









针对Intel发表的一份关于Xeon Phi与NVIDIA GPU深度学习性能对比的Benchmark,NVIDIA加速计算业务副总裁Ian Buckf撰写博客文章,对Intel的核心观点进行逐一驳斥,重点指责Intel在与过时的软硬件PK。
基准(benchmark)是衡量性能的一个重要工具,但是在一个快速发展的领域,它很难跟得上技术发展的脚步。最近,英特尔就针对其传闻已久的Xeon Phi处理器公布了一些错误的“事实”。
深度学习技术在发展速度上超过了绝大多数其它领域。现今的神经网络,其深度已经比短短数年前提升了6倍,并且也变得更加强大。多GPU扩展技术中的全新功能甚至还能实现更快的训练效果。
此外,我们已经从Kepler、Maxwell升级到目前基于Pascal的系统,比如配有8颗Tesla P100GPU的DGX-1超级计算机,从而在短短一年内将神经网络训练时间缩短了10倍。
因此完全可以理解,该领域的后来者可能无法洞悉目前这一领域软硬件的整体发展情况。
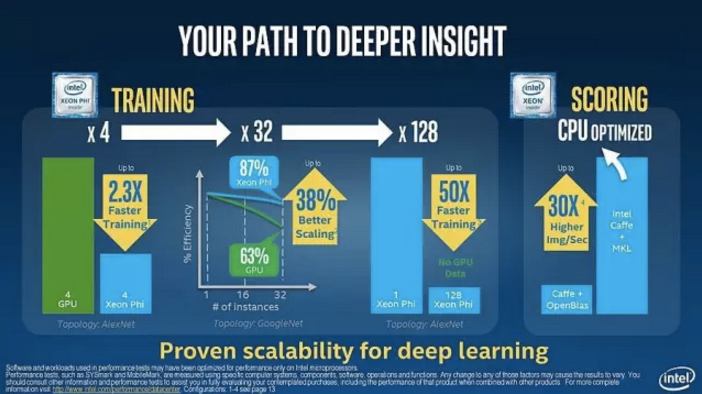
例如,英特尔最近发布了一些过时的基准,并宣称其Knights Landing Xeon Phi处理器在深度学习性能上具有以下三项优势:
让我们逐条分析这三项优势,并纠正可能出现的一些错误认知。
新版与旧版Caffe深度学习框架
英特尔采用了18个月前开发的Caffe AlexNet模型数据,并对采用四颗Maxwell GPU的系统与四台Xeon Phi服务器进行了对比。而如果采用新版Caffe AlexNet模型(点击获取),英特尔就会发现采用四颗Maxwell GPU的系统,训练时间要比四台Xeon Phi处理器快30%。
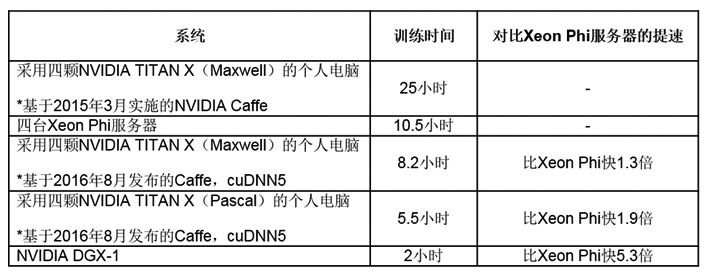
实际上,一台采用四颗基于Pascal 架构的NVIDIA TITAN X GPU的系统,其训练速度要比四台Xeon Phi服务器速度快90%,而单台NVIDIA DGX-1的训练速度则比四台Xeon Phi服务器快5倍还多。
扩展性提升38%
英特尔将Caffe GoogleNet在32台Xeon Phi服务器上的训练成效与橡树岭国家实验室泰坦超级计算机的32台服务器进行了对比。泰坦采用了四年前的GPU(Tesla K20X)以及之前美洲豹超级计算机所用的互连技术。而Xeon Phi的结果则基于最近推出的互连技术。
百度使用更新的Maxwell GPU及互连技术,结果显示其语音训练工作负载的扩展几乎呈现为直线,高达128颗GPU。
英特尔着手发展深度学习当然值得称道,我们正面临人工智能时代一次最重要的技术革命,而如火如荼的深度学习肯定不能被忽略。但是,他们应该把事实搞清楚。
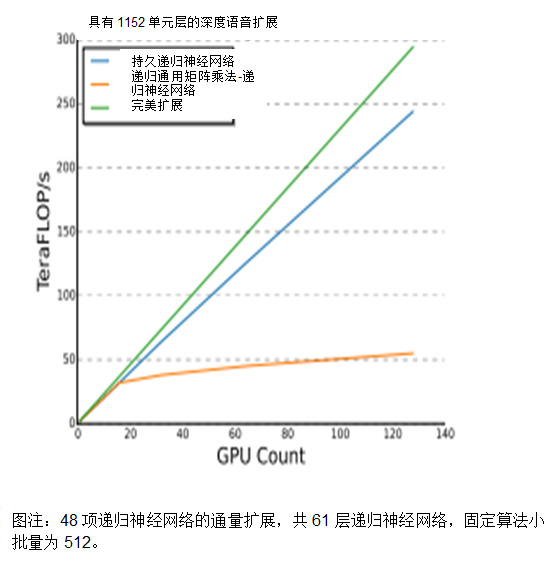
可扩展性不仅取决于底层处理器,代码的互连与架构优化同样重要。GPU为百度等客户带来了极佳的扩展性。
大幅扩展至128个节点
英特尔声称,128台XeonPhi服务器可带来比单个Xeon Phi服务器快50倍的性能,而GPU则没有此类扩展性数据。如上所述,百度已经公布的结果显示,扩展几乎呈直线形态,多达128颗GPU。
为了实现强扩展,我们认为强节点要优于弱节点。与许多采用一到两个如Xeon Phi这样性能不足的处理器的弱节点相比,采用多颗高性能GPU的单台服务器的性能要更加优越。例如,单台DGX-1系统可比至少21台Xeon Phi服务器提供更好的大幅扩展性能(DGX-1要比四台Xeon Phi服务器快5.3倍)。
人工智能时代
深度学习有望彻底改变计算,改善我们的生活,提升我们业务系统的效率和智能化,并推动人类的深远发展。为此,我们多年来一直在提升并行处理器的设计,并创建软件和技术来加速深度学习。
我们为深度学习做出深入而广泛的努力。每个框架都有NVIDIA的优化支持,每位主要的深度学习研究者、实验室和公司都在使用NVIDIA GPU。
我们可以逐个纠正他们的误导性言论,不过我们认为,和以前的Kepler GPU架构以及过时的软件进行深度学习对比测试是错误的做法,很容易就可以纠正。这样也有利于让整个行业与时俱进。















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









