







还记得在PCA中是怎样做的吗?简单来说,是将数据映射到方差比较大的方向上,最后用数学公式推导出矩阵的前TopN的特征向量,这里的方差可以理解为数据内部的离散程度。而LDA不同于PCA的是它是一种有监督的降维方法。下面举一个小例子来直观的说明PCA和LDA的不同降维方法。
例子
如下图所示为两类数据集:
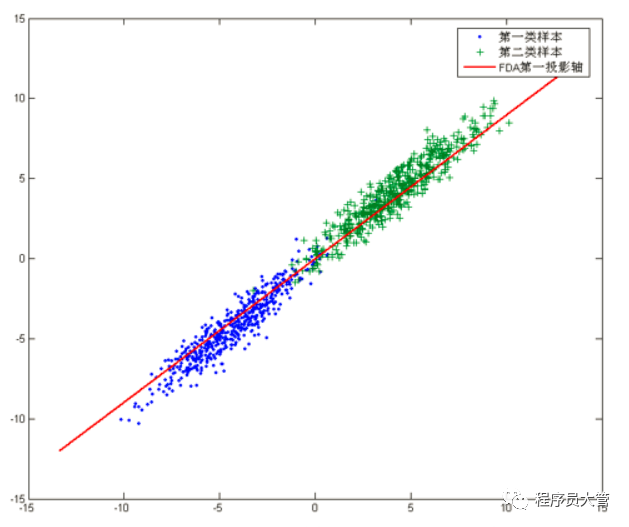
PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。样本的方差越大表示样本的多样性越好。x轴和y轴都不是最理想的投影,故上图中PCA会将数据投影在红色的轴上。
如下图所示数据集:
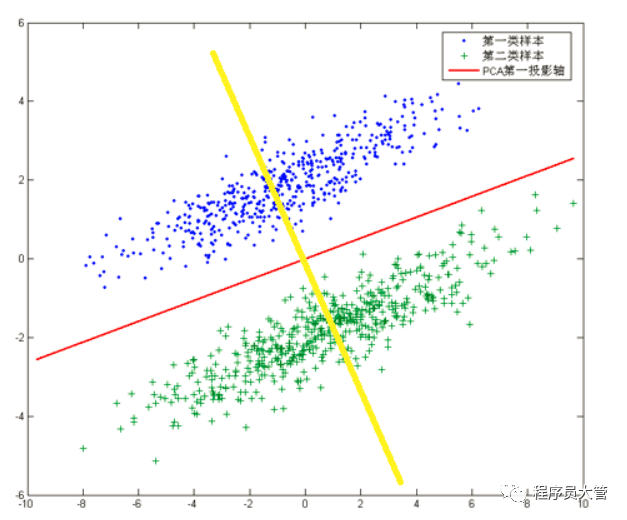
若根据PCA进行降维,将会把数据映射到红色直线上,这样做投影确实方差最大,但是这样做投影之后两类数据样本将混合在一起,将不再线性可分,甚至是不可分的。上面的这个数据集如果使用LDA降维,找出的投影方向就是黄色直线所在的方向,这样的方法在降维之后,可以很大程度上保证了数据的线性可分的。
LDA降维
从上述例子中可以看到,LDA可以用来对数据分类进行处理。为了说明白LDA的来龙去脉,还是以最简单的二分类问题为例。
假设有C1和C2两个样本数据集,其均值分别为:
μ 1 = 1 N 1 ∑ x ∈ C 1 x μ 2 = 1 N 2 ∑ x ∈ C 2 x \begin{aligned}\mu_1&=\frac{1}{N_1}\sum_{x\in C_1}x\\\\\mu_2&=\frac{1}{N_2}\sum_{x\in C_2}x\end{aligned} μ1μ2=N11x∈C1∑x=N21x∈C2∑x
投影之后的类间距离为:
D
(
C
1
,
C
2
)
=
∣
∣
μ
1
~
−
μ
2
~
∣
∣
2
2
\mathrm{D}(C_{1},C_{2})=||\widetilde{\mu_{1}}-\widetilde{\mu_{2}}||_{2}^{2}
D(C1,C2)=∣∣μ1
−μ2
∣∣22
其中成和或为两个类中心在方向上的投影向量
μ 1 ~ = ω T μ 1 μ 2 ~ = ω T μ 2 \begin{array}{l}\widetilde{\mu_1}=\omega^T\mu_1\\\widetilde{\mu_2}=\omega^T\mu_2\end{array} μ1 =ωTμ1μ2 =ωTμ2
将上述两式合并,求最大间距可以表示为:
{ max ω ∣ ∣ ω T ( μ 1 − μ 2 ) ∣ ∣ 2 2 s . t . ω T ω = 1 \left\{\begin{matrix}\max_\omega||\omega^T(\mu_1-\mu_2)||_2^2\\\\s.t.&\omega^T\omega=1\end{matrix}\right. ⎩ ⎨ ⎧maxω∣∣ωT(μ1−μ2)∣∣22s.t.ωTω=1
当 ω 方向与(μ1-μ2)一致的时候,该距离达到最大值。从所举的例子图中也能看出,我LDA的期望是使得两个类间的距离最大,类内的距离最小。
由于不同的类别是在同一个数据集中,所以类内距离也可以定义为不同类的方差之和。故可以定义LDA的目标函数为:
max ω J ( ω ) = ∥ ω T ( μ 1 − μ 2 ) ∥ 2 2 D 1 + D ’ 2 \max_{\omega}J(\omega)=\frac{\left\|\omega^{\mathrm{T}}\left(\mu_{1}-\mu_{2}\right)\right\|_{2}^{2}}{D_{1}+D_{\text{'}2}} maxωJ(ω)=D1+D’2∥ωT(μ1−μ2)∥22
其中D1和D2分别为两个类的类内距离,分别为:
D 1 = ∑ x ∈ C 1 ω T ( x − μ 1 ) ( x − μ 1 ) T ω D 2 = ∑ x ∈ C 2 ω T ( x − μ 2 ) ( x − μ 2 ) T ω \begin{gathered} D_{1} =\sum_{x\in C_{1}}\omega^{T}(x-\mu_{1})(x-\mu_{1})^{T}\omega \\ D_{2} =\sum_{x\in C_{2}}\omega^{T}(x-\mu_{2})(x-\mu_{2})^{T}\omega \end{gathered} D1=x∈C1∑ωT(x−μ1)(x−μ1)TωD2=x∈C2∑ωT(x−μ2)(x−μ2)Tω
将D1和D2分别代入,J(ω)可以表示为:
J ( ω ) = ω T ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T ω ∑ x ∈ C l ω T ( x − μ i ) ( x − μ ) T ϱ J(\omega)=\frac{\omega^\mathrm{T}\left(\mu_1-\mu_2\right)(\mu_1-\mu_2)^\mathrm{T}\boldsymbol{\omega}}{\sum_{x\in C_l}\boldsymbol{\omega}^\mathrm{T}\left(x-\mu_i\right)(x-\boldsymbol{\mu})^\mathrm{T}\boldsymbol{\varrho}} J(ω)=∑x∈ClωT(x−μi)(x−μ)TϱωT(μ1−μ2)(μ1−μ2)Tω
为了简化上述公式,这里定义类间距离散度SB和类内距离散度SW分别为:
S B = ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T S w = ∑ x ∈ C i ( x − μ i ) ( x − μ i ) T \begin{aligned}S_B&=(\mu_1-\mu_2)(\mu_1-\mu_2)^T\\S_w&=\sum_{x\in C_i}(x-\mu_i)(x-\mu_i)^T\\\end{aligned} SBSw=(μ1−μ2)(μ1−μ2)T=x∈Ci∑(x−μi)(x−μi)T
故可以将式子简化为:
J ( ω ) = ω T S B ω ω T S w ω J(\omega)=\frac{\omega^\mathrm{T}S_B\omega}{\omega^\mathrm{T}S_w\omega} J(ω)=ωTSwωωTSBω
下面使用烂大街而有效的方法最大化J(ω),对ω求偏导,并令其为0,得到:
( ω T S w ω ) S B ω = ( ω T S B ω ) S W ω (\boldsymbol{\omega}^\mathrm{T}\boldsymbol{S}_w\boldsymbol{\omega})\boldsymbol{S}_B\boldsymbol{\omega}=(\boldsymbol{\omega}^\mathrm{T}\boldsymbol{S}_B\boldsymbol{\omega})\boldsymbol{S}_W\boldsymbol{\omega} (ωTSwω)SBω=(ωTSBω)SWω
下面对公式稍作变化,就可以发现一个令人惊讶的结果:
$S_B\omega=\frac{(\omegaTS_w\omega)}{(\omegaTS_B\omega)}S_w\omega $
将Sw乘到左边:
S w − 1 S B ω = ( ω T S w ω ) ( ω T S B ω ) ω S w − 1 S B ω = λ ω \begin{aligned}S_w^{-1}S_B\omega&=\frac{(\omega^TS_w\omega)}{(\omega^TS_B\omega)}\omega\\\\S_w^{-1}S_B\omega&=\lambda\omega\end{aligned} Sw−1SBωSw−1SBω=(ωTSBω)(ωTSwω)ω=λω
我们居然把目标函数变成了求矩阵的特征值,而投影的方向就是这个特征值对应的特征向量。故对于二分类问题在不考虑投影长度的情况下,我们只要求得样本的均值和类内方差就可以计算出投影方向。
回顾PCA的过程,是不是和LDA很相似呢,但是其原理却不一样,对于无监督学习使用PCA,有监督学习使用LDA。
本的均值和类内方差就可以计算出投影方向。
回顾PCA的过程,是不是和LDA很相似呢,但是其原理却不一样,对于无监督学习使用PCA,有监督学习使用LDA。














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









