







论文发表在ECCV2014
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
Introduction
CNN 在视觉领域虽然取得了很大的成就,但是一直存在一个技术问题是CNN都需要一个固定的图片大小,比如224*224,这限制了输入图像的大小和比例。现在的方法主要是通过crop/warp来满足对图像大小的要求,问题在于最后的图片可能产生了我们并不希望有的几何形变,识别率也会因为内容的丢失和形变而受到影响。如图:
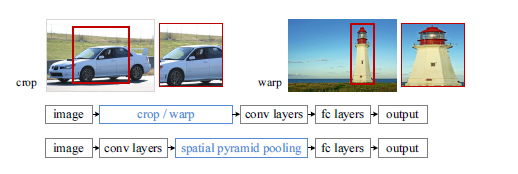
那为什么需要一个固定的大小呢?CNN主要由CONV层和FC层组成。而CONV层是通过滑动窗口的形式来进行feature map, 对图像大小并没有要求;但是FC层需要有一个固定的输入,因此限制来自于FC层。SPP就是为解决这个问题而诞生的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









