







3.2.蒙特卡洛方法
在之前已经了解在所有信息我们都知晓的情况下,该如何估计和优化目标。但是,在实际情况中,我们没有办法事前就知道所有事件的状态将其转义概率的。我们最多只能在每一次的实验之中观察并且总结经验。蒙特卡洛方法就是基于这样的思路而进行的。
首先,我们必须做一个限定,由于我们没有能力处理无限的序列,所以我们假设蒙特卡洛方法所处理的状态序列总会在有限步之后回归到一个(或者几个)吸收状态(状态不再发生改变)。这样的一个循环,我们称之为一个episode。
比如,养花的过程:
- 播种-施肥-浇水-浇水-开花
- 播种-浇水-施肥-打虫-浇水-开花
或者 - 播种-浇水-浇水-浇水-浇水-死亡
不管是怎么样的一个学生,在经历了有限个状态之后,花都会开或者死掉,那些就是我们的吸收状态,代表完成了这个episode。
现在,我们想知道,如何种花才能够让花开花而不是死亡。而且身边也没有人能够咨询获取经验(取得全局状态转移概率)。这时候我们就只有通过试验的方法来完成了,多准备几盆花,用不同的方式来养,看怎么养样的比较好。
对了,蒙特卡洛方法想的和你是一样的。
有时候由于随机性的扰动,即使完全遵循策略 π 也不一定在每次都能获得完全一致的回报,但是在多次试验中我们可以通过大量的样本总结,从而平均出策略的回报。
再讨论:
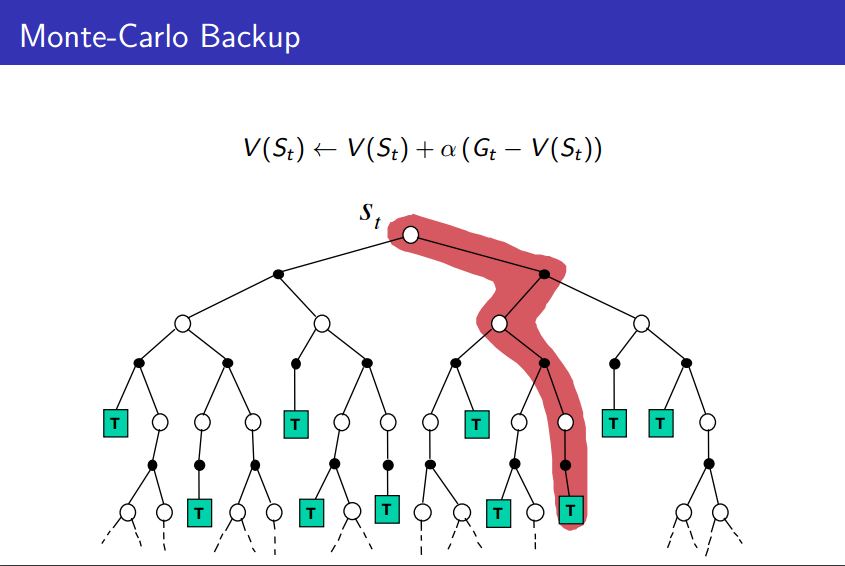
蒙特卡洛方法是最简单的收益估计思路,直接从经验中平均获得
蒙特卡洛方法必须从完整的流程中学习经验,而不是像MDP的收益估计那样可以通过自举的方式实现
3.2.1.蒙特卡洛估计
蒙特卡洛估计构成了强化学习领域庞杂的试错总结过程。它的核心思路如下:
- 1.确定要估计收益的状态s
- 2.从数据集合(所有的episode)中寻找所有s出现的情况,做出统计
3.3.时间差分学习
蒙特卡洛学习我们过得很快,因为思路很朴素,而且有着一个很致命的弱点,只能从一个完整的episode中学习经验。这是因为我们度量的是整个策略下的状态收益,如果从其中抽出一段的话,这一段过程可能是被前面多个策略选择所影响的,所以不能从episode的片段中进行学习。
但是DT的话,由于使用了一个一阶马尔科夫假设,所以可以进行“实时”的学习
而再之前我们了解到的MDP,需要了解的每一个状态对应的转移概率。
显然,这两种方法都有着强烈的局限性,为此,我们在这里介绍时间差分学习。
时间差分学习的迭代公式很简单:
注意这个t并非代表迭代次数而是状态数目
在更普遍的情况下,我们可以使用一个学习速率 γ 来代替 N(st+1) ,可得:
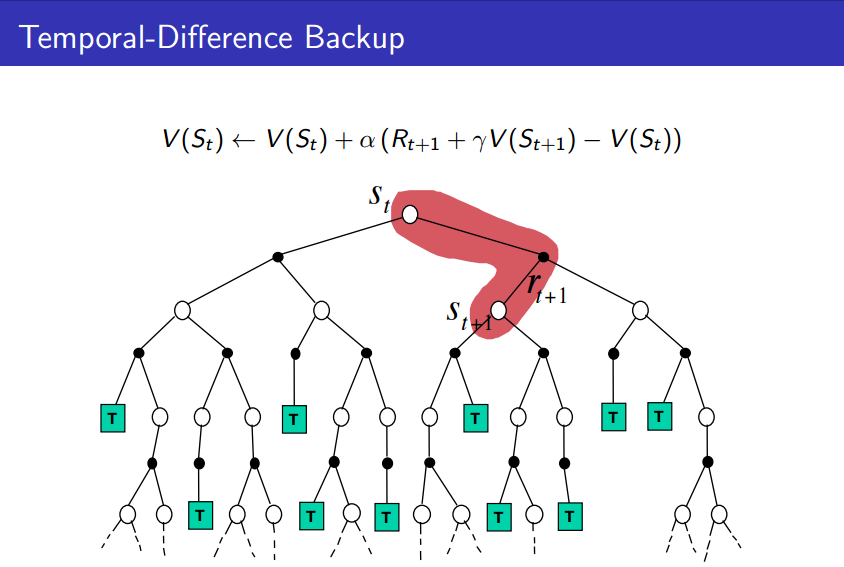
这就是时间差分学习了,用上一时刻所得到的收益与这一刻的比较,算出差值并且按照权值进行学习。时间差分学习有如下的优点:
- 时间差分学习可以直接从一个episode中获取经验
- 时间差分学习是依赖于模型(model-free)的,即不需要 先验的各种概率转移知识
- 时间差分学习可以通过自举(bootstrapping)从不完整的episode中获取知识,其更新可以是实时的,而不用像蒙特卡洛方法一样必须等每个周期结束才能进行估计
现在的问题就在于,这个真实收益
Gt
应该怎么估计,当然,如果实现就知道真实收益也不用这么多计算了,所以在未知的情况下我们可以通过其他方法来估计真实的收益,比如,我们使用
Rt+1+αV(st+1)
来代替真实收益,这就是TD(0)更新公式:
其中 Rt+1+γV(St+1) 被称作TD目标
怎么计算呢,来看下这个例子:
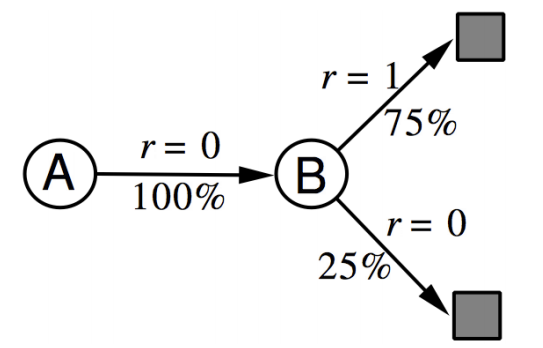
假设我们得到了八个经验样本,其中A,0代表经历状态A,获得收益0:
- A,0,B,0
- B,1
- B,1
- B,1
- B,1
- B,1
- B,1
- B,0
现在我们要估算 V(A) 还有 V(B)
如果使用蒙特卡洛方法的话,由于A状态仅仅出现了1次而且这一次收益为0,所以 V(A)=0
如果使用的是时间差分方法:
P^as,s′=1N(s,a)∑k=1K∑t=1Tk1(skt,akt,skt+1=s,a,s′)
R^as,a=1N(s,a)∑k=1K∑t=1Tk1(skt,akt=s,a)
其中 1(skt,akt,skt+1=s,a,s′) 代表由状态 s 经由动作a 变化为状态 s′ 的次数,依据题目条件,其实可得得到状态转化关系如图
这样,A状态的收益就等于B状态的收益乘以衰减因子。而B状态收益为0.75.故而A状态的收益最终会收敛到 0.75γ
时间差分学习更加充分的利用了马尔科夫过程的性质,从而显得更加有效率。而蒙特卡洛方法其实并不限定在马尔科夫过程中使用,响应的由于限制更小效率也更低。
4.总结:
蒙特卡洛方法需要从一个完整的经验数据中学习,但是马尔可夫性并没有很强的要求
时间差分方法可以通过自举的形式从经验片段中迭代进行学习,但是要求数据有一阶马尔科夫性质
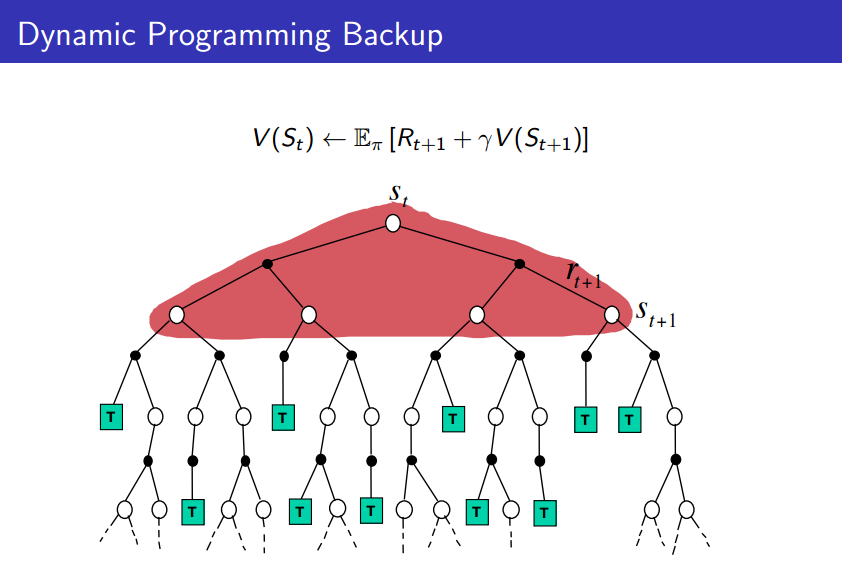
动态规划方法将有限步数的动作通过穷举的方法寻求最优,但是需要知道模型各个状态之间的转移概率















 6526
6526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









