







 该博客介绍了如何使用分治策略解决ZJOI2012竞赛中的一道数列题目。由于普通DFS会导致超时,作者提出了使用记忆化搜索和更稳定的分治算法。在分治过程中,根据数列性质,通过讨论奇偶性更新p和q的值。时间复杂度为O(T*log2(n)*高精度)。博客提供了采用分治法的示例程序。
该博客介绍了如何使用分治策略解决ZJOI2012竞赛中的一道数列题目。由于普通DFS会导致超时,作者提出了使用记忆化搜索和更稳定的分治算法。在分治过程中,根据数列性质,通过讨论奇偶性更新p和q的值。时间复杂度为O(T*log2(n)*高精度)。博客提供了采用分治法的示例程序。
题目概述
一个数列,其中A[0]=0,A[1]=1,A[2*i]=A[i],A[2*i+1]=A[i]+A[i+1],给出T个n,求A[n]。
解题报告
一看就是高精度分治,但是普通dfs肯定超时(普通dfs次数=答案,而答案近似n也就是10^100),用map进行记忆化搜索竟然可以过(简单证明后面再讲)。不过这里有更加稳定的分治算法:
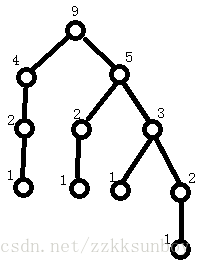
随便观察一个n(比如9)的dfs路径,不难发现有大量重复计算,而最终归根到底是1的个数决定了答案。继续观察,会发现:知道0 1之后,可以得到1 2,知道1 2之后,可以得到2 3,知道2 3之后,可以得到4 5,得到4 5之后,就可以算出9。我们可以定义p表示x-1的值,q表示x的值,比如当x为1时,p=A[0]=0,q=A[1]=1。
然后我们需要推出通用的处理方法来利用p和q,不难想到x要分奇偶讨论:
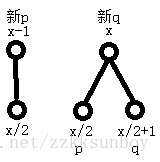
1.x为奇数
我们假设已经求好了下面的p和q,现在要把p和q对应到x-1和x上来,不难发现p不变,而q=p+q。
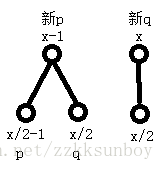
2.x为偶数
同理,不难发现q不变,而p=p+q。
所以对于一个x,进行Dfs((x+1)/2)(ps:(x+1)/2就不用判断奇偶性了),得到下一层的p和q(递归到x=1为止),根据上述方法求得新p和q,最后根据定义,q就是A[x]。
时间复杂度:O(T*log2(n)*高精度)
最后,关于记忆化:通过上方讨论就可以发现每隔1,2层就会出现重复,所以使用记忆化就可以把许多二叉做成一叉,效率近似log2(n)但有差距,不过实际表现非常不错(特别是多组数据可能会减少许多组),也是一种可行的策略。
示例程序
#include<cstdio>
#include<cstring> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









