







Abstract
网络不断向更深发展,但是有时候为了得到少量的accuracy的增加,却需要将网络层数翻倍,也会减少feature的reuse,降低训练速度。作者提出了wide residual network,16层的表现就比之前的ResNet效果要好。
1 Introduction
ResNets因为过深,很多residual block只能提供少量的信息,或者只有少量的block能学到重要的信息。作者的16层网络能与1000层的resnet类似,所以作者认为ResNet的主要的能力来自于Residual block ,深度的增加只是辅助而已。
论文认为本文贡献在于:
1. 对ResNet block结构的几个重要方面进行了实验;
2. 提出了widened architecture 而且更好;
3. 提出了deep residual networks使用dropout的新方法
2 Wide residual network
上图中a,b是kaiming提出的两种方法,b计算更节省,但是作者想看 宽度的影响所以采用了a。作者提出增加residual block的三种简单途径:
1. 更多卷基层
2. 加宽(more feature planes)
3. 增加卷基层的filter sizes
作者说小的filters更高效,所以不准备使用超过3x3的卷积核,提出了宽度放大倍数k和卷积层数l,作者的结构:
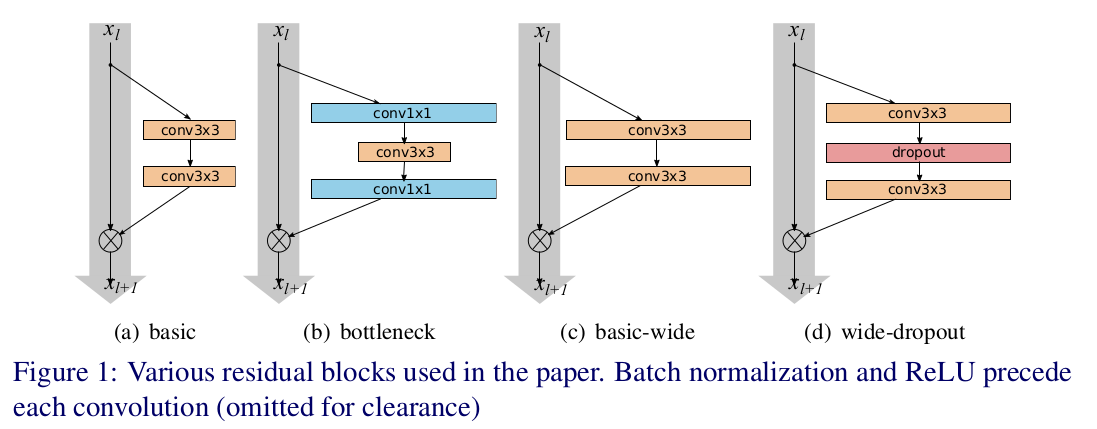

2.1 type of convolutions
B(M)表示卷基层的结构,M是层数,如B(3,1,1)就是NIN。
2.3 width of residual blocks
参数随着长度的增加成线性增长,但是随着width却是平方增大,虽然参数会增多,但是卷积运算更适合gpu。
参数的增多需要regularization来减少过拟合,He使用了batch normalization,可是这种方法需要heavy augmentation,作者使用了dropout。
3 Experimental results
分别确定了block的形式,每个block的conv层数及宽度。
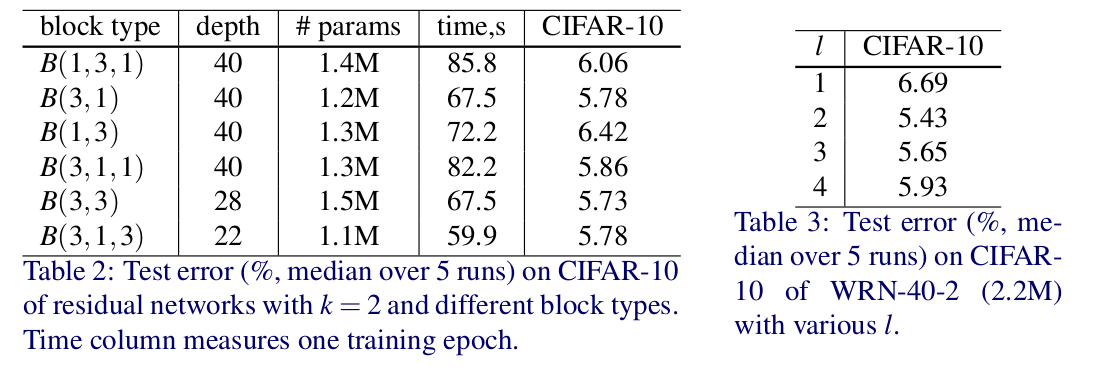
几种方案看起来差不多 就选用3x3了,由图3可以看出B(3,3)比B(3,3,3,3)B(3,3,3)B(3)要好,前两者可能是因为优化困难。
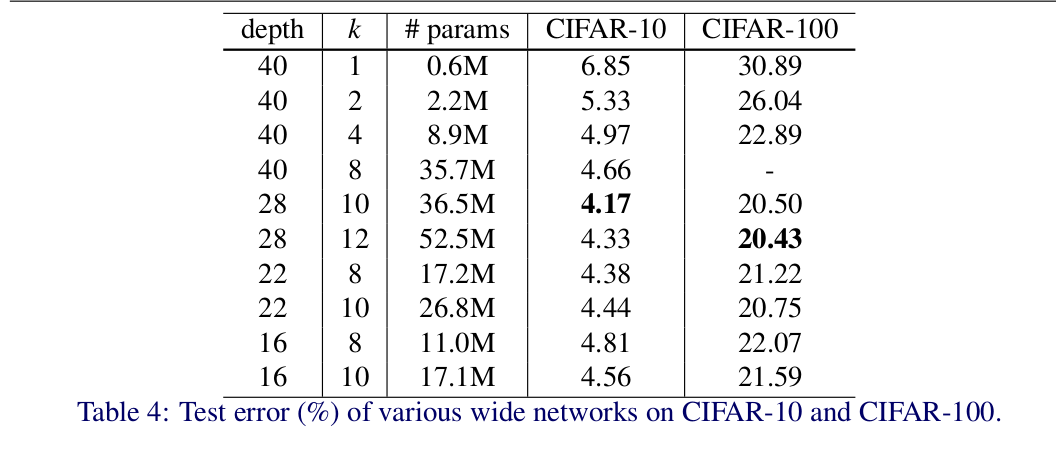
作者研究了宽度的选择:
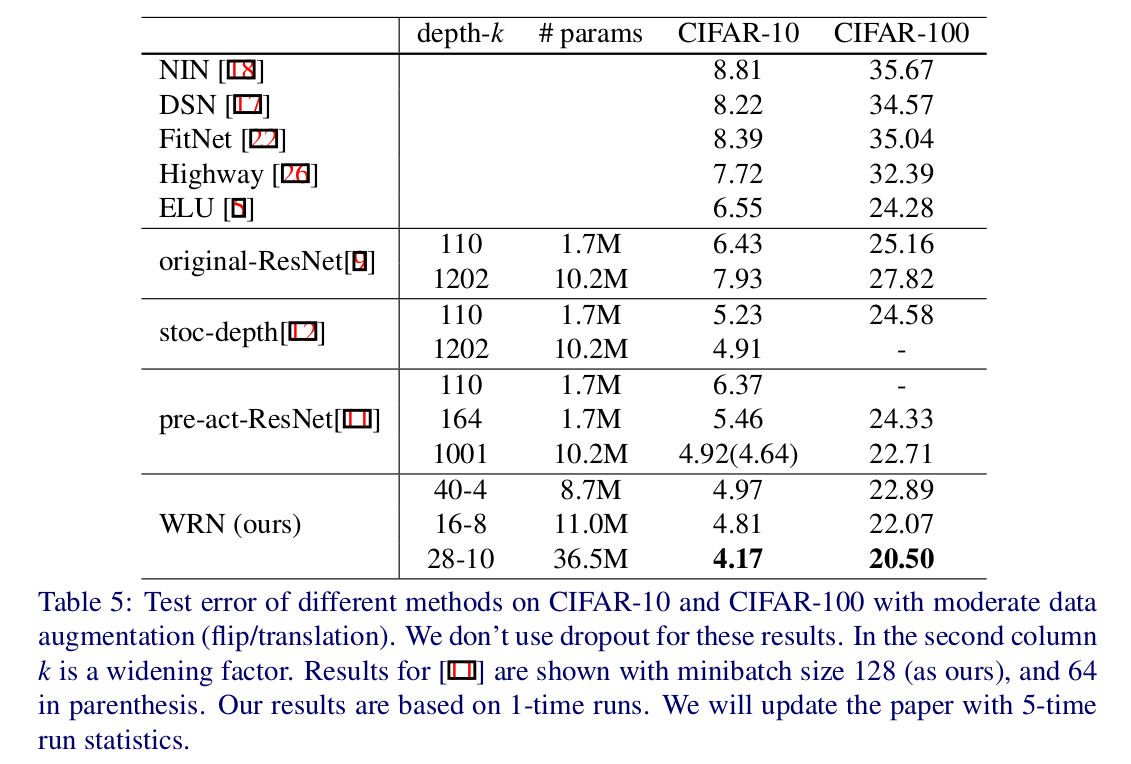
WRN40-4与ResNet1001结果相似,参数数量相似,但是前者训练快8倍。
总结:
1. 宽度的增加提高了性能
2. 增加深度和宽度都有好处,直到参数太大,regularization不够
3. 相同参数时,宽度比深度好训练
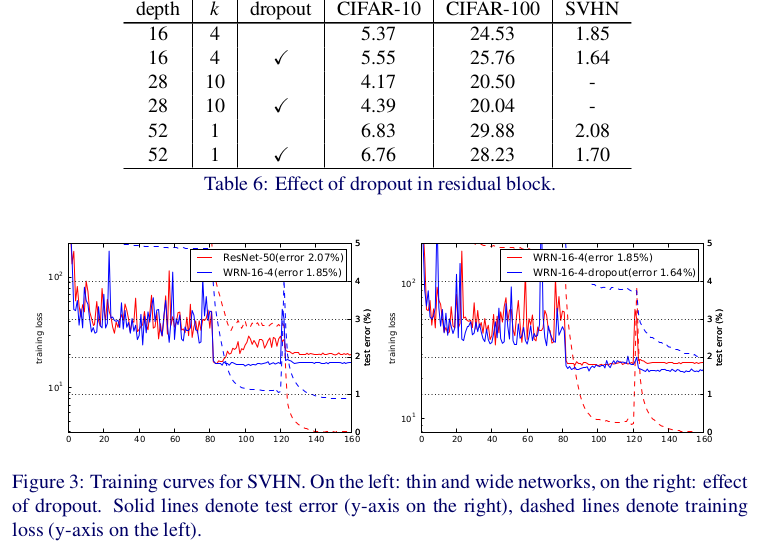
Dropout in residual block
对于参数较少的16-4得到的结果反而差了。
implementation details
1. Torch
2. sgd+nesterov+cross-entropy loss
3. weight decay 0.0005 dampening=0,momentum=0.9 minibatch128
4. CIFAR lr0.1 60 120 160 epoch x 0.2 共200epochs
5. SVHN lr0.01 80 120 epoch x0.1 共160
作者git主页
https://github.com/szagoruyko/wide-residual-networks
本质上,其实跟ResNet一样,只是,针对ResNet的瓶颈块通道数加多了,作者比较了不同深度和宽度的效果,其实就是GoogleNet中提出的宽度和深度平衡,同时,作者又测试了dropout和BN同时使用的效果,之前有结论是 BN可以替代dropout,实际上,还是看dropout的位置,测试表明dropout和BN一起使用,还是可以提高效果,这与我自己的经验也一致。















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









