







网上一个很精彩的PyTorch深度学习实践的课程,几个月前学完了,现在准备再学一遍,加深一下理解与印象,做一些笔记。文章如有错误,望批评指正。本课程只是笔记,如有侵权,请联系我删除。
关注我的知乎问夏,学习更多人工智能技术
文章目录
1 人工智能概述
本节涉及到非常多有用的知识。知识非常基础,可以说是科普级知识。只要你对人工智能感兴趣,本节将会是你不能错过的精神盛宴。
1.1 课程目标与所需基础
课程目标:
- 如何使用Pytorch设计学习系统
- 理解基本的神经网络和深度学习
学习课程所需基础:
- 线性代数+概率论
- Python
1.2 什么是人工智能
1.2.1 什么是人类智能
人类智能之一:推理
比如,我们常有的一个话题,就是中午吃什么?实际上,中午吃什么就是一个根据已有信息进行决策和推断的事情。我们需要考虑我们身上的资金多少,还有个人偏好等信息。将这些综合起来,得出我们最后中午要吃什么的推理。

这就是一个很好地由外部信息进行最终推理的例子,它也是人类智能的一个体现。所以,人工智能的一大能力,就是推理能力。
人类智能之二:预测
人类智能的另一个表现就是预测。我们看到一张照片(如下),我们能够将一个抽象的概念与图片联系起来,比如将“猫”的概念与猫的图片联系起来,更普遍地来说,如果我们看到一个真实世界的实体,然后我们将这个实体与一个抽象概念连接起来,这就是一个“预测”的过程。

再比如,我们有一张手写数字的图形,我们将其与对应数字概念联系起来,也是预测。

有人就好奇了,数字怎么也是抽象概念呢?这是因为,数字本身没有意义。例如,2,它在中文里是“二”,在英文里是“Two”,它有不同的表现形式,但是他的含义都是一样的。所以,我们在理解数字时,它是一个非常抽象的概念,必须要将其与对应的实例结合起来,才能理解。
总而言之,我们将视觉上的信息,转化为抽象概念的东西,就叫做“预测”。
1.2.2 什么是人工智能?
人工智能,就是将原来用于推理的人类的大脑变成算法。利用算法进行推理。比如,还是中午吃什么,很多外卖软件可以根据我们的饮食习惯,推理出我们中午想吃什么。
现在在机器学习和深度学习领域上,基本上都是用的监督学习。
什么是监督学习呢?
监督学习,是利用已经标签好的数据,然后设计好模型,再利用这些数据对模型进行训练,最终得到算法。
机器学习的算法和算法课程学的算法的差别
我们在算法课学的算法,有穷举法、贪心法、分治法和动态规划法等等。对于这些方法,我们得到一个问题后,需要人工设计一个计算的过程。不过在机器学习中,算法不是我们设计出来的,机器学习里的算法,是根据已有的数据,通过训练,将想要的算法找出来的。
所以,机器学习里的算法,和算法课上的算法不同之处就在于,它来自于数据,而不是人工的设计。
1.2.3 深度学习
深度学习,是机器学习的一个分支,如下图。人工智能AI包含很多,机器学习属于人工智能。在机器学习下,有一种叫做表示学习(表征学习)。所谓表示学习,就是一种特征的提取,比如原数据量非常大,我们要提取其中有用的信息,以更好地表示数据样本的信息。

表示学习模型,有前层的自编码器和深层的自编码器。深层的自编码器就是深度学习。深度学习,从模型上来看,就是神经网络,从目标上来看,就是表示学习。深度学习里还有很多不同的模型,比如多层感知机、卷积神经网络和循环神经网络等等。深度学习,仅仅是人工智能里一个小分支,只不过在最近的10年,深度学习变得越来越热门。
当然,虽然深度学习大热,不过也有很多学者在提出深度学习的一些缺陷,比如可解释太差。不过在目前来说,能够落地的应用,大多是利用深度学习来解决的。
1.3 学习系统的发展
1.3.1 基于规则的学习系统
早期的学习系统,是基于规则的学习系统。就是,拿到一个输入,手工地设计程序,然后得到输出,过程如下图。
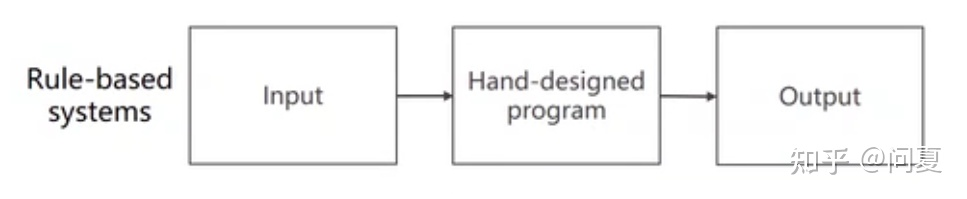
早期的人工智能,其实就是基于规则的。
比如说,我们在高等数学中,经常要求 f ( x ) f(x) f(x) 的原函数 ∫ f ( x ) d x \int f(x) dx ∫f(x)dx 。这个原函数有的不是非常好求的。比较早的一个人工智能程序,就是由程序来求原函数。它的原函数设计思路就是,首先它需要构建一批原函数知识库,例如 ∫ e x d x = e x \int e^xdx=e^x ∫exdx=ex , ∫ x n = 1 n + 1 x n + 1 \int x^n=\frac{1}{n+1}x^{n+1} ∫xn=n+11xn+1 等。此外,还有一些积分规则,如 ∫ ( f ( x ) + g ( x ) ) d x = ∫ f ( x ) d x + ∫ g ( x ) d x \int (f(x)+g(x))dx=\int f(x)dx+\int g(x)dx ∫(f(x)+g(x))dx=∫f(x)dx+∫g(x)dx 等。还有三角变换等等。
那么,我们利用上面的这些算法,可以计算出大部分函数的原函数。可能有人疑惑,这是人工智能吗?其实,只要能用机器代替人类智能的活动,就叫人工智能。
因而,基于规则的系统,也是人工智能的一种。这种系统,依赖于人工设计规则,所以比较难实现,而且规则越来越多,也很难人工维护。

1.3.2 经典机器学习方法
经典机器学习方法的流程如下:

经典的机器学习方法就是:先输入数据,然后手工设计来提取特征,最后特征映射得到输出。
举一个手工提取特征的例子,如一个学生的学习科目很多,但我们将数学成绩和物理成绩作为学生的数理思维特征。对于手工提取的特征,它可能来源于有结构的数据(如学生的成绩),也可能来源于无结构数据(比如声音和图像),最后我们由特征得到的是一个向量 x 。
然后,我们需要找出向量 x 与输出 y 的映射关系,即 y=f(x) 。
1.3.3 传统的表示学习
表示学习的最重要的一个区别是,特征提取的方法,最好也能提取出来。所以在早期时,特征提取是一个很重要的步骤,通常通过特征提取算法提取出一个向量,再扔到映射模块里面。

为什么要特征提取呢?这里就涉及有一个机器学习里面很重要的一个话题,叫维度诅咒。
维度诅咒:要提取的特征越多,对样本的数量需求也就越多。
举例,我们如果要提取一个特征,为了满足大数定律(数据越多越接近真实分布),可能需要10个数据。那么提取两个特征,为了保证第一个特征不影响第二个特征,就需要 1 0 2 10^2 102 个数据。以此类推,对于n个特征,就需要 1 0 n 10^n 10n 个数据,那么这个数据量是非常大的。并且收集图片是非常困难和昂贵的。
所以,很重要的一个话题就是,我们能不能把一个n维的特征降低到m(m<n)维,这就是表示学习,换句话说,就是我们需要学到高维空间到低维空间的一个表示。
我们学到的这个简化的分布,是在高维空间的一个低维流行。流行,即高维空间中的一个低维表示。特征提取,也就是降维,这是为了解决维度诅咒的问题。
1.3.4 基于深度学习的表示学习
深度学习用到的特征,是一个非常简单的特征,比如图像的像素值、语音波形等。然后,我们要设计额外的特征提取层,进行学习,再映射得输出。这个过程,我们用神经网络进行学习。

传统的表示学习,特征和映射是分开的,进行单独训练。不过在深度学习中,特征提取与映射输出是统一的。所以,我们把深度学习的过程,叫做一个End to End的过程,端到端的过程。即,我们将输入拿来,然后进入到深度学习模型,最后得到输出。
1.4 传统的机器学习与特征提取策略
传统的机器学习策略图如下,从Start开始,判断数据量(是否大于50),然后看要进行的是分类还是回归。然后看是否有标签,若有则进行分类,若无则是聚类。若是量化数据,可以选择回归或者降维等等。这是经典的机器学习方法。

在以前,我们常用的特征提取器是SVM家族。不过,随着时间的推移,SVM受到了许多挑战,其中主要的是以下几点:
- 人工设计的特征受到很多限制,有很多特征可能人们无法想到。
- SVM处理大数据集时表现不是很好。
- 现在需要处理越来越多的无结构的数据,如图像、文本和声音等。
1.5 ILSVRC竞赛与深度学习发展
ILSVRC竞赛,IMageNet,是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。

IMageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片。ILSVRC比赛会每年从IMageNet数据集中抽出部分样本进行比赛。
这个比赛主要包括图像分类、目标检测和场景分类等问题。
这个竞赛在11年之前,都是用一些浅层模型,比如SVM,错误率高达20%。不过到了2012年,错误率突然从25.8%降到了16.4%,变换非常大。这一年,也是深度学习开始绽放异彩的一年,这个网络是AlexNet。接下来,这个的错误率不断下降,直到2015年的ResNet降到3.57%(超过人类的5%错误率),此后这个比赛再举办几年后便不再举办,因为他们认为这个比赛的任务已经被解决了。

1.6 神经网络的历史
神经网络的最早灵感来源于神经科学,来自于数学与工程学。
1.6.1 寒武纪:感知结构的出现
首先,我们要说到寒武纪,物种大爆炸时期。据研究发现,爆发的原因是,在寒武纪之前,大部分是浮游生物,有吃的就吃。但是在寒武纪时候,有的生物进化出了眼睛,眼睛结构是一个非常简单的感知结构。眼睛能够感知光,那么就有生物出现趋光性和避光性,方便再未来进行进化,后来便有了物种爆发。这就是神经的起源。

1.6.2 1959年关于猫的神经实验
在后来,在1959做的一个实验,对神经网络有着较大的影响。如下图为实验示意图:

这个实验做于1959年。当时人们认为,当大脑看到物体后,神经就会被激活。实验人员给猫看幻灯片,看的是猫喜欢的食物如鱼,当然实验人员认为猫看到这些后猫的神经元会兴奋。但是看完后发现,无论看什么图片,猫的神经元都是无动于衷。不过,有意思的是,猫看一个幻灯片时,大脑没有反应;当幻灯片切换时,发现猫的大脑出现反应。然后继续加深实验,给猫看各种图片的切换,最终发现,哺乳动物处理信息时,是分层的,浅层的神经元检测的是浅层的特征比如图像变换,高级的神经元再去检测高级的特征,比如是什么食物。这个实验,对人工智能领域影响非常深远,其对神经网络影响非常直接。
对于一个神经细胞,有非常多树突,神经细胞可以利用树突进行感知与信息交换。那么我们根据此设计一个神经网络单元,用输入
(
X
1
,
X
2
,
X
3
)
( X_1,X_2,X_3 )
(X1,X2,X3)来感知外界信息,得到输出
Y
Y
Y 。根据生物神经的分层原理,我们开始将不同的神经层连接起来,就得到了人工神经网络。

对于神经网络来说,最重要的一个算法,就是反向传播。反向传播,其实就是求导数。不过,利用反向传播,我们不在需要求偏导的解析式,因为层数太多,写解析式非常困难。反向传播的核心是计算图,如下。

在计算图中,我们每一步只需要进行一些原子计算(不需要再分割的计算)。对于节点c和d,原子计算就是加法;对于节点e,原子计算就是乘法。计算图的第一步是正向计算,叫前馈过程。正向计算时,我们还需要进行一些局部偏导,比如 c 对 a 的偏导。我们最终要求的是e对a和b的偏导。然后,我们将前馈过程所有的局部偏导乘起来(链式求导法则),就可以得到最终e对a的偏导。
那么,我们用反向传播,就可以计算非常复杂的表达式和过程的偏导数。
1.7 深度学习模型上的改进
最早的深度学习模型是1998年的LeNet5模型,是用于识别手写的邮轮编码。到后来,2012年有AlexNet,2014年有GoogleNet和VGG,2015有ResNet,这些都是非常经典的网络模型。接下来,有非常多的神经网络架构,层出不穷。

我们学习的关键是,学习一些基本块,构建自己的模型。对于不同的任务,我们利用这些基本块,进行一个组装和重构。
1.8 深度学习进展的原因与其未来
1.8.1 深度学习为什么能迅速发展
深度学习能够快速发展,并取得如此进步,主要有有如下三个原因:
- 第一个是算法的进展,越来越多优秀的深度学习模型被发明出来。
- 第二个是获得的数据集越来越丰富,数据量越来越大,
- 第三个是算力的提升(主要是显卡GPU)。
最后,深度学习并不难,因为有现成的深度学习框架,再具备一定的数学和编程基础,就能很轻松地学习深度学习。
1.8.2 深度学习框架简介
首先,我们要明白深度学习框架能给我们提高什么:
- 不需要自己写计算图和反向传播
- 能够高效地使用GPU
- 框架提供了较多的现成的深度学习模型
目前比较流行的深度学习框架,如TensorFlow(用TensorFlow的人戏称TFBoys -.-),还有Caffeine和Pytorch(二者现在已经合并),此外还有MxNet和PaddlePaddle等。
当初,TensorFlow用的是静态图(Static Graph),静态图的灵活性非常低,不过由于它有先发优势,所以在当时非常火。而Pytorch主打的是动态图(Dynamic Graph),动态图是指一边做计算,图一边构建完,等计算完,图就释放了。所以每次Pytorch都可以构建不同的图。后来,学术界大家都转到Pytorch的阵营,工业界中用tensorflow还是非常多的。不过现在,tensorflow也是用动态图了,所以这方面上已经没有区别了。
后面本节还介绍了Pytorch如何安装,这个算是比较简单的问题了,不再赘言。本节到此。















 5198
5198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









