







一. 整体思路和问题转化.
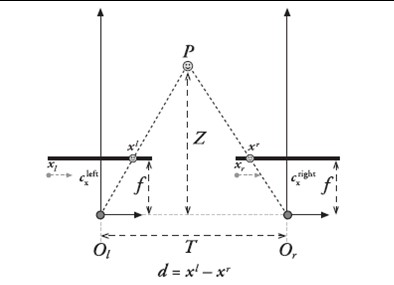
图1. 双摄像头模型俯视图
图1解释了双摄像头测距的原理,书中Z的公式如下:
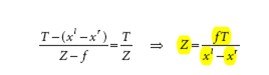
在OpenCV中,f的量纲是像素点,T的量纲由定标棋盘格的实际尺寸和用户输入值确定,一般总是设成毫米,当然为了精度提高也可以设置为0.1毫米量级,d=xl-xr的量纲也是像素点。因此分子分母约去,z的量纲与T相同
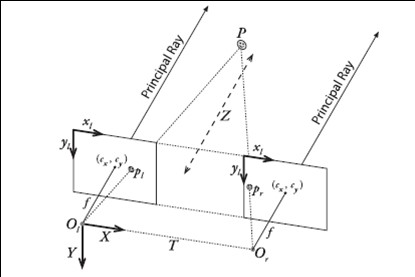
图2, 双摄像头模型立体视图
图2解释了双摄像头获取空间中某点三维坐标的原理。
注意,左镜头光心是世界坐标系的原点,该坐标系是左手屏幕坐标系,所以在该点上方,前方的物体,他的世界坐标中,Y是负数.

可以看到,实际的坐标计算利用的都是相似三角形的原理,其表达式就如同Q矩阵所示。空间中某点的三维坐标就是(X/W, Y/W, Z/W)。所以,得到了Q矩阵,就是得到了一个点的世界坐标.
因此,为了精确地求得某个点在三维空间里的距离,我们需要获得的参数有焦距f、视差d、摄像头中心距Tx。如果还需要获得X坐标和Y坐标的话,那么还需要额外知道左右像平面的坐标系与立体坐标系中原点的偏移cx和cy。
要测距,就又有这五个参数.
f, Tx, cx和cy可以通过立体标定获得初始值,并通过立体校准优化,使得两个摄像头在数学上完全平行放置,并且左右摄像头的cx, cy和f相同(也就是实现下图中左右视图完全平行对准的理想形式)。
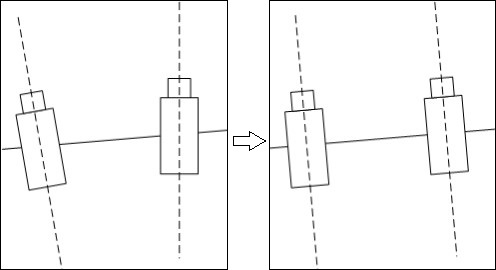
立体匹配所做的工作,就是在之前的基础上,求取最后一个变量:视差d(这个d一般需要达到亚像素精度)。从而最终完成求一个点三维坐标所需要的准备工作。
总结:使用OpenCV进行的立体视觉测距,其实思路是这样的:根据摄像头的成像原理(表现为小孔成像等效模型)和具体设备的成像特性(表现为光心距离,两个焦距,两个镜头安装的相对位置),设法建立像和真实世界的映射关系(表现为上述五个参数),并以摄像机系统为参考系,为真实世界建立绝对坐标系(该坐标系的具体形式请看下文),通过上述映射关系,该方法能够把像点所在的世界坐标位置求解出来,实现距离测量.
在清楚了上述原理之后,我们也就知道了,所有的这几步:标定、校准和匹配,都是围绕着如何更精确地获得f, d, Tx, cx和cy而设计的。
二. OpenCV2.4.11的实现.
按照上述解释,步骤是这样的:
1.准备工作:依次完成:标定->校准->匹配这三个操作,获得所需的参数:
T_x,f,d, C_x, C_y.其中,标定和校准的目的是求解Q矩阵,匹配的目的是求解视差值d.
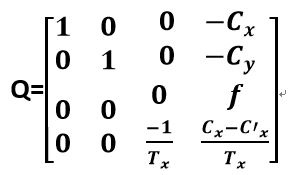
2. 通过某种手段,获得待测点在”像世界”中的坐标(x.y),构造向量:
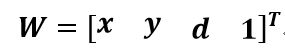
3. 通过Q•W运算,得到世界坐标向量,进而计算距离.
4. 具体实现步骤:
(1)标定和矫正
函数 findChessboardCorners()以标定盘图片和标定盘参数为输入,得到立体标定的输入参数;
函数:stereoCalibrate()输出变量:
R – Output rotation matrix (旋转)
T – Output translation vector(平移)
E – Output essential matrix.(本征)
F – Output fundamental matrix.(基础)
函数:stereoRectify()的输入变量已经从上面得到,他的输出变量如下:
R1 – Output 3x3 rectification transform (rotation matrix) for the first camera.
R2 – Output 3x3 rectification transform (rotation matrix) for the second camera.
P1 – Output 3x4 projection matrix in the new (rectified) coordinate systems for the first camera.
P2 – Output 3x4 projection matrix in the new (rectified) coordinate systems for the second camera.
Q – Output disparity-to-depth mapping matrix
(2)匹配
OpenCV2.4.11中提供了若干种匹配方法,这里采用的是BM,SGBM,VAR算法,这三个算法在使用的时候都需要构造相应的对象,对其中的输入属性进行设置,利用其提供的”()”操作符的重载执行相关的算法.他们都要求输入左右视图,输出视差图,具体情况如下:
SGBM: left – Left 8-bit single-channel or 3-channel image.
right – Right image of the same size and the same type as the left one.
disp – Output disparity map. It is a 16-bit signed single-channel image of the same size as the input image. It contains disparity values scaled by 16. So, to get the floating-point disparity map, you need to divide each disp element by 16.
BM: left – Left 8-bit single-channel image.
right – Right image of the same size and the same type as the left one.
disparity – Output disparity map. It has the same size as the input images. When disptype==CV_16S, the map is a 16-bit signed single-channel image, containing disparity values scaled by 16. To get the true disparity values from such fixed-point representation, you will need to divide each disp element by 16. If disptype==CV_32F, the disparity map will already contain the real disparity values on output.
disptype – Type of the output disparity map, CV_16S (default) or CV_32F.
Var: left – Left 8-bit single-channel or 3-channel image.
right – Right image of the same size and the same type as the left one.
disp – Output disparity map. It is a 8-bit signed single-channel image of the same size as the input image.
输出统一以8位视差图计算,不是8位转换成8位.全部采用CV_16S制式.
(3)取得待测点的图像空间坐标值
这一步很简单,只需要设法获取图片上的某个点的坐标就可以,此坐标只是相对于图片本身而言,所以可以使用例如鼠标点击或输入坐标的方法
(4)已经得到了全部的数据,利用Q矩阵进行计算就可以了.
三.FAQ:
Q1:标定时棋盘格的大小如何设定,对最后结果有没有影响?
A:当然有。在标定时,需要指定一个棋盘方格的长度,这个长度(一般以毫米为单位,如果需要更精确可以设为0.1毫米量级)与实际长度相同,标定得出的结果才能用于实际距离测量。一般如果尺寸设定准确的话,通过立体标定得出的Translation的向量的第一个分量Tx的绝对值就是左右摄像头的中心距。一般可以用这个来验证立体标定的准确度。比如我设定的棋盘格大小为270 (27mm),最终得出的Tx大小就是602.8 (60.28mm),相当精确。
Q2:通过立体标定得出的Tx符号为什么是负的?
A:这个其实我也不是很清楚。个人的解释是,立体标定得出的T向量指向是从右摄像头指向左摄像头(也就是Tx为负),而在OpenCV坐标系中,坐标的原点是在左摄像头的。因此,用作校准的时候,要把这个向量的三个分量符号都要换一下,最后求出的距离才会是正的。
但是这里还有一个问题,就是Learning OpenCV中Q的表达式,第四行第三列元素是-1/Tx,而在具体实践中,求出来的实际值是1/Tx。这里我和maxwellsdemon讨论下来的结果是,估计书上Q表达式里的这个负号就是为了抵消T向量的反方向所设的,但在实际写OpenCV代码的过程中,那位朋友却没有把这个负号加进去。(一家之言,求更详细的解释)
Q3:cvFindStereoCorrespondenceBM的视差输出结果单位是?
A:在OpenCV中,BM函数得出的结果是以16位符号数的形式的存储的,出于精度需要,所有的视差在输出时都扩大了16倍(2^4)。其具体代码表示如下:
dptr[y*dstep] = (short)(((ndisp - mind - 1 + mindisp)*256 + (d != 0 ? (p-n)*128/d : 0) + 15) >> 4);
可以看到,原始视差在左移8位(256)并且加上一个修正值之后又右移了4位,最终的结果就是左移4位
因此,在实际求距离时,cvReprojectTo3D出来的X/W,Y/W,Z/W都要乘以16 (也就是W除以16),才能得到正确的三维坐标信息
Q4:利用双摄像头进行测距的时候世界坐标的原点究竟在哪里?
A:世界坐标系的原点是左摄像头凸透镜的光心。
说起这个,就不得不提到针孔模型。如图3所示,针孔模型是凸透镜成像的一种简化模型。当物距足够远时(远大于两倍焦距),凸透镜成像可以看作是在焦距处的小孔成像。
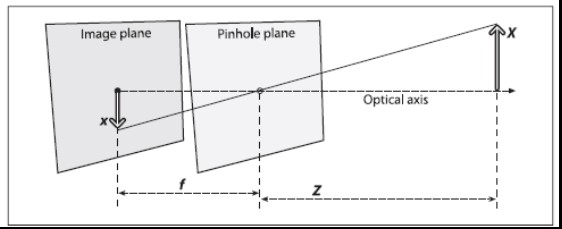
在实际计算过程中,为了计算方便,我们将像平面翻转平移到针孔前,从而得到一种数学上更为简单的等价形式(方便相似三角形的计算),如下图所示。
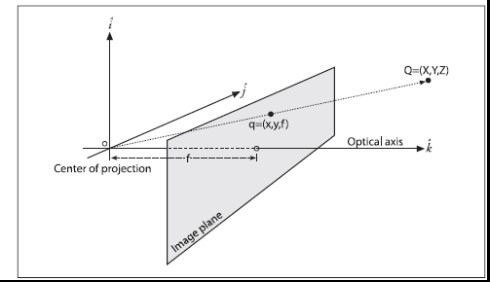
因此,对应图2就可以知道,世界坐标系原点就是左摄像头针孔模型的针孔,也就是左摄像头凸透镜的光心
Q5:f和d的单位是像素,那这个像素到底表示什么,它与毫米之间又是怎样换算的?
A:这个问题也与针孔模型相关。在针孔模型中,光线穿过针孔(也就是凸透镜中心)在焦距处上成像,因此,图3的像平面就是摄像头的CCD传感器的表面。每个CCD传感器都有一定的尺寸,也有一定的分辨率,这个就确定了毫米与像素点之间的转换关系。举个例子,CCD的尺寸是8mm X 6mm,分辨率是640X480,那么毫米与像素点之间的转换关系就是80pixel/mm。
在实际运用中,我们在数学上将这个像平面等效到小孔前(图4),这样就相当于将在透镜中心点之前假设了一块虚拟的CCD传感器。
Q6:为什么cvStereoRectify求出的Q矩阵cx, cy, f都与原来的不同?
A:这个在前文有提到过。在实际测量中,由于摄像头摆放的关系,左右摄像头的f, cx, cy都是不相同的。而为了使左右视图达到完全平行对准的理想形式从而达到数学上运算的方便,立体 校准所做的工作事实上就是在左右像重合区域最大的情况下,让两个摄像头光轴的前向平行,并且让左右摄像头的f, cx, cy相同。因此,Q矩阵中的值与两个instrinsic矩阵的值不一样就可以理解了。















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









