






前 言
国内 AI 的发展也是越来越好了,又一款国内的图像生成模型来了,由北京人工智能研究院开源的统一图像生成模型:OmniGen。
OmniGen 不仅仅是可以简单的文生图,还可以在保持图像一致性的前提下进行图像编辑,而且图像编辑功能相当强大。
可以把整个人物或者是物体迁移到新的生成图像中,以人物为例,不仅仅是简单的换脸,可以把整个人物在保持一致性的情况下融入新的场景中,并且根据文本描述对图像中的人物进行编辑。
而且可以多个人物或者物体进行一致性操作。不需要额外的换脸插件或者是 ControlNet,OmniGen 本身就支持,功能相当惊艳。
好了,话不多说,我们直接开整。
这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

文生图我们就简单的展示一下,今天主要介绍 OmniGen 的一致性图像编辑功能。
生成人物质量还是可以的。

接下来,我们来看看图像编辑功能,左边是参考图,右边是最终出图。
提示词也很简单:The woman in image_1 waves her hand happily in the crowd。
图一中的女人在人群中挥手。
整体来说,人物的一致性保持的还是不错的,包括发型、妆容以及着装。

换个风格继续试试,给人物戴上一个眼镜,人物的整体风格装饰保持的都是不错的。

再换个风格,给人物戴上一个帽子,安排在海滩边漫步。一致性保持的也是相当不错。

以上只是图像编辑的简单应用,接下来,我们来具体分析一下如果使用,以及更多的使用方式。
首先是安装,直接在 ComfyUI 管理器中搜索:OmniGen-ComfyUI,安装重启就可以了,第一次运行工作流的时候会自动下载模型,大概 15G 左右。或者也可以直接把听雨网盘里的模型复制到指定目录下。
工作流很简单,OmniGen 的节点就只有一个,文生图和图像编辑公用一个节点。
文生图的工作流就下边三个节点,输入提示词,生成图像,预览图像。
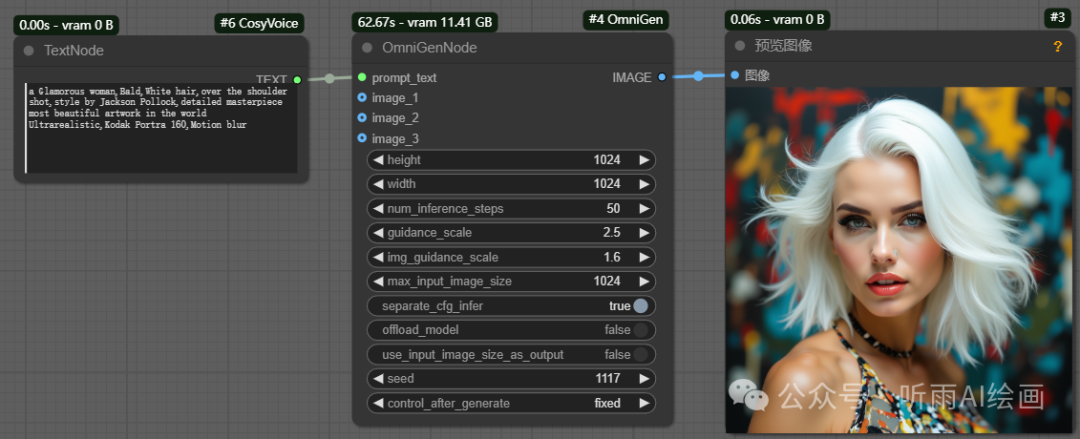
图像编辑是基于文生图工作流的,可以看到 OmniGenNode 节点中还有三个 image 节点,这个就是用来输入参考图像的地方,最多可以输入三个参考图像。
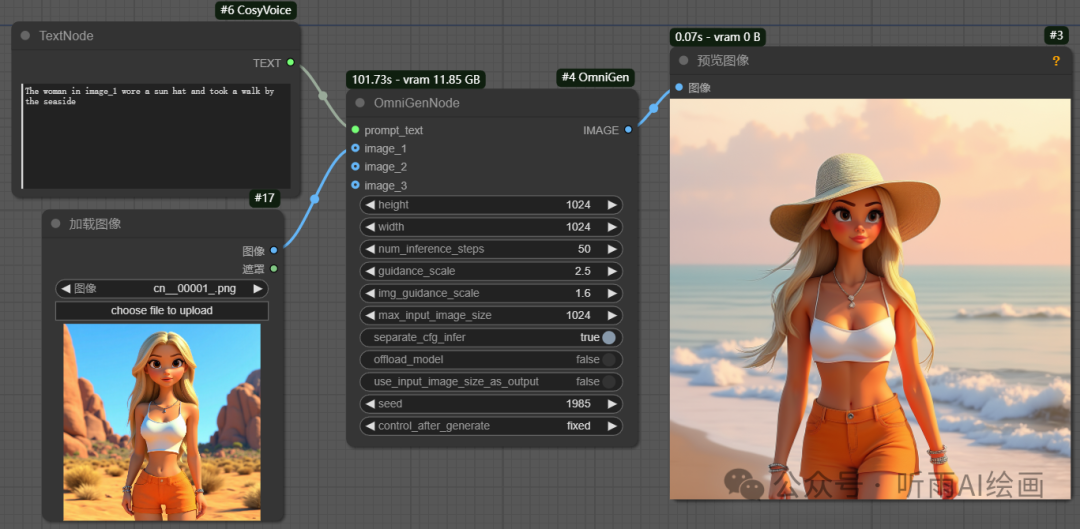
第一种简单的用法就是,输入一张参考图,然后需要在提示词中指明使用了第一张图像。
比如这里的提示词:The woman in image_1 wore a sun hat and took a walk by the seaside。
提示词中的 image_1 就是代表着图一参考图,需要使用图二图三那就依次指定 image_2、image_3。
The woman in image_1 就是图一中的女人,后边就写想要这个人物干什么就可以了。
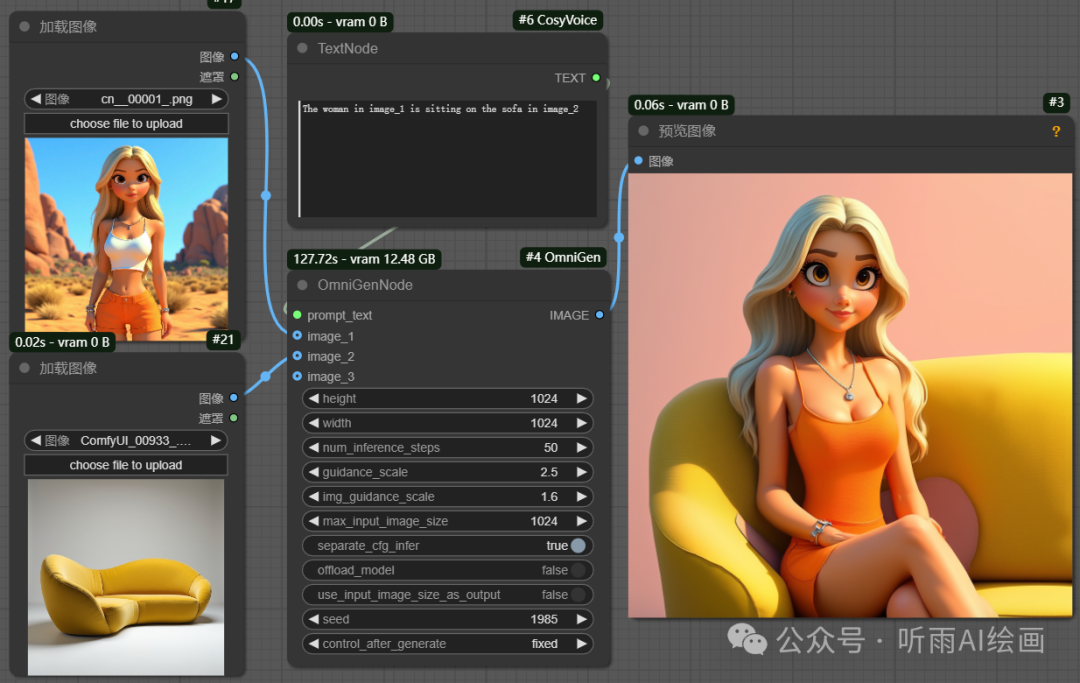
可以输入多张参考图,然后把两张参考图结合在一张图片中。
这里的提示词:The woman in image_1 is sitting on the sofa in image_2,翻译一下就是图一中的女人坐在图二中的沙发上。
可以看到不管是人物还是物品的一致性保持的都还是不错的,这里最多可以参考三张图片。
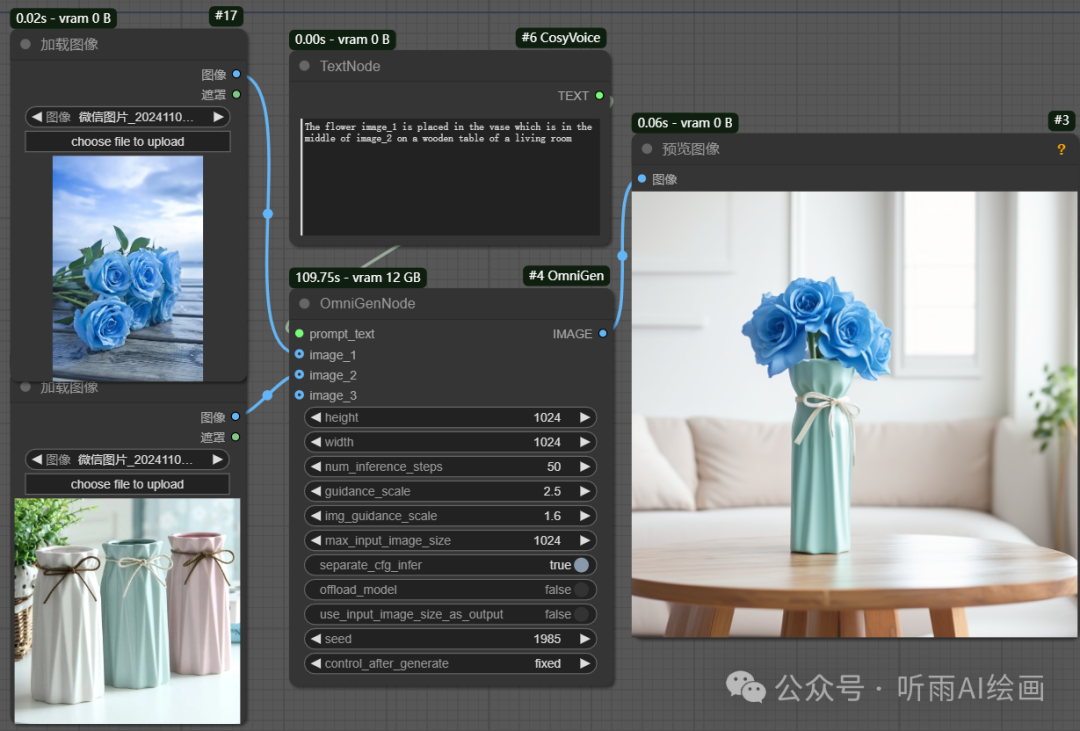
这里的参考图也可以都是人物或者都是物品,比如把指定的花放到指定的瓶子里。
提示词:The flower image_1 is placed in the vase which is in the middle of image_2 on a wooden table of a living room
除此以外,还可以直接检测图像中的人物骨骼图。
提示词:Detect the skeleton of human in this image:image_1。
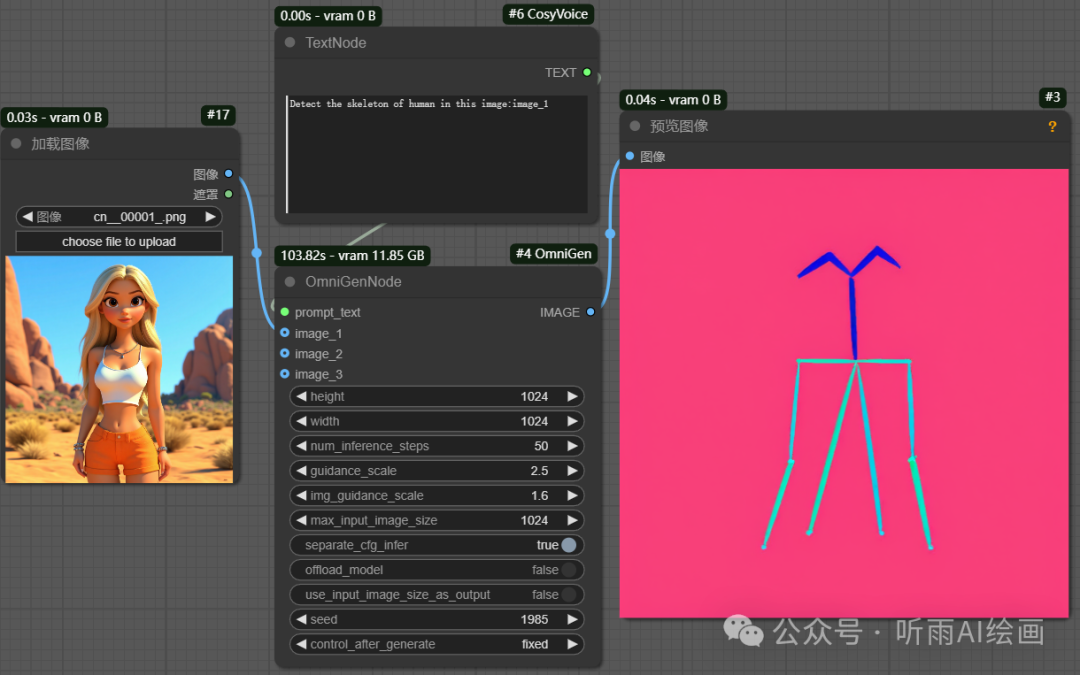
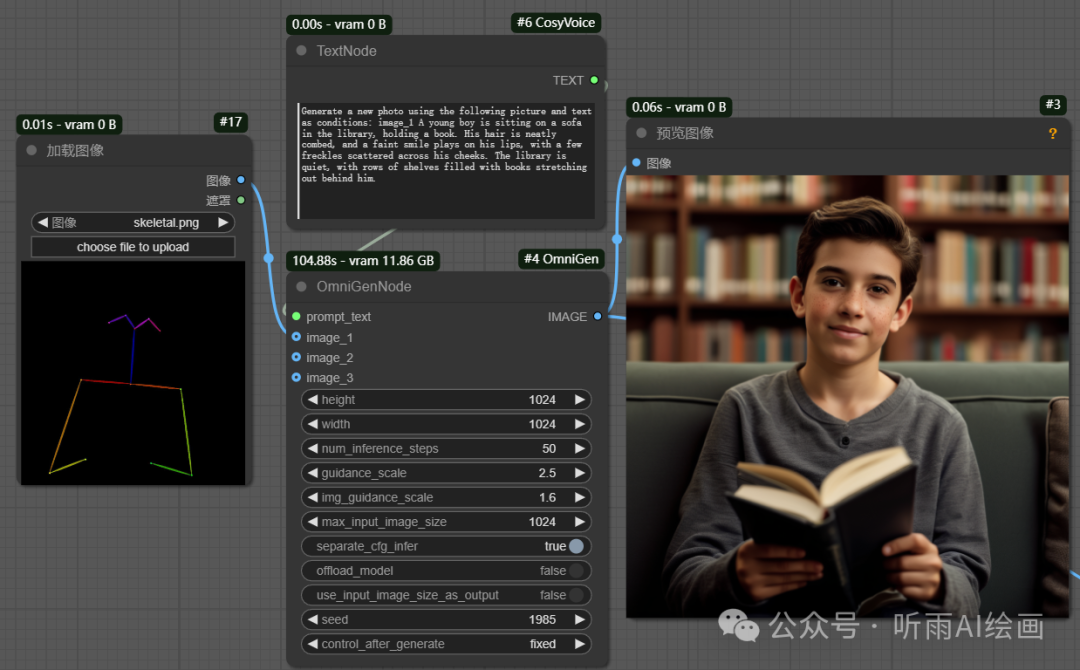
然后根据骨骼图和文字描述直接生成图片。
提示词:Generate a new photo using the following picture and text as conditions: image_1 A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him
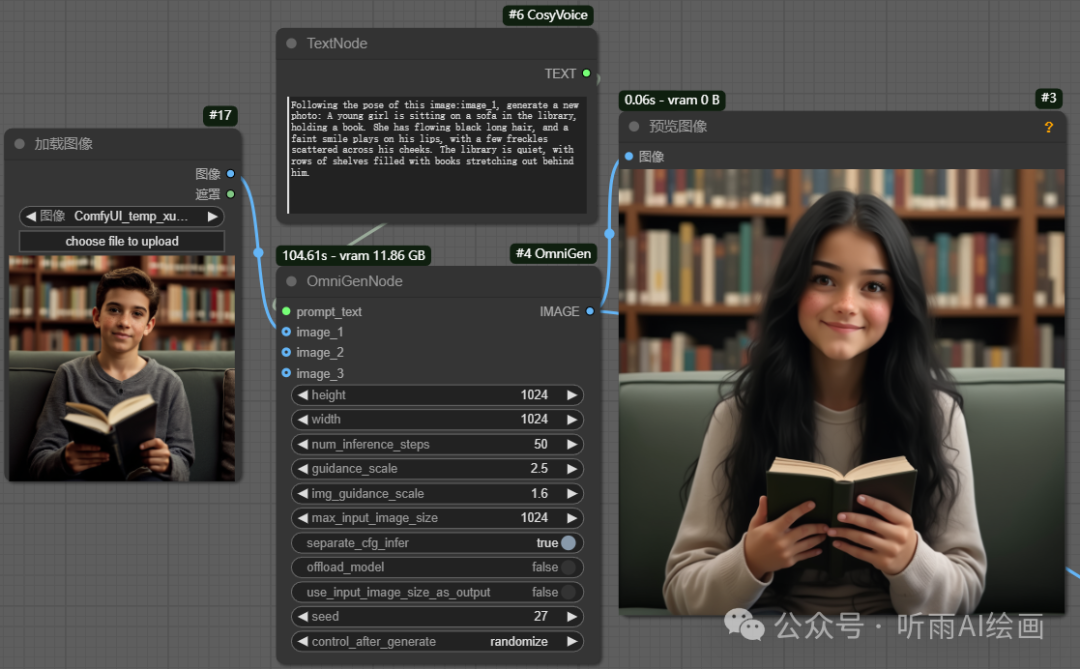
也可以直接通过参考图片来生成姿势一致的图片。
提示词:Following the pose of this image:image_1, generate a new photo: A young girl is sitting on a sofa in the library, holding a book. She has flowing black long hair, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him.
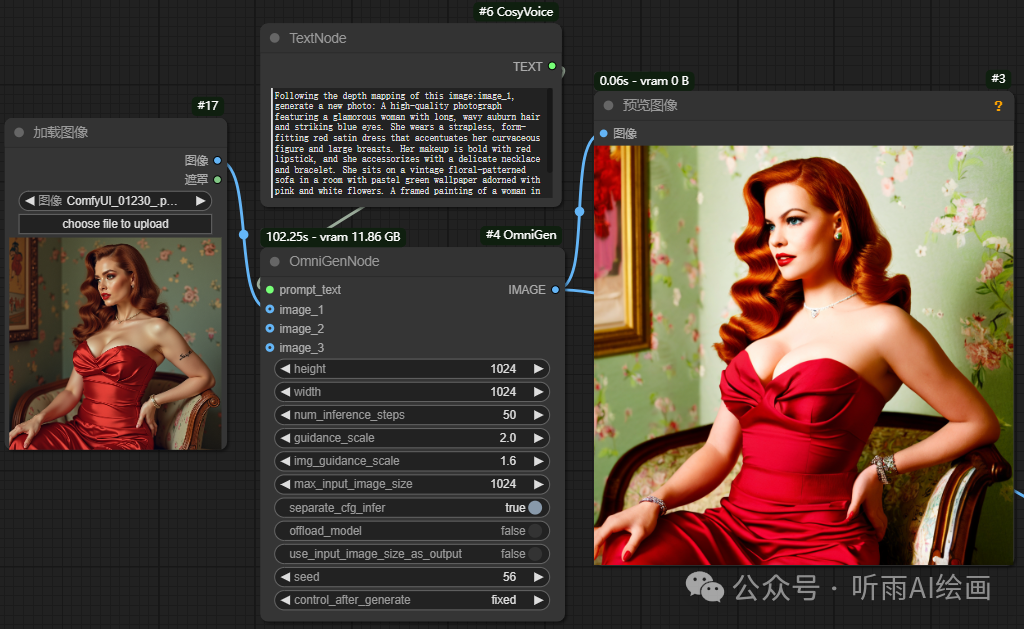
还可以根据参考图的深度图来生成图片,不过尝试了好几次,虽然功能是实现了,但是图片质量就差些意思了。
提示词:Following the depth mapping of this image:image_1, generate a new photo: A high-quality photograph featuring a glamorous woman with long, wavy auburn hair and striking blue eyes. She wears a strapless, form-fitting red satin dress that accentuates her curvaceous figure and large breasts. Her makeup is bold with red lipstick, and she accessorizes with a delicate necklace and bracelet. She sits on a vintage floral-patterned sofa in a room with pastel green wallpaper adorned with pink and white flowers. A framed painting of a woman in a red dress hangs on the wall. The overall aesthetic is very high, evoking a mid-20th century Hollywood glamour style.
总的体验下来,图像的一致性迁移还是做得相当不错的,模型自带的类似于 pose 和 depth 的控制功能,出图质量不太稳定。希望后续可以有更好的版本出现。
不过出图速度也是一个硬伤,和刚出来的 Flux 有的一拼。显存大概需要 12G 的样子。
好了,今天的分享就到这里了,感兴趣的小伙伴可以去试试哦!
网盘链接扫下图:
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3860
3860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









