






目录
Unsupervised Learning: Linear Methods
Unsupervised Learning: Neighbor Embedding
① Locally Linear Embedding (LLE)
③ T-distriputed Stochastic NeighborEmbedding (t-SNE)
Dimension Reduction(来源Wikipedia):降维或降维是将数据从高维空间转换到低维空间,以便低维表示保留原始数据的一些有意义的属性,理想情况下接近其intrinsic dimension。由于许多原因,在高维空间中工作是不可取的。由于维数灾难,原始数据通常是稀疏的,并且分析数据通常在计算上是难以处理的(难以控制或处理)。方法通常分为线性方法和非线性方法,也可以分为特征选择和特征提取。降维可以用于降噪、数据可视化、聚类分析,或作为促进其他分析的中间步骤。
自编码器(Auto-encoder)可以用来学习非线性降维函数和编码以及从编码到原始表示的逆函数。
主成分分析(PCA)是降维的主要线性技术,它将数据线性映射到低维空间,从而使低维表示中的数据方差最大化。
t分布随机邻域嵌入(t-SNE)是一种用于高维数据集可视化的非线性降维技术。
Unsupervised Learning: Linear Methods
Unsupervised Learning - Linear Methods (Linear Dimension Reduction)
Unsupervised Learning分为两种:
① Clustering & Dimension Reduction(化繁为简);
② Generation(无中生有)
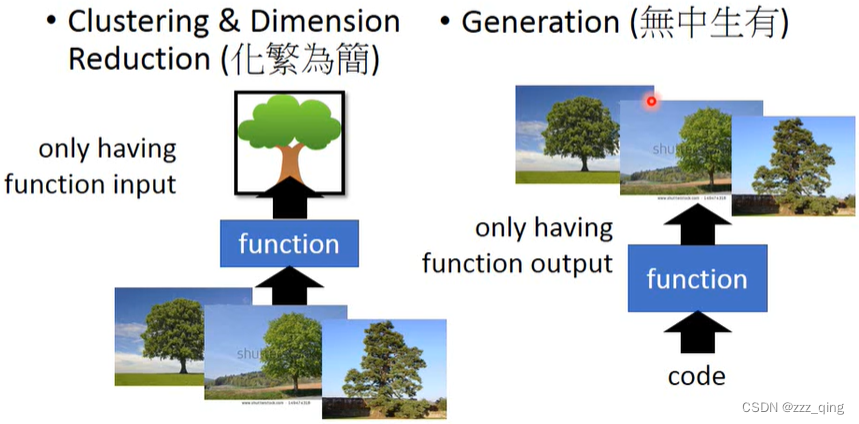
PCA这小节笔记focus在linear的Dimension Reduction上。
Clustering:
how many clusters do we need?要根据经验去决定。

clustering最常用的方法:K-means

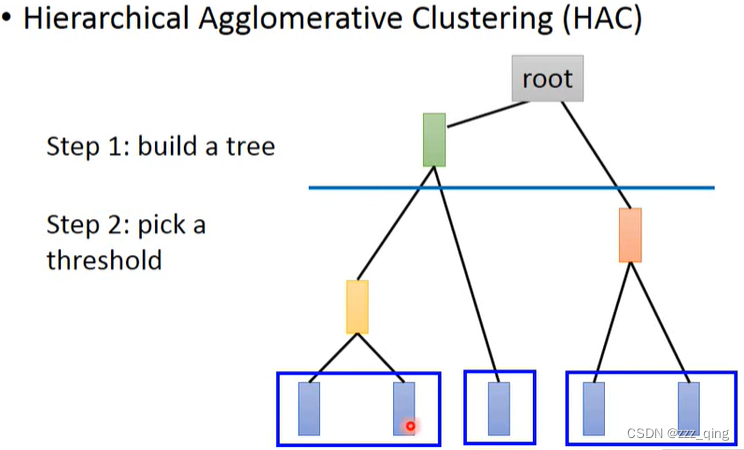
HAC和K-means最大区别:如何决定cluster的数目
Distributed Representation:
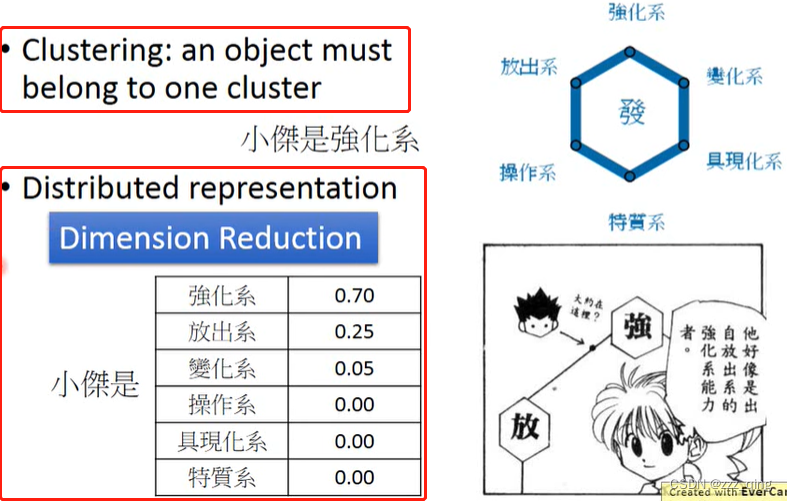
Dimension Reduction:
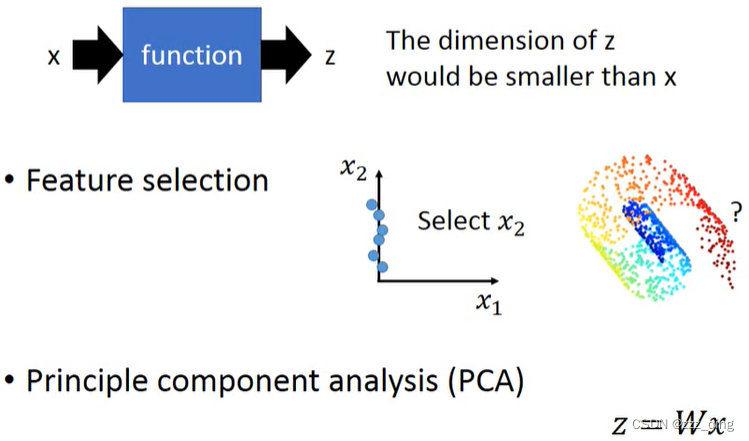
PCA
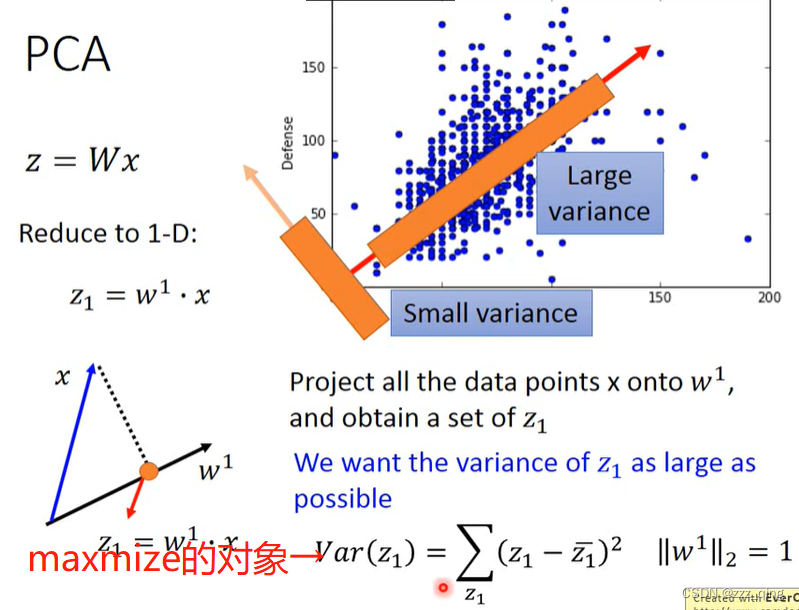
如何计算得到w1、w2......wi —— 经典方法:Lagrange multiplier

下面以计算w1为例:

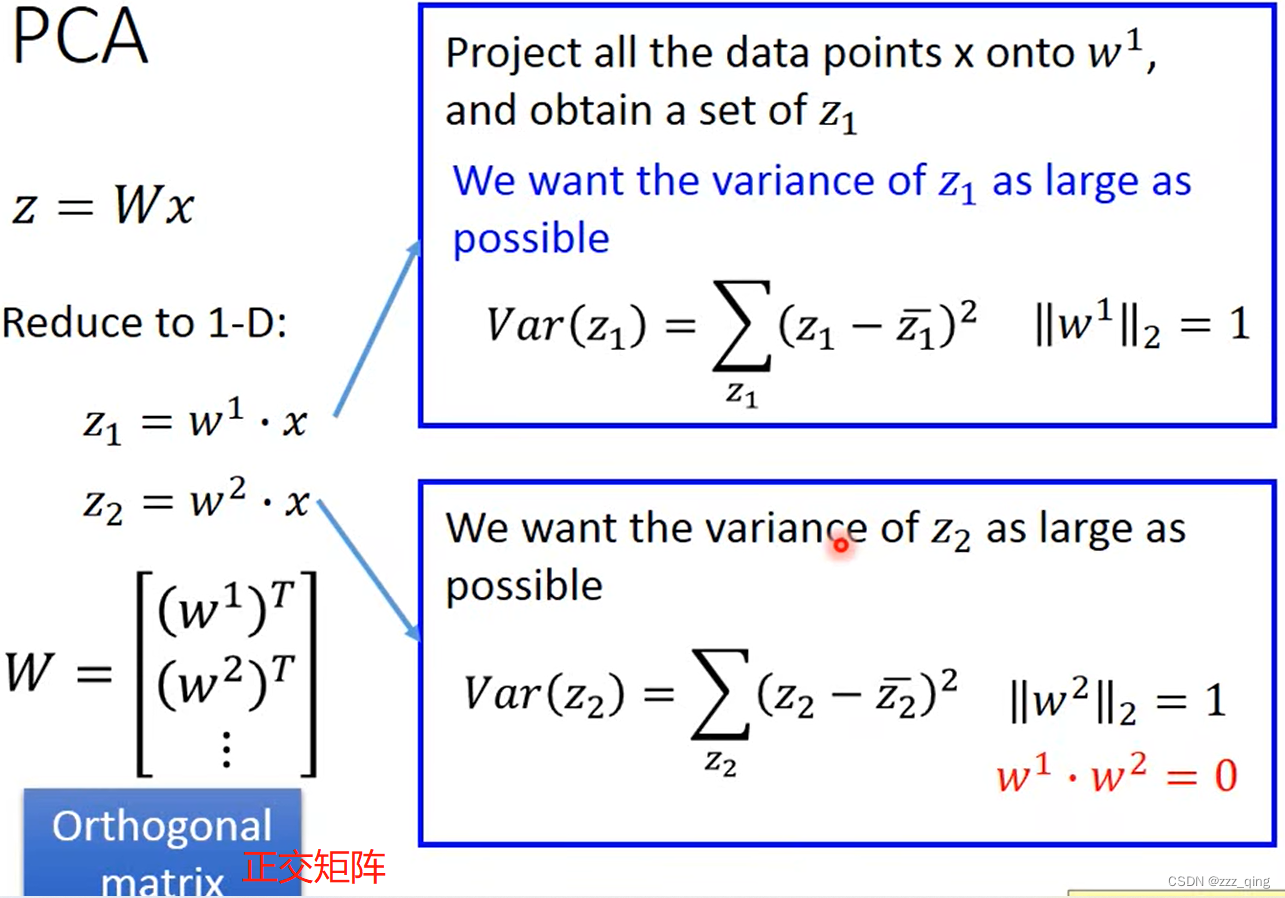
结论:w1 is the eigenvector of the covariance matrix S. Corresponding to the largest eigenvalue λ1.
w2 is the eigenvector of the covariance matrix S. Corresponding to the 2nd largest eigenvalue λ2.
wi is the eigenvector of the covariance matrix S. Corresponding to the ind largest eigenvalue λi.
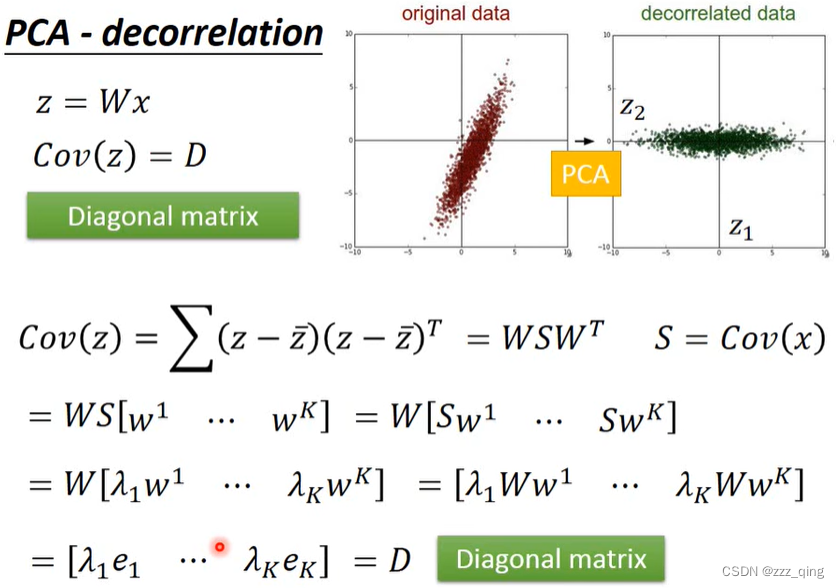
PCA - decorrelation:z的covariance 是一个diagonal matrix(好处是,把原来的input data做PCA以后给其他的model用,其他的model就可以假设现在的input data的dimension之间没有correlation,所以可以用比较简单的model去处理这些data,从而避免overfitting的情形)
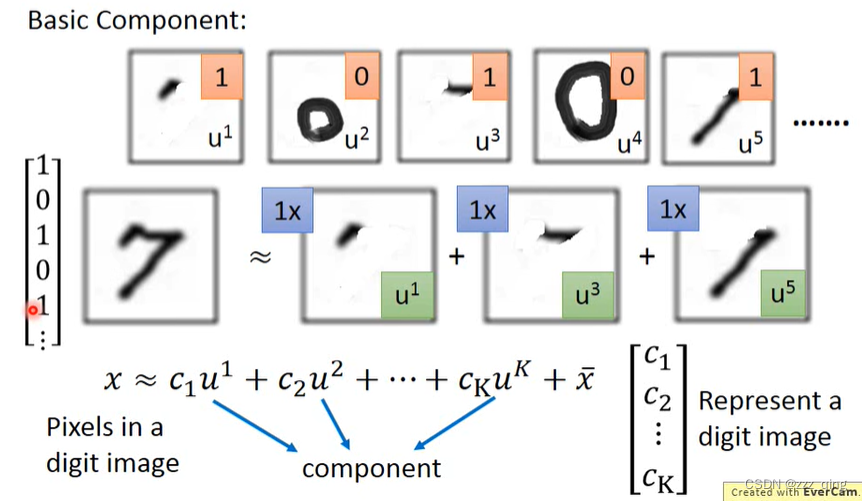
PCA - Another Point of View
下面用一种比较直观的方式说明PCA:

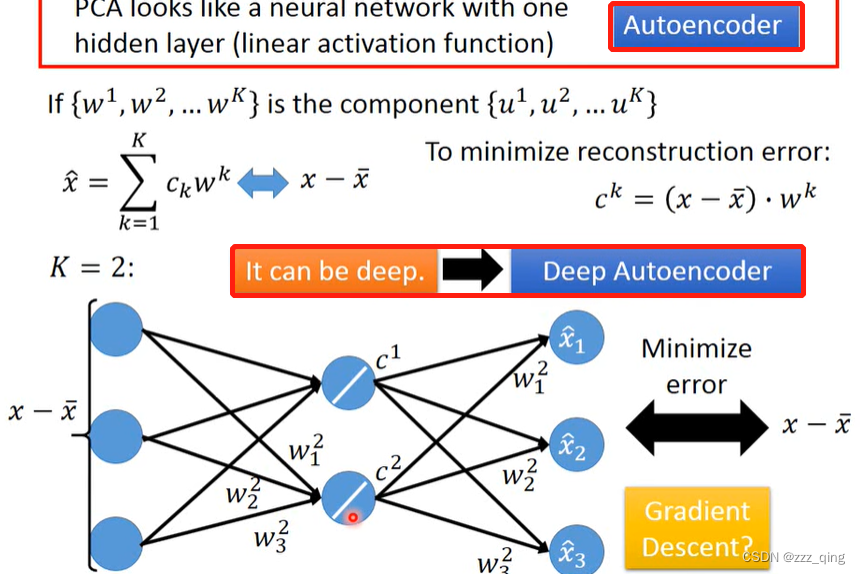
PCA和neural network的关系:PCA looks like a neural network with one hidden layer (linear activation function)
用one hidden layer的neural network + gradient descent,不可能找出来的reconstruction error比PCA找出来的reconstruction error还要小,但用neural network的好处是它可以是deep的:
Weakness of PCA
① PCA是unsupervised,如果给它一大堆data(这堆data没有label),PCA的目标是找让data variance最大的dimension,但是这样可能会把不同种类的data混在一起,无法分别。
如何解决:引入labeled data,变成supervised的问题,使用LDA
② PCA是linear的,要把下图中的s形曲面拉直,要用一个non-linear的transformation,PCA做不到这件事
Matrix Factorization
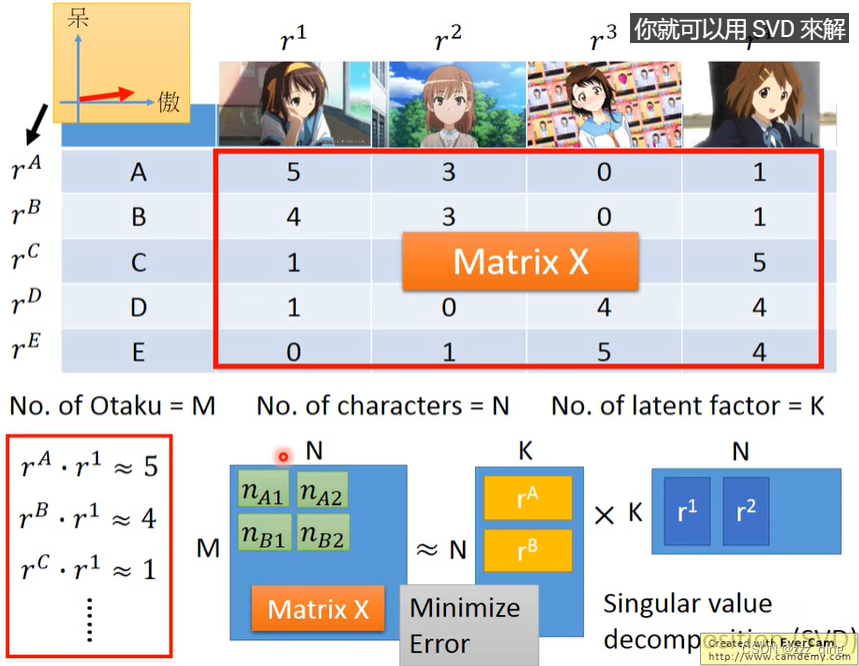
如果matrix X中有些information是未知的——用gradient descent的方法去做:


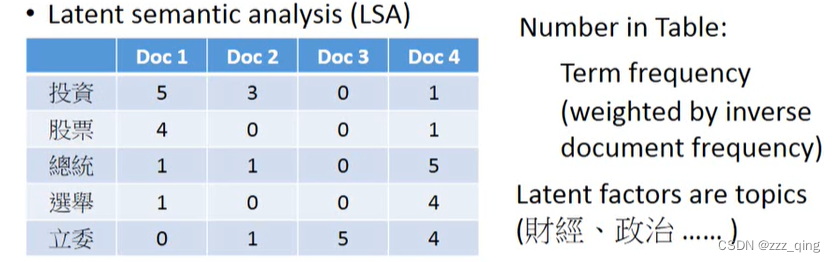
应用:Matrix Factorization for Topic analysis —— Latent semantic analysis (LSA)
Unsupervised Learning: Neighbor Embedding
Manifold Learning:Manifold Learning要做的事情是把塞在高维空间里的低维空间摊平,这对接下来要做的clustering/supervised Learning有帮助。如下图,把s形的东西展开:
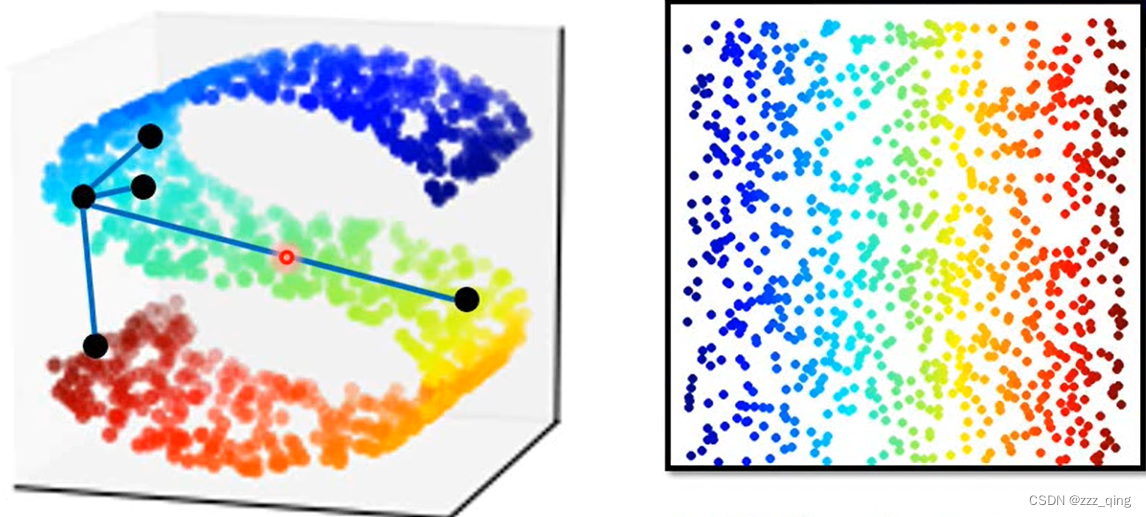
下面介绍几种做Manifold Learning的方法:
① Locally Linear Embedding (LLE)
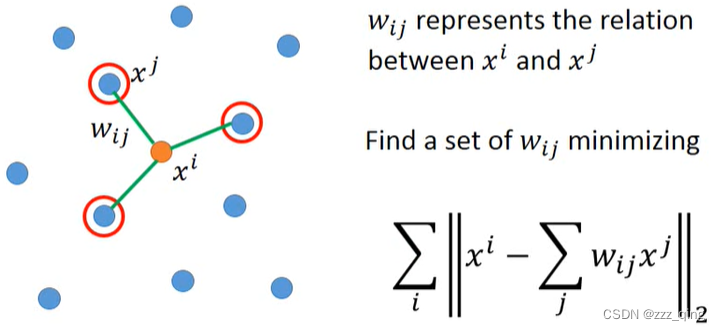
找到a set if Wij之后,要做dimension reduction,把原来所有的xi、xj转成zi、zj,要求从xi、xj转成zi、zj,它们中间的关系Wij不变。
注意,上面是找Wij,下图是Wij已知,要找z。
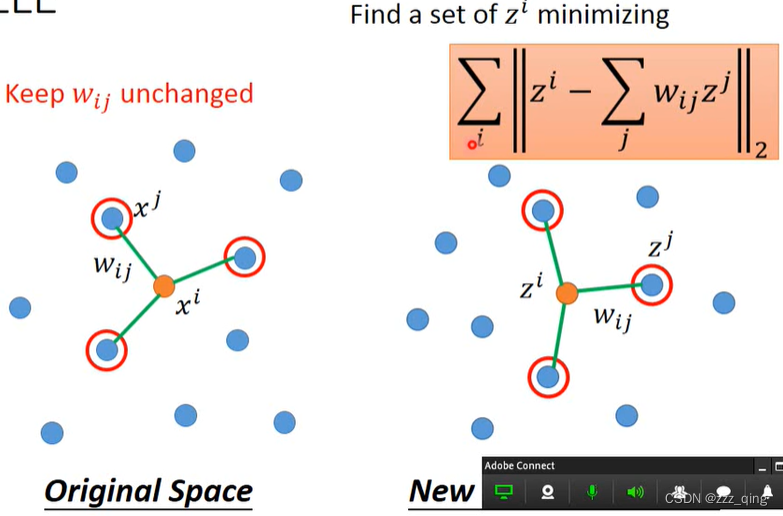
用LLE或其他类似方法有个好处:就算不知道原来的xi、xj(不知道要用什么vector来描述xi、xj),只要知道它们的关系——Wij,就可以用LLE这种方法。
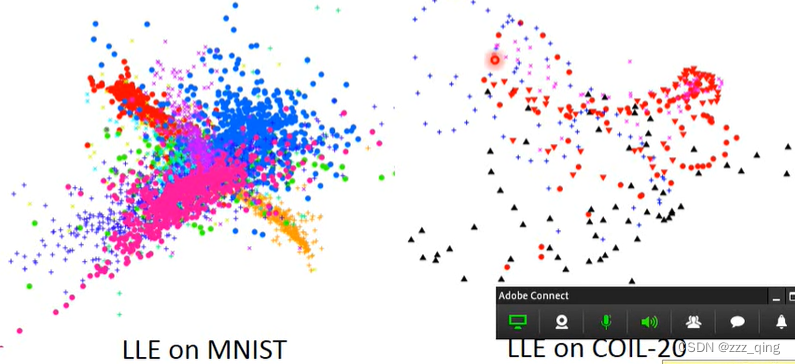
LLE的neighbor选的数目要刚刚好才会得到好的结果。
② Laplacian Eigenmaps

③ T-distriputed Stochastic NeighborEmbedding (t-SNE)
前面两种方法,存在一个很大的问题,它们只假设相近的点应该要是接近的,但没有假设不相近的点要分开。如下图中的例子,不同的object也挤在一起:
t-SNE一样是要降维,把原来的data point x降维成low dimension的vector z

t-SNE会计算所有data point之间的similarity,计算量很大,所以在原始数据维度较高时,通常先使用其他方法进行降维,再用t-SNE把维度降到更低(比如先用PCA把数据从300维降到50维,再用t-SNE把数据从50维降到2维)。
以上这些方法,比如t-SNE,如果给它一个新的data point,它没办法处理。所以一般t-SNE不是用于training、testing这种base上面,t-SNE通常是被拿来做visualization。
Similarity Measure
在原来的data point的space上,similarity选择RDF的function:
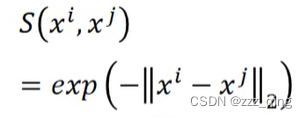
在dimension reduction之后的space,similarity选择t-distribution中的一种:
![]()
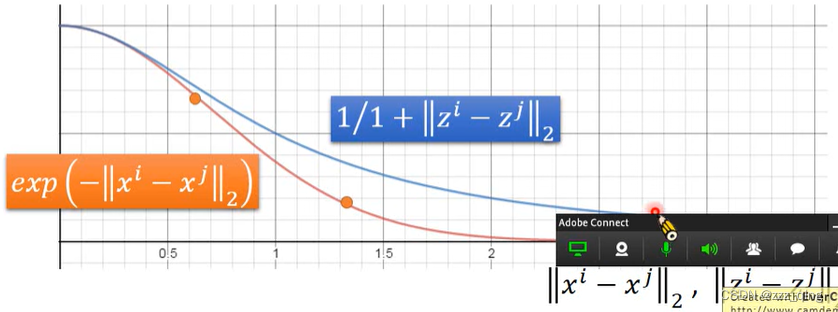
选择这样计算similarity的好处是,原来在高维空间中距离很近,那做完transform之后距离还是很近,如果原来在高维空间中已经有一段距离,那做完transform之后距离会被拉的很远:















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









