






卡尔曼滤波是一种在不确定状况下组合多源信息得到所需状态最优估计的一种方法。本文将简要介绍卡尔曼滤波的原理及推导。
什么是卡尔曼滤波
首先定义问题:对于某一系统,知道当前状态 Xt ,存在以下两个问题:
- 经过时间 △t 后,下个状态 Xt+1 如何求出?
- 假定已求出 Xt+1 ,在 t+1 时刻收到传感器的非直接信息 Zt+1 ,如何对状态 Xt+1 进行更正?
这两个问题正是卡尔曼滤波要解决的问题,形式化两个问题如下:
- 预测未来
- 修正当下
下面,将以机器人导航为例,从预测未来和修正当下两个角度介绍卡尔曼滤波器。
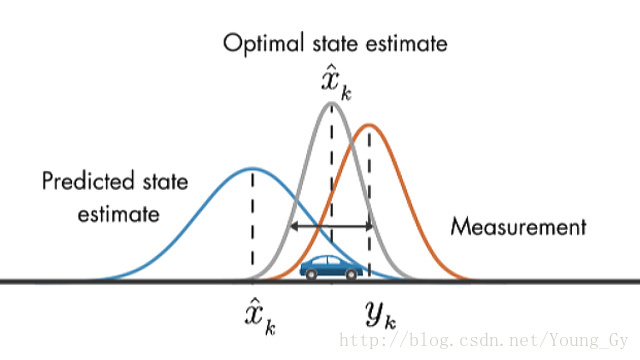
卡尔曼滤波的原理
问题场景如下:一个机器人,我们想知道它实时的状态 x⃗ ,同时也想做到预测未来和修正当下这两件事。
其状态 x 表示为一维大小为2的向量,元素分别表示位置信息与速度信息:
可是状态 x 不一定是精准的,其不确定性用协方差表示:
预测未来
只考虑自身状态
只考虑自身状态的情况下,根据物理公式,可得:
用矩阵表示如下:
在状态变化的过程中引入了新的不确定性,根据协方差的乘积公式可得:
考虑外部状态
外部状态,这里以加速度为例,引入变量 a ( uk→ )。
同时,环境仍然存在我们无法刻画的误差,以 Qk 表示,最终的预测公式如下:
从上述式子可见:
- 新的最优估计 是 之前最优估计 的预测加上 已知的外界影响 的修正。
- 新的不确定度 是 预测的不确定度 加上 环境的不确定度 。
修正当下
我们已得到 x̂ k,Pk ,下面要通过观测到的测量值 zk→ 对 x̂ k,Pk 进行更新。
因为 x̂ k,Pk 和 zk→ 的数据尺度不一定相同,例如 x̂ k,Pk 包含了 笛卡尔 的坐标信息,使用radar得到的 zk→ 则包含 极坐标 信息。所以首先应该把两者放在相同的尺度下去比较,尺度转换使用 Hk 将预测信息转化为测量信息的尺度。
这样一来,便得到测量尺度上的两个分布:
- 测量值的分布 (x,μ1,σ1)
- 预测值变换后的分布 (x,μ0,σ0)
下面一个问题就是如何用这个两个分布组成新的分布。
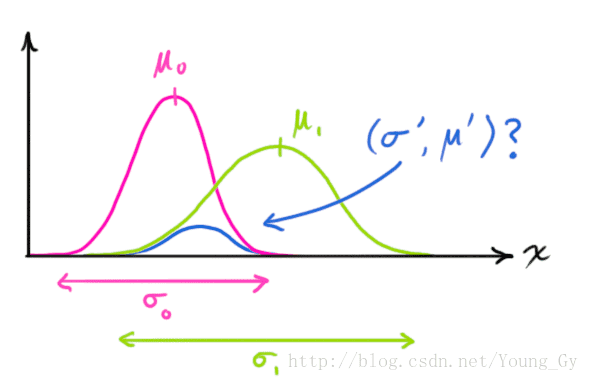
简单的一维情况如下:
高维情况下,针对测量值分布 (μ1,Σ1)=(zk→,Rk) 与预测值的变化分布 (μ0,Σ0)=(Hkx̂ k,HkPkHTk) 组合的高斯分布如下:
总结
预测未来
- 输入:过去的最优状态( x̂ k−1 , Pk−1 )、外界对过程的影响 uk→ ,环境的不确定度 Qk 。
- 输出:预测的最优状态( x̂ k , Pk )。
- 其他:对过程的描述( Fk , Bk )跟时间有关。
修正当下
- 输入:预测的最优状态( x̂ k , Pk ),测量的状态分布 (zk→,Rk) ,预测到测量的变换矩阵 Hk 。
- 输出:经过测量修正的最优状态( x̂ ′k , P′k )。
卡尔曼滤波需要内存少,计算速度快,适合实时性情况与嵌入式设备的需要。















 5959
5959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









