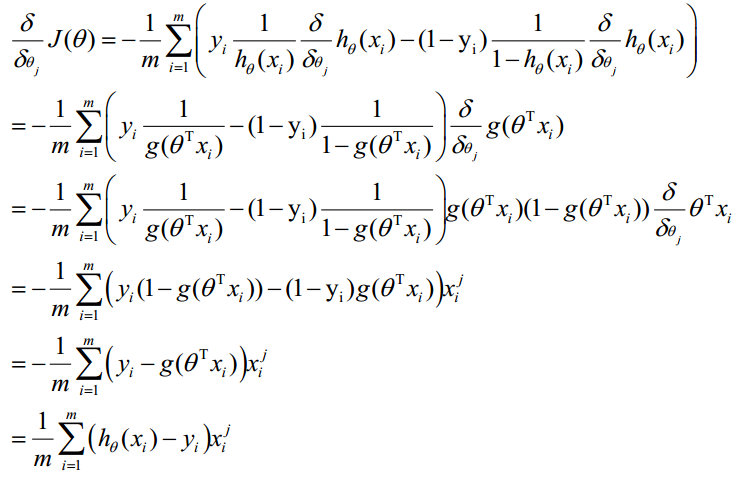
g(z)=11+e−z g(z)=11+e−z是sigmoid激活函数,对两个等式分别求导,有
---------------------------------------
g(z)=11+e−z g(z)=11+e−z是sigmoid激活函数,对两个等式分别求导,有
g(z)=11+e−z g(z)=11+e−z是sigmoid激活函数,对两个等式分别求导,有
因此,θ(可以设初始值全部为1.0)的更新过程可以写成:
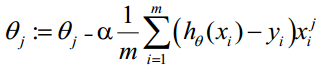
g(z)=11+e−z g(z)=11+e−z是sigmoid激活函数,对两个等式分别求导,有
g
(i表示第i个统计样本,j表样本第j个属性;a表示步长)
h(x i)- y(i) = error
向量化Vectorization求解
Vectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。如上式,Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization。下面介绍向量化的过程:
1、 A = x θ
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知hθ(x)-y可由
g(A)-y一次计算求得。
θ更新过程可以改为:
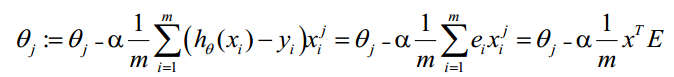
综上所述,Vectorization后θ更新的步骤如下:
(1)求A=X*θ(此处为矩阵乘法,X是(m,n+1)维向量,θ是(n+1,1)维列向量,A就是(m,1)维向量)
(2)求E=g(A)-y(E、y是(m,1)维列向量)
(3)求 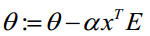
--------------------------------------------------------------------------------------------------------
到这里,这个算法的推导算是结束了
- def gradAscent(dataMatIn,classLabels):
- dataMatrix = mat(dataMatIn)
- labelMat = mat(classLabels).transpose()
- m,n = shape(dataMatrix)
- alpha = 0.001
- maxIteration = 500
- weights = ones((n,1))
- for k in range(maxIteration):
- h = sigmoid(dataMatrix * weights)
- error = (labelMat - h)
- weights = weights + alpha * dataMatrix.transpose() * error
- return weights
---------------------------------------------------------------------------------------------
Overfitting通常指当模型中特征太多时,模型对训练集数据能够很好的拟合(此时代价函数 J(θ) J(θ)接近于0),然而当模型泛化(generalize)到新的数据时,模型的预测表现很差。
Overfitting的解决方案
- 减少特征数量:
- 人工选择重要特征,丢弃不必要的特征
- 利用算法进行选择(PCA算法等)
- Regularization
- 保持特征的数量不变,但是减少参数 θj θj的数量级或者值
- 这种方法对于有许多特征,并且每种特征对于结果的贡献都比较小时,非常有效
g(z)=11+e−z g(z)=11+e−z是sigmoid激活函数,对两个等式分别求导,有















 9443
9443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









