







1.传统RNN存在的问题
在循环神经网络一文中,对前向传播、后向传播进行了仔细的推导,回顾一下,可以发现传统RNN很容易产生梯度消失、爆炸的问题。

可能公式会显得有点抽象,这里举一个例子:

那么,LSTM是如何解决这个问题的呢?
2.RNN && LSTM
如图1所示,这就是一个传统的RNN模型,激活函数用的是tanh
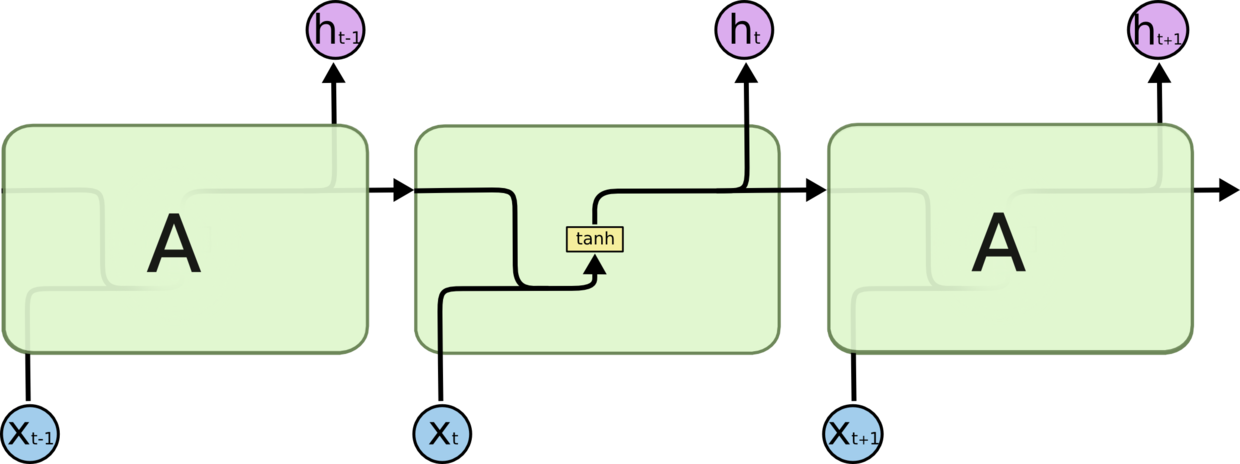
图2与图1拥有类似的网络结构,只不过内部会更加复杂,即包括输入、忘记、输出门。
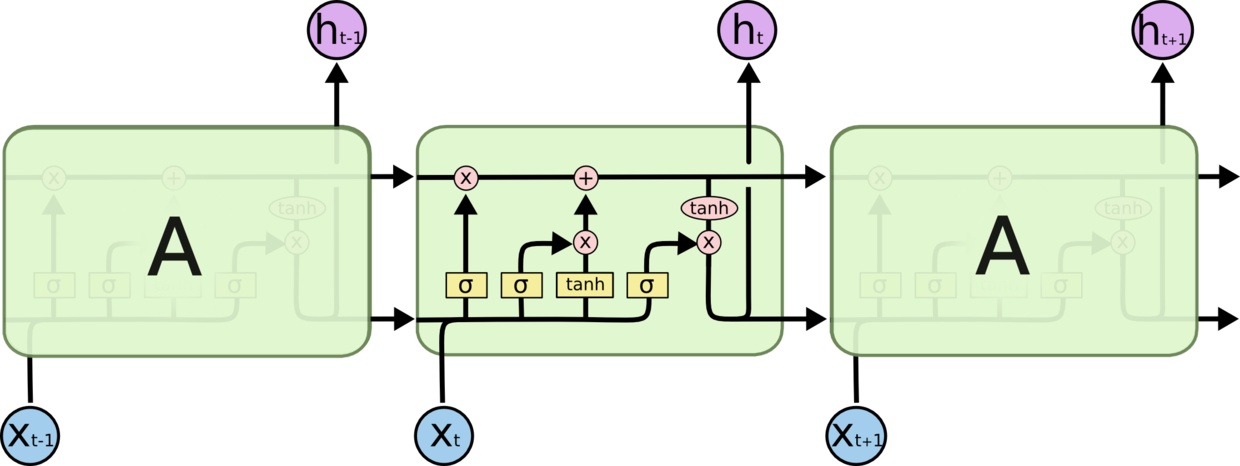
下面,我们来看看LSTM每一个门具体是如何运转的
3.初识LSTM
在介绍LSTM各个门之间如何运作之前,先看下LSTM网络中图标的含义,如图3所示:

LSTM 通过精心设计称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 函数和一个 pointwise 乘法操作。

下面,依据图2从左到右依次介绍:
忘记门(forget gate),利用sigmoid函数将数据转换到[0,1]区间,从而实现“忘记”。

输入门(input gate)

更新细胞(cell)状态

输出门(output gate)

至此,也完成了LSTM前向传播的介绍过程
4.LSTM变体
(1)Gers & Schmidhuber (2000)增加了 “peephole connection”。即让门层也会接受细胞状态的输入。

(2)通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是同时做出决定。仅仅当将要输入在当前位置时忘记,仅仅输入新的值到那些已经忘记旧的信息的那些状态 。

(3)Gated Recurrent Unit (GRU),由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单(减少了一个门),也是非常流行的变体。

5.换个角度看LSTM、GRU
下面把LSTM、GRU的核心部分分解开来看:
LSTM:

其中:

GRU:

其中:

6.前向传播、反向传播推导
下面的推导公式来自于参考文献2
定义:
- 
- the network input to unit j at time t is denoted 
- activation of unit j at time t is 
- The subscripts 


- The subscripts c refers to one of the C memory cells
- The peephole weights from cell c to the input, forget and output gates are denoted 


- 
- f is the activation function of the gates, and g and h are respectively the cell input and output activation functions
- Let I be the number of inputs, K be the number of outputs and H be the number of cells in the hidden layer.
前向传播:


后向传播:

推荐:一份不错的RNN(LSTM)代码:
(1)rnn-from-scratch
(2)lstm for learning
参考文献:
(1)http://colah.github.io/posts/2015-08-Understanding-LSTMs/
(2)A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.
(3)DeepLearning for NLP















 2257
2257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









