







 本文详细介绍了正态分布、方差、标准差、协方差和相关系数的概念及其相互关系。方差衡量数据的离散程度,标准差是方差的平方根,协方差则描述了两个变量的共同变动趋势。对于协方差矩阵,其对角线元素是变量的方差,非对角线元素表示变量间的协方差。相关系数进一步量化了变量间的线性相关性,取值范围在-1到1之间,表示变量间的正相关、负相关或不相关程度。
本文详细介绍了正态分布、方差、标准差、协方差和相关系数的概念及其相互关系。方差衡量数据的离散程度,标准差是方差的平方根,协方差则描述了两个变量的共同变动趋势。对于协方差矩阵,其对角线元素是变量的方差,非对角线元素表示变量间的协方差。相关系数进一步量化了变量间的线性相关性,取值范围在-1到1之间,表示变量间的正相关、负相关或不相关程度。
卡尔曼滤波----方差、协方差与相关系数
正态分布(高斯分布)
正态分布是一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x 轴上方的钟形曲线。当μ=0, σ 2 σ^2 σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。


一、 方差
方差是各个数据与平均数之差的平方的平均数。在概率论和数理统计中,方差(英文Variance)用来度量随机变量和其数学期望(即均值)之间的偏离程度。在许多实际问题中,研究随机变量和均值之间的偏离程度有着很重要的意义。

如果你从网上查找方差的公式,你会发现有2个公式!无偏估计
s
N
2
=
1
N
∑
i
=
1
N
(
x
i
−
x
ˉ
)
2
和
s
2
=
1
N
−
1
∑
i
=
1
N
(
x
i
−
x
ˉ
)
2
\begin{aligned} &s_{N}^{2}=\frac{1}{N} \sum_{i=1}^{N}\left(x_{i}-\bar{x}\right)^{2}\\ \text { 和 }\\ &s^{2}=\frac{1}{N-1} \sum_{i=1}^{N}\left(x_{i}-\bar{x}\right)^{2} \end{aligned}
和 sN2=N1i=1∑N(xi−xˉ)2s2=N−11i=1∑N(xi−xˉ)2
那么哪个是正确的呢?又有什么区别呢?这里就要说下贝赛尔修正:
在上面的方差公式和标准差公式中,存在一个值为N的分母,其作用为将计算得到的累积偏差进行平均,从而消除数据集大小对计算数据离散程度所产生的影响。不过,使用N所计算得到的方差及标准差只能用来表示该数据集本身(population)的离散程度;如果数据集是某个更大的研究对象的样本(sample),那么在计算该研究对象的离散程度时,就需要对上述方差公式和标准差公式进行贝塞尔修正,将N替换为N-1:
简单的说,是除以 N 还是 除以 N-1,则要看样本是否全,比如,我要统计全国20岁男性的平均身高,这时间你肯定拿不到全部20岁男性的身高,所以只能随机抽样 500名,这时间要除以 N-1,因为只是部分数据;但是我们算沪深300在2017年3月份的涨跌幅,我们是可以全部拿到3月份的数据的,所以我们拿到的是全部数据,这时间就要除以 N。
二、标准差
方差开根号。
三、协方差
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。

可以通俗的理解为:两个变量在变化过程中是否同向变化?还是反方向变化?同向或反向程度如何?
- 你变大,同时我也变大,说明两个变量是同向变化的,这是协方差就是正的。
- 你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
- 如果我是自然人,而你是太阳,那么两者没有相关关系,这时协方差是0。
从数值来看,协方差的数值越大,两个变量同向程度也就越大,反之亦然。
可以看出来,协方差代表了两个变量之间的是否同时偏离均值,和偏离的方向是相同还是相反。
公式:如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值,即为协方差。
σ
(
x
,
y
)
=
1
n
−
1
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
Cov
(
X
,
Y
)
=
E
[
(
X
−
μ
x
)
(
Y
−
μ
y
)
]
\begin{aligned} &\sigma(x, y)=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right) \\ &\operatorname{Cov}(X, Y)=E\left[\left(X-\mu_{x}\right)\left(Y-\mu_{y}\right)\right] \end{aligned}
σ(x,y)=n−11i=1∑n(xi−xˉ)(yi−yˉ)Cov(X,Y)=E[(X−μx)(Y−μy)]
协方差矩阵
对多维随机变量
X
=
[
X
1
,
X
2
,
X
3
,
…
,
X
n
]
T
\mathbf{X}=\left[X_{1}, X_{2}, X_{3}, \ldots, X_{n}\right]^{T}
X=[X1,X2,X3,…,Xn]T, 我们往往需要计算各维度两两之间的协方差, 这样 各协方差组成了一个
n
×
n
n \times n
n×n 的矩阵, 称为协方差矩阵。协方差矩阵是个对称矩阵, 对角线上的元素是各维度上随机变量的方差。我们定义协方差矩阵为
Σ
\Sigma
Σ, 这个符号与求和
∑
\sum
∑ 相同,需要根据上下文区分。矩阵内的元素
Σ
i
j
\Sigma_{i j}
Σij 为
Σ
i
j
=
cov
(
X
i
,
X
j
)
=
E
[
(
X
i
−
E
[
X
i
]
)
(
X
j
−
E
[
X
j
]
)
]
\Sigma_{i j}=\operatorname{cov}\left(X_{i}, X_{j}\right)=\mathrm{E}\left[\left(X_{i}-\mathrm{E}\left[X_{i}\right]\right)\left(X_{j}-\mathrm{E}\left[X_{j}\right]\right)\right]
Σij=cov(Xi,Xj)=E[(Xi−E[Xi])(Xj−E[Xj])]
这样这个矩阵为
Σ
=
E
[
(
X
−
E
[
X
]
)
(
X
−
E
[
X
]
)
T
]
=
[
cov
(
X
1
,
X
1
)
cov
(
X
1
,
X
2
)
⋯
cov
(
X
1
,
X
n
)
cov
(
X
2
,
X
1
)
cov
(
X
2
,
X
2
)
⋯
cov
(
X
2
,
X
n
)
⋮
⋮
⋱
⋮
cov
(
X
n
,
X
1
)
cov
(
X
n
,
X
2
)
⋯
cov
(
X
n
,
X
n
)
]
\begin{gathered} \Sigma=\mathrm{E}\left[(\mathbf{X}-\mathrm{E}[\mathbf{X}])(\mathbf{X}-\mathrm{E}[\mathbf{X}])^{T}\right] \\ =\left[\begin{array}{cccc} \operatorname{cov}\left(X_{1}, X_{1}\right) & \operatorname{cov}\left(X_{1}, X_{2}\right) & \cdots & \operatorname{cov}\left(X_{1}, X_{n}\right) \\ \operatorname{cov}\left(X_{2}, X_{1}\right) & \operatorname{cov}\left(X_{2}, X_{2}\right) & \cdots & \operatorname{cov}\left(X_{2}, X_{n}\right) \\ \vdots & \vdots & \ddots & \vdots \\ \operatorname{cov}\left(X_{n}, X_{1}\right) & \operatorname{cov}\left(X_{n}, X_{2}\right) & \cdots & \operatorname{cov}\left(X_{n}, X_{n}\right) \end{array}\right] \end{gathered}
Σ=E[(X−E[X])(X−E[X])T]=⎣⎢⎢⎢⎡cov(X1,X1)cov(X2,X1)⋮cov(Xn,X1)cov(X1,X2)cov(X2,X2)⋮cov(Xn,X2)⋯⋯⋱⋯cov(X1,Xn)cov(X2,Xn)⋮cov(Xn,Xn)⎦⎥⎥⎥⎤
其中,对角线上的元素为各个随机变量的方差,非对角线上的元素为两两随机变量之间的协方差。
样本的协方差矩阵
与上面的协方差矩阵相同,只是矩阵内各元素以样本的协方差替换。样本集合为
{
x
⋅
j
=
[
x
1
j
,
x
2
j
,
…
,
x
n
j
]
T
∣
1
⩽
j
⩽
m
}
\left\{\mathbf{x}_{\cdot j}=\left[x_{1 j}, x_{2 j}, \ldots, x_{n j}\right]^{T} \mid 1 \leqslant j \leqslant m\right\}
{x⋅j=[x1j,x2j,…,xnj]T∣1⩽j⩽m},
m
m
m 为样本数量, 所有样本可以表示成一个
n
×
m
n \times m
n×m 的矩阵。我们以
Σ
^
\hat{\Sigma}
Σ^表示样本的协方差矩阵, 与
Σ
\Sigma
Σ 区分。
Σ
^
=
[
q
11
q
12
⋯
q
1
n
q
21
q
21
⋯
q
2
n
⋮
⋮
⋱
⋮
q
n
1
q
n
2
⋯
q
n
n
]
\hat{\Sigma}=\left[\begin{array}{cccc} q_{11} & q_{12} & \cdots & q_{1 n} \\ q_{21} & q_{21} & \cdots & q_{2 n} \\ \vdots & \vdots & \ddots & \vdots \\ q_{n 1} & q_{n 2} & \cdots & q_{n n} \end{array}\right]
Σ^=⎣⎢⎢⎢⎡q11q21⋮qn1q12q21⋮qn2⋯⋯⋱⋯q1nq2n⋮qnn⎦⎥⎥⎥⎤
=
1
m
−
1
[
∑
j
=
1
m
(
x
1
j
−
x
ˉ
1
)
(
x
1
j
−
x
ˉ
1
)
∑
j
=
1
m
(
x
1
j
−
x
ˉ
1
)
(
x
2
j
−
x
ˉ
2
)
⋯
∑
j
=
1
m
(
x
1
j
−
x
ˉ
1
)
(
x
n
j
−
x
ˉ
n
)
∑
j
=
1
m
(
x
2
j
−
x
ˉ
2
)
(
x
1
j
−
x
ˉ
1
)
∑
j
=
1
m
(
x
2
j
−
x
ˉ
2
)
(
x
2
j
−
x
ˉ
2
)
⋯
∑
j
=
1
m
(
x
2
j
−
x
ˉ
2
)
(
x
n
j
−
x
ˉ
n
)
⋮
⋮
⋱
⋮
∑
j
=
1
m
(
x
n
j
−
x
ˉ
n
)
(
x
1
j
−
x
ˉ
1
)
∑
j
=
1
m
(
x
n
j
−
x
ˉ
n
)
(
x
2
j
−
x
ˉ
2
)
⋯
∑
j
=
1
m
(
x
n
j
−
x
ˉ
n
)
(
x
n
j
−
x
ˉ
n
)
]
=
1
m
−
1
∑
j
=
1
m
(
x
⋅
j
−
x
‾
)
(
x
⋅
j
−
x
‾
)
T
\begin{array}{cccc} =\frac{1}{m-1}\left[\begin{array}{cccc} \sum_{j=1}^{m}\left(x_{1 j}-\bar{x}_{1}\right)\left(x_{1 j}-\bar{x}_{1}\right) & \sum_{j=1}^{m}\left(x_{1 j}-\bar{x}_{1}\right)\left(x_{2 j}-\bar{x}_{2}\right) & \cdots & \sum_{j=1}^{m}\left(x_{1 j}-\bar{x}_{1}\right)\left(x_{n j}-\bar{x}_{n}\right) \\ \sum_{j=1}^{m}\left(x_{2 j}-\bar{x}_{2}\right)\left(x_{1 j}-\bar{x}_{1}\right) & \sum_{j=1}^{m}\left(x_{2 j}-\bar{x}_{2}\right)\left(x_{2 j}-\bar{x}_{2}\right) & \cdots & \sum_{j=1}^{m}\left(x_{2 j}-\bar{x}_{2}\right)\left(x_{n j}-\bar{x}_{n}\right) \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{j=1}^{m}\left(x_{n j}-\bar{x}_{n}\right)\left(x_{1 j}-\bar{x}_{1}\right) & \sum_{j=1}^{m}\left(x_{n j}-\bar{x}_{n}\right)\left(x_{2 j}-\bar{x}_{2}\right) & \cdots & \sum_{j=1}^{m}\left(x_{n j}-\bar{x}_{n}\right)\left(x_{n j}-\bar{x}_{n}\right) \end{array}\right] \\ =\frac{1}{m-1} \sum_{j=1}^{m}\left(\mathbf{x}_{\cdot j}-\overline{\mathbf{x}}\right)\left(\mathbf{x}_{\cdot j}-\overline{\mathbf{x}}\right)^{T} \end{array}
=m−11⎣⎢⎢⎢⎡∑j=1m(x1j−xˉ1)(x1j−xˉ1)∑j=1m(x2j−xˉ2)(x1j−xˉ1)⋮∑j=1m(xnj−xˉn)(x1j−xˉ1)∑j=1m(x1j−xˉ1)(x2j−xˉ2)∑j=1m(x2j−xˉ2)(x2j−xˉ2)⋮∑j=1m(xnj−xˉn)(x2j−xˉ2)⋯⋯⋱⋯∑j=1m(x1j−xˉ1)(xnj−xˉn)∑j=1m(x2j−xˉ2)(xnj−xˉn)⋮∑j=1m(xnj−xˉn)(xnj−xˉn)⎦⎥⎥⎥⎤=m−11∑j=1m(x⋅j−x)(x⋅j−x)T
公式中
m
m
m 为样本数量,
x
‾
\overline{\mathbf{x}}
x 为样本的均值, 是一个列向量,
x
⋅
j
\mathbf{x}_{\cdot j}
x⋅j 为第
j
j
j 个样本,也是一个列向量。
在写程序计算样本的协方差矩阵时,我们通常用后一种向量形式计算。一个原因是代码更紧江清晰, 另一个原因是计算机对矩阵及向量运算有大量的优化,效率高于在代码中计算每个元素。
需要注意的是,协方差矩阵是计算样本不同维度之间的协方差,而不是对不同样本计算,所以协方差 矩阵的大小与维度相同。
很多时候我们只关注不同维度间的线性关系,且要求这种线性关系可以互相比较。所以,在计算协方差矩阵之前,通常会对样本进行归一化,包括两部分:
- y ⋅ j = x . j − x ‾ ∘ \mathbf{y}_{\cdot j}=\mathbf{x}_{. j}-\overline{\mathbf{x}}_{\circ} y⋅j=x.j−x∘ 即对样本进行平移,使其重心在原点;
-
z
i
=
y
i
.
/
σ
i
\mathbf{z}_{i}=\mathbf{y}_{i} . / \sigma_{i}
zi=yi./σi 。其中
σ
i
\sigma_{i}
σi 是维度
i
i
i 的标准差。这样消除了数值大小的影响。
这样, 协方差矩阵 Σ ^ \hat{\Sigma} Σ^ 可以写成
Σ ^ = 1 m − 1 ∑ j = 1 m z . j z ⋅ j T \hat{\Sigma}=\frac{1}{m-1} \sum_{j=1}^{m} \mathbf{z}_{. j} \mathbf{z}_{\cdot j}^{T} Σ^=m−11j=1∑mz.jz⋅jT
该矩阵内的元素具有可比性。
四、方差,标准差与协方差之间的联系与区别
- 方差和标准差都是对一组(一维)数据进行统计的,反映的是一维数组的离散程度;而协方差是对2组数据进行统计的,反映的是2组数据之间的相关性。
- 标准差和均值的量纲(单位)是一致的,在描述一个波动范围时标准差比方差更方便。比如一个班男生的平均身高是170cm,标准差是10cm,那么方差就是10cm^2。可以进行的比较简便的描述是本班男生身高分布是170±10cm,方差就无法做到这点。
- 方差可以看成是协方差的一种特殊情况,即2组数据完全相同。
协方差的计算公式为:
σ ( x , y ) = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) \sigma(\boldsymbol{x}, \boldsymbol{y})=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right) σ(x,y)=n−11i=1∑n(xi−xˉ)(yi−yˉ)
其中, n n n 表示样本量,符号 x ˉ , y ˉ \bar{x}, \bar{y} xˉ,yˉ 分别表示两个随机变量所对应的观测样本均值。
当 y = x \boldsymbol{y}=\boldsymbol{x} y=x 时,有:
σ ( x , x ) = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( x i − x ˉ ) = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 \begin{aligned} \sigma(\boldsymbol{x}, \boldsymbol{x}) &=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(x_{i}-\bar{x}\right) \\ &=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2} \end{aligned} σ(x,x)=n−11i=1∑n(xi−xˉ)(xi−xˉ)=n−11i=1∑n(xi−xˉ)2
即:方差 σ x 2 \sigma_{x}^{2} σx2 可视作随机变量 x x x 关于其自身的协方差 σ ( x , x ) \sigma(x, x) σ(x,x) 。 - 协方差只表示线性相关的方向,取值正无穷到负无穷。
五、相关系数
相关度的大小了:相关系数
协方差的相关系数,不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。也就是说,相关系数为正值,说明一个变量变大另一个变量也变大;取负值说明一个变量变大另一个变量变小,取0说明两个变量没有相关关系。同时,相关系数的绝对值越接近1,线性关系越显著。
相关系数:
1、也可以反映两个变量变化时是同向还是反向,如果同向变化就为正,反向变化就为负。
2、由于它是标准化后的协方差,因此更重要的特性来了:它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
计算公式为:就是用X、Y的协方差除以X的标准差乘以Y的标准差。
ρ
=
Cov
(
X
,
Y
)
σ
X
σ
Y
\rho=\frac{\operatorname{Cov}(X, Y)}{\sigma_{X} \sigma_{Y}}
ρ=σXσYCov(X,Y)

在概率论中,两个随机变量 X 与 Y 之间相互关系,大致有下列3种情况:
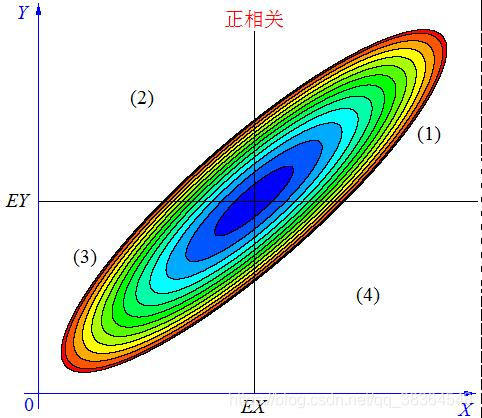 |  |  |
当 X, Y 的联合分布像左图那样时,我们可以看出,大致上有: X 越大 Y 也越大, X 越小 Y 也越小,这种情况,我们称为 “正相关”。
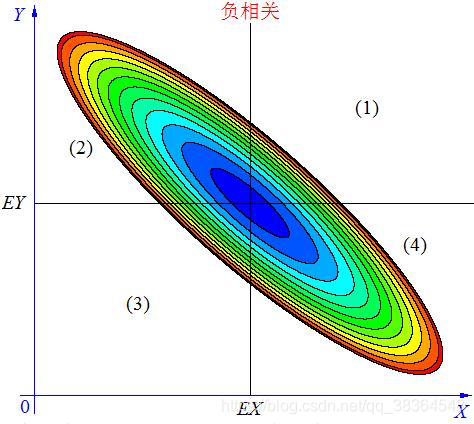
当X, Y 的联合分布像中图那样时,我们可以看出,大致上有:X 越大Y 反而越小,X 越小 Y 反而越大,这种情况,我们称为 “负相关”。
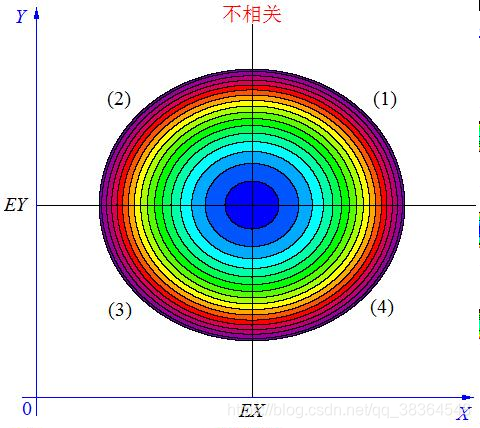
当X, Y 的联合分布像右图那样时,我们可以看出:既不是X 越大Y 也越大,也不是 X 越大 Y 反而越小,这种情况我们称为 “ 不相关”。
怎样将这3种相关情况,用一个简单的数字表达出来呢?
-
在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
-
在图中的区域(2)中,有 X<EX ,Y-EY>0 ,所以(X-EX)(Y-EY)<0;
-
在图中的区域(3)中,有 X<EX ,Y-EY<0 ,所以(X-EX)(Y-EY)>0;
-
在图中的区域(4)中,有 X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
当X 与Y 正相关时,它们的分布大部分在区域(1)和(3)中,小部分在区域(2)和(4)中,所以平均来说,有E(X-EX)(Y-EY)>0 。
当 X与 Y负相关时,它们的分布大部分在区域(2)和(4)中,小部分在区域(1)和(3)中,所以平均来说,有(X-EX)(Y-EY)<0 。
当 X与 Y不相关时,它们在区域(1)和(3)中的分布,与在区域(2)和(4)中的分布几乎一样多,所以平均来说,有(X-EX)(Y-EY)=0 。
所以,我们可以定义一个表示X, Y 相互关系的数字特征,也就是协方差
c
o
v
(
X
,
Y
)
=
E
(
X
−
E
X
)
(
Y
−
E
Y
)
cov(X, Y) = E(X-EX)(Y-EY)
cov(X,Y)=E(X−EX)(Y−EY)
-
当 cov(X, Y)>0时,表明 X与Y 正相关;
-
当 cov(X, Y)<0时,表明X与Y负相关;
-
当 cov(X, Y)=0时,表明X与Y不相关。
这就是协方差的意义。
协方差矩阵的主对角线就是方差,反对角线上的就是两个变量间的协方差。
就上面的二元高斯分布而言,协方差越大,图像越扁,也就是说两个维度之间越有联系。
参考文献
https://blog.csdn.net/northeastsqure/article/details/50163031

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









