







Gradient Descent with Large Datasets
Learning With Large Datasets
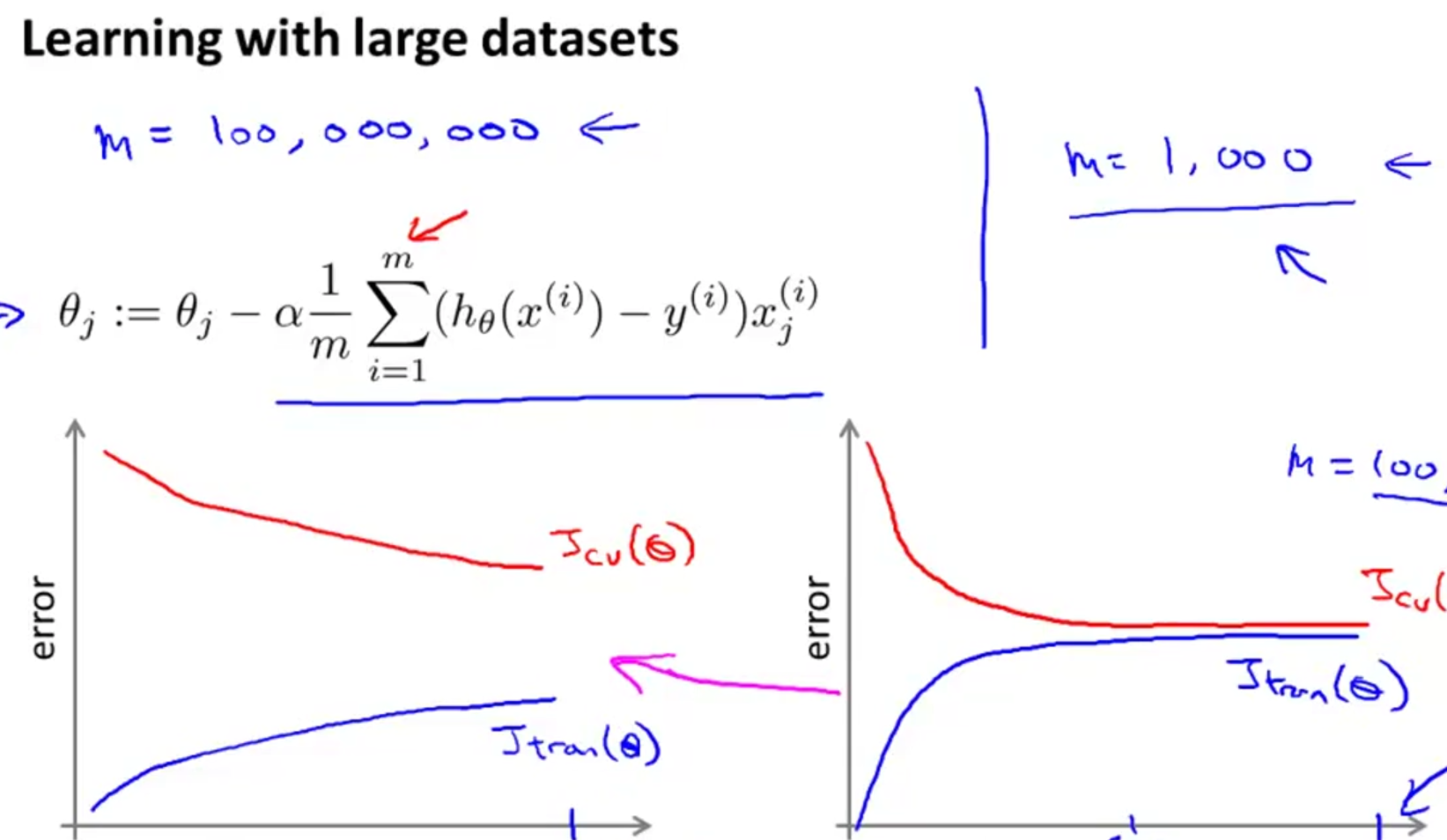
在处理海量数据时对算法会有更高的要求。比如在计算偏导数时,当m很大时对m个元素求和的开销会很大。
因此在将算法应用于海量数据时最好先确定算法没有high-bias,方法就是绘制leaning curve,左图是high-varience的,增大数据量会改善算法表现,而右图high-bias则不行。
Stochasic Gradient Descent
上节提到在linear regression梯度下降时求一次偏导数就需要遍历整个Training Set,开销非常大,这种方法称为Batch Gradient Descent。
另一种适合大数据的方法是Stochastic Gradient Descent:

定义新的函数cost,表示一个单一样本的误差。重新定义J(θ)为所有样本cost之和。

上面是新算法的完整过程。
原算法遍历一次全部样本才能进行一次梯度下降,而新算法每遍历一个样本就进行一次(使得模型更接近这个样本),这样每处理一个样本虽然不能完全保证J(θ)缩小,但是速度大大增快。
当样本量极大时,通常遍历一次全部样本就可以使模型收敛。
Mini-Batch Gradient Descent
Batch Gradient Descent是一次迭代所有样本
Stochasic Gradient Descent是一次迭代一个样本
Mini-Batch Gradient Descent就是一次迭代b个样本
在一些情况下会比Stochasic Gradient Descent还快,因为同时操作b个样本的计算可以用向量化来优化。
Stochastic Gradient Descent Convergence
在 Batch Gradient Descent中检测算法是否收敛的方法是绘制一个图像,横坐标是迭代次数,纵坐标是J(θ)。对于Stochastic Gradient Descent同样可以使用这个方法。区别是因为数据量大,每k次迭代(k个样本)绘制一个点。
注意在Stochastic Gradient Descent时,对于第i个样本我们是先计算cost(i),再用x(i)优化模型。
绘制出的图像会是震荡的。
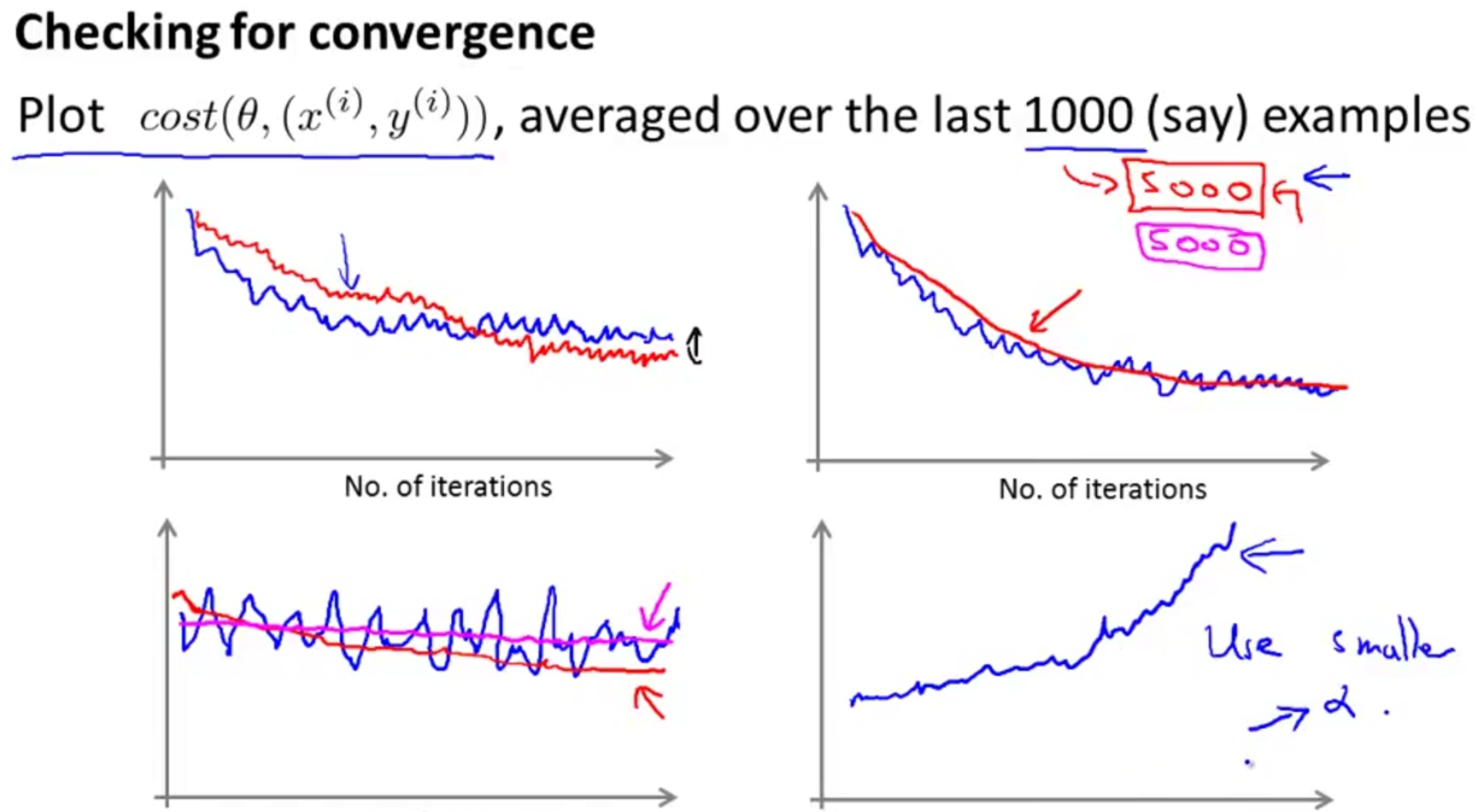
图一是一个理想的图像。
图二将k增大为5000,可以使曲线更平滑。
图三因为震荡剧烈无法判断是否收敛,此时可以增大k使图像更清晰。
图四表示算法没有收敛,此时应减小a
Stochastic Gradient Descent的收敛不是停在全局最优点,而是在最优点附件震荡。一种减少震荡的方式是将a设为 c1 / (c2 + 迭代次数),随着迭代次数的增加a逐渐减小。但是找到合适的c1,c2又需要多余计算。
Advanced Topics
Online Learning
在线学习的方法很简单,每获得一个新样本,就对该样本执行梯度下降,然后丢弃它。比如预测用户在浏览购买手机网站时输入需求,计算最有可能点击的链接。这样在用户每一次点击后,都用梯度下降处理该次点击。
Map Reduce and Data Parallelism
MapReduce的思想很简单,就是利用并行技术,将计算任务分块,再将计算结果合并。一个例子就是在做梯度下降时有一个求和的操作,将需要求和的东西分成几个部分交给不同的机器/CPU去运算,再将结果重新加和。















 7022
7022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









