






转自:http://blog.csdn.net/u011718701/article/details/53762969 略增删改
MultiPathNet
A MultiPath Network for Object Detection
- intro: BMVC 2016. Facebook AI Research (FAIR)
- arxiv: http://arxiv.org/abs/1604.02135
- github: https://github.com/facebookresearch/multipathnet
FAIR用于发现和切割单张图像中每个物体的开源项目,这一技术的主要驱动算法是DeepMask——一个新的图像分割框架,以及SharpMask——一个图像分割refine模型,二者结合使得FAIR的机器视觉系统能够感知并且精确的描绘一张图片中任何物体的轮廓。这一识别管道中的最后一步,研究院使用了一个特殊的卷积网络,称为MultiPathNet,为图片中检测到的物体添加标签。也就是说Facebook研究院的物体检测系统遵循一个三阶段的过程:(1)DeepMask生成初始物体mask(2)SharpMask优化这些mask(3)MutiPathNet识别每个mask框定的物体。
DeepMask的技巧是把分割看成是一个海量的二进制分类问题
- 对一张图像中的每一个重叠的图像块:这个图像块包含一个物体吗?如果包含,那对于一个图像块中的每个像素:这个像素是图像块中心物体的一部分吗?用深度网络来回答每一个Yes/No的问题
- 上层功能以相当低的空间分辨率计算,这为mask预测带来一个问题:mask能捕捉一个物体大致外形,但不能准确捕捉物体边界。
SharpMask优化DeepMask的输出,产生具有更高保真度的能精确框定物体边界的mask
- 在DeepMask预测前向通过网络时,SharpMask反转信息在深度网络的流向,并通过使用progressively earlier layers的特性来优化DeepMask做的预测。
- 要捕捉物体外形,你必须高度理解你正在看的是什么(DeepMask);但是要准确框出边界,你需要使用低层次的特性一直到像素级(SharpMask)
DeepMask不知道具体对象类型,尽管可以框定但不能区分物体;以及没有选择性,会为不是很有趣的图像区域生成mask
- 训练一个单独的深度网络来对每一个DeepMask产生的mask的物体类型进行分类(包括“无”),采用R-CNN
- 改进是使用DeepMask作为R-CNN的第一阶段。
- 对于RCNN的第二阶段,使用一个专门的网络架构来对每一个mask进行分类,也就是MultiPathNet,允许信息以多种路径通过网络,从而使其能够在多种图像尺寸和图像背景中挖掘信息。
一、DeepMask【Learning to Segment Object Candidates.2015 NIPS】
整体来讲,给定一个image patch作为输入,DeepMask会输出一个与类别无关的mask和一个相关的score估计这个patch完全包含一个物体的概率。它最大的特点是不依赖于边缘、超像素或者其他任何形式的low-level分割,是首个直接从原始图像数据学习产生分割候选的工作。还有一个与其他分割工作巨大的不同是,DeepMask输出的是segmentation masks而不是bounding box。【masks其实就是每个像素都要标定这个像素属不属于一个物体,bounding box是比较粗略的】
1.网络结构
首先搞清楚网络输入,训练阶段,网络的一个输入样本k是一个三元组,包括:(1)image patch xk;(2)与image patch对应的二值mask,标定每个像素是不是物体;(3)与image patch对应的标签yk,yk=1需要满足两个条件:一是这个patch包含一个大致在中间位置的物体,二是物体在一定尺度范围内是全部包含在这个patch里的。否则yk=-1,包括patch只包含一个物体的一部分的情况。注意只有yk=1的时候,mask才用,yk=-1时不使用mask。
网络结构图:

显然,本文用了ImageNet上预训练好的VGG-A模型来初始化网络,包含8个3*3的卷积层、5个2*2的max-pooling层和3个全连接层。做的改动是去掉VGG-A最后的3个全连接层以及最后的1个pooling层,那么剩下8个卷积层和4个pooling层。由于卷积层保持空间分辨率不变,只有pooling层会造成空间分辨率减半,所以4个pooling层就会使得图像的分辨率缩小16倍。所以原来是h*w*3的输入,会变成(h/16)*(w/16)*512的输出(h=w=224的时候就是上图中14*14*512的输出啦)。好让我们继续往下走,刚才说网络需要完成两个任务:输出一个mask,以及给出这个patch包含一个物体的score,所以后面会接两个并列的网络(multi-task learning一般都是这样的结构):segmentation和scoring。
Segmentation
用于分割的分支由一个1*1的卷积层后接一个分类层组成。
分类层希望有h*w个pixel分类器,每个分类器都负责判断某个像素是否属于位于patch中心的那个物体。但是原图太大啦,所以缩小成h0*w0,那么就有h0*w0个pixel分类器啦。注意:我们希望输出平面上的每一个pixel分类器都能够利用整个512*14*14大小的feature map的信息,这样就能够“看到”整个物体,这一点很重要,因为即使存在着好几个物体,网络输出的也只是对一个物体的mask。
分类层怎么实现的呢?把分类层分解为两个线性层,第一层把512*14*14的feature map变为512*1*1的输出【博主猜是14*14*512的卷积层,或者是像Fast R-CNN里RoI pooling层那样的映射,每个通道映射为1个值,一共512个输入通道所以输出就是512*1*1啦】,第二层把512*1*1的输出变成大小为h0(56)*w0(56)*1的mask,两层中间没有ReLU非线性。h0和w0都小于原image大小,所以还要经过上采样恢复原图大小。
Scoring
用于打分的分支由一个2*2的max-pooling层后接两个全连接层【博主注意到上面的结构图里第一个所谓的全连接层是将512*7*7的输入变成512*1*1的输出,而且看这意思好像是输出的每个通道只和输入的相应通道的14*14个神经元连接,每个通道独立进行的,跟传统意义上全连接似乎不太一样呢~但它和segmentation的第一个线性层画得一样,这就印证了博主的想法:这两个网络的第一个由512*14*14或者512*7*7映射到512*1*1的应该是每个通道独立进行的FC层,和Fast R-CNN里RoI pooling层一样】组成,两层之间带有ReLU非线性。最终的输出是一个objecness score,指示输入patch的中心是否有物体存在。
2.联合学习
由于有两个优化任务,所以loss function肯定是两项啦:

反向传播在segmentation分支和scoring分支交替进行就好了。
3.整图推断
整张图时,在图像的各种位置和尺寸上密集地应用这个模型,stride是16像素,缩放尺度在1/4到2(步长根号2),那么在每个图像位置都会给出一个分割mask和object score。
注意到,segmentation分支的下采样因子是16,scoring分支的是32(因为多了一个max pooling),为了获得从mask预测到object score的一对一映射,在scoring分支最后一个max-pooling层前应用了一个交织的trick来double它的空间分辨率。
4.其他细节
训练时,一个输入patch被标记是包含一个典型的正样本,如果有物体在patch的正中间并且最大维度正好等于128像素。然而,给一个物体在patch中的位置一些容忍度是很关键的,因为在full image inference时多数物体都是和它的典型位置有一些偏移的。因此在训练时,随机抖动每个典型的正样本来增加模型的鲁棒性。具体来讲,在±16像素范围内进行平移,尺度变换在2的±1/4次方范围,还有水平翻转。在所有情况下都是对image patch和它的ground truth mask一起做同样的变换了啦,每个都assign一个正的label。负样本是任何patches至少有±32像素的平移或者2的±1次方的尺度 from 任何典型正样本。
结构设计和超参数选择使用MS COCO验证数据的子集,和evaluation阶段的数据不重叠。
学习率设为0.001,随机梯度下降的batch size是32个样本,momentum设为0.9,weight decay设为0.00005。
二、SharpMask【Learning to Refine Object Segments.2016 ECCV】
从名字就能看出来,主要为了是refine DeepMask的输出。DeepMask的问题在于它用了一个非常简单的前向网络产生粗略的object mask,但不是像素级别准确的分割。显然因为DeepMask采用了双线性上采样以达到和输入图像相同大小这一机制,使得物体边缘是粗略估计出来的,不准确。SharpMask的insight来自,物体精确地边缘信息可以从low-level图像中得到,与网络高层的物体信息结合,应该能够得到比较精确的边缘。因此主要的思路是,首先用DeepMask生成粗略的mask,然后把这个粗略的mask通过贯穿网络的很多refinement模块,生成最终的精细mask。
1.网络结构
显然网络信息流除了传统的自下而上,还得有自上而下的通道,网络结构是:
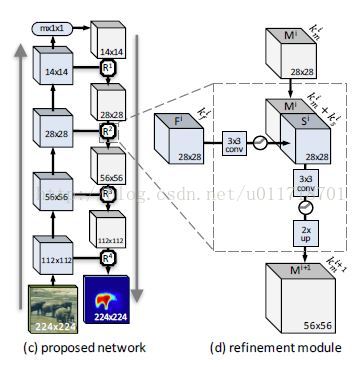
可以看到自下而上的过程是传统的前向CNN网络,比如DeepMask(本文后面还调研了其他网络结构 例如ResNet等),输出一个粗略的mask,然后需要逐层融合low-level的特征来找到精确的物体边缘等信息。
2.Refinement 模块
refinement模块的作用是逆转pooling的作用,输入上层传下来的mask encoding和自下而上传递过来的匹配的features map,并且融合两个过程的信息来生成一个新的mask encoding,有着两倍的空间分辨率。这个过程一直持续到patch的全部分辨率被恢复,然后最后的输出就是精细的object mask。
Refinement细节
每个模块Ri的输入是来自上一层的mask Mi和来自下一层的feature Fi(是pooling前的卷积层的输出),他们的空间分辨率是相同的,通道数分别是kmi和kfi,refinement要完成的就是Mi+1 = Ri(Mi,Fi)。通常,kfi很大,而且远远大于kmi,所以如果直接把它们级联起来的话,一是运算量会特别大,二是会淹没Mi中的信号。
所以文章采取的方式是:首先用一个3*3的卷积层(有ReLU)作用在Fi上,减少它的通道数kfi,但是保持空间分辨率不变,这样就产生了一个‘skip’feature Si,ksi远远小于kfi。现在就可以把Si和Mi直接在通道维度级联起来了,生成ksi+kmi通道的feature map。然后通过一个3*3的卷积层(有ReLU),再经过双线性上采样得到refinement模块的最终输出Mi+1,通道数kmi+1由卷积层的kernel个数决定。
refinement模块的操作只有卷积、ReLU、双线性上采样和级联,因此完全是可以反向传播的。其中比较重要的是ksi和kmi既不能过大使得计算量繁重,也不能过小丢失了信息,所以一开始可以用一个比较大的值,随着空间分辨率越来越大,逐渐减小通道数目。
显然,refinement模块的数目应该等于前向网络中pooling层的数目。
训练和推断过程
训练过程分两个阶段:第一阶段和DeepMask一毛一样;第二阶段,等第一阶段收敛了之后呢,去掉前向网络最后的mask预测层,换成一个线性层,这个线性层产生一个mask encoding M1来代替实际的mask输出。然后“冻住”前向网络的参数不再变化,用SGD训练refinement网络。
整图推断的时候,与DeepMask相似,相邻窗口的大部分计算都通过卷积共享了,包括skip层Si【这里博主一开始没有看懂什么意思。。后来觉得是这样吧,image patch是224像素的,整图推断时候stride是16像素,所以有着很大部分的重叠呢。但是博主又想了,难道你还要搞一个内存记录下那些部分已经被计算过了?真的不会更麻烦吗?用存储换时间?】。不过,refinement模块在每个空间位置都会输入一个唯一的M1,因此这个阶段计算在每个空间位置是独立进行的,就没法子共享啦~
为了减少计算,也不是每个位置的proposal都要refine的啦,而是选择N个score最大的proposal,这N个作为一个batch【SGD的batch】一起优化。
3.前向网络结构研究
文中,把segmentation和scoring共享的叫做Trunk architecture,二者独有的叫做Head architecture。
- Trunk architecture
使用ImageNet上训练好的50层Residual Network代替VGG-A,研究了输入尺寸W、pooling层个数、步长S、模型深度D和最终的feature通道数F。这部分没啥难理解的,就是选择参数,博主就不详细总结了,毕竟我们分析SharpMask是为了借鉴它的思想。
- Head architecture
作者们觉得,原来的结构里mask和score分支都需要比较大的卷积操作,而且score分支还得有个额外的pooling层,太不美观了,所以设计了下列的变形,主要是想让两个分支可以share more computation。
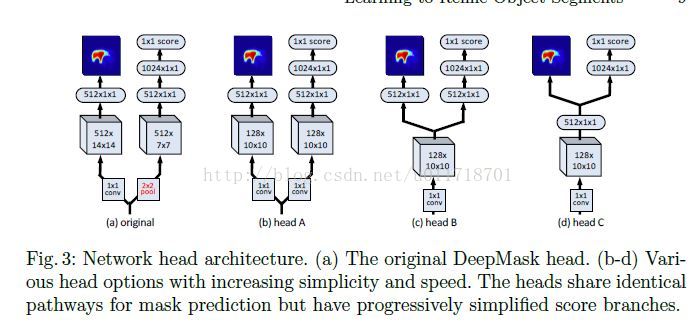
最后通过实验采用W160-P4-D39-F128的trunk architecture和C head architecture作为最终的前向网络,称为DeepMask-ours
DeepMask-ours和refinement一结合,就是我们的主角:SharpMask了,它是2016年COCO数据集上的state-of-the-art。博主觉得最值得借鉴的部分就是想办法把低层的像素级别的信息和高层的物体级别的信息融合,因此未来我们可以设计更好的融合方案,也许能大大提高性能。
三、MultiPathNet【A MultiPath Network for Object Detection.2016 ECCV】
有了DeepMask输出的粗略分割mask,经过SharpMask refine边缘,接下来就要靠MultiPathNet来对mask中的物体进行识别分类了。MultiPathNet目的是提高物体检测性能,包括定位的精确度和解决一些尺度、遮挡、集群的问题。网络的起点是Fast R-CNN,基本上,MultiPathNet就是把Fast R-CNN与DeepMask/SharpMask一起使用,但是做了一些特殊的改造,例如:skip connections、foveal regions和integral loss function。
1.背景工作
显然自从Fast R-CNN出现以来的object detector基本都是将它作为起点,进行一些改造,我们先来总结一下这些改造,以便理解本文的想法。Context
核心思想就是利用物体周围的环境信息,比如有人在每个物体周围crop了10个contextual区域辅助检测。本文就是借鉴这种做法不过只用了4个contextual区域,涉及特殊的结构。
Skip connections
Sermanet提出一个多阶段的分类器利用许多个卷积层的特征来实现行人检测,取得了很好的效果,这种‘skip’结构最近在语义分割方面也很火呐
Classifers
大家都知道现在基本上是CNN结构的天下啦。。。本文用的是VGG-D,如果和何凯明的ResNet结合效果应该会更好哒。
2.网络结构
先上整个结构图:
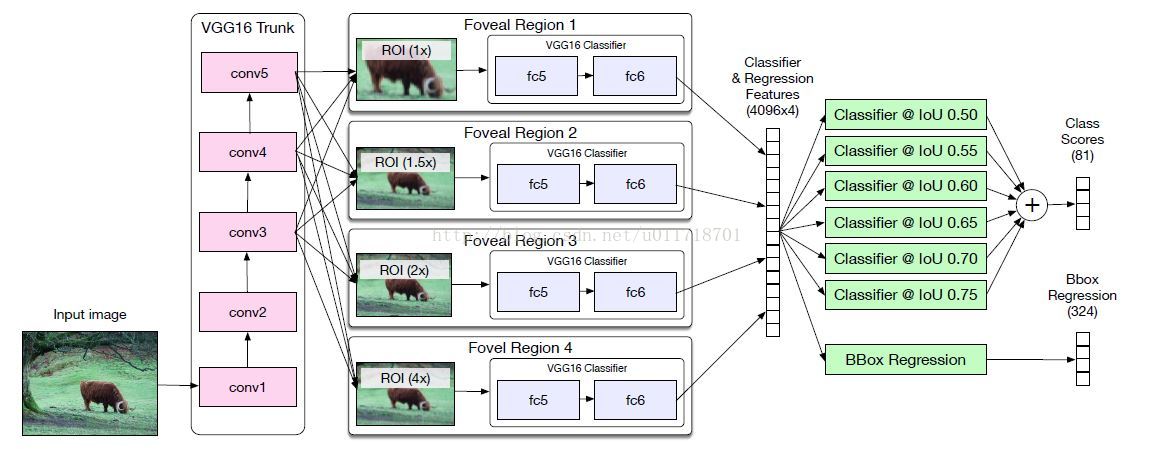
Foveal regions
像Fast R-CNN一样,图像先经过VGG16的13个卷积层生成conv feature map,然后经过RoI pooling层提取特征。从结构图里可以看到,对每个object proposal,都产生4个不同的region crops,相当于从不同的尺度来看这个物体,这就是所谓的‘foveal region’。
Skip connections
VGG16有四个pooling层,所以图像尺寸会/16,那我们设想一个32*32大小的物体,经过VGG16就剩2*2了。虽然RoI pooling层输出7*7的feature map,但是很显然我们损失了太多的空间信息 。
所以呢,要把conv3(/4*256)、conv4(/8*512)、conv5(/16*512)层的【RoI-pooled normalized 】feature级联起来一起送到foveal分类器,这种级联使得foveal分类器可以利用不同位置的特征,有种弥补空间信息损失的味道在里面呢~注意需要用1*1的卷积层把级联特征的维度降低到分类器的输入维度。
文章说,他们只把conv3连接到1×的分类器head,conv4连接到1×、1.5×和2×的head。
- Integral Loss
在原来的Fast R-CNN中,如果一个proposal与一个ground-truth box的IoU大于50,那么就给它分配ground-truth的标签,否则就是0。然后在Fast R-CNN的分类loss里面(用的是log loss),对所有proposal的IoU大于50的一样对待,这其实有点不合理:我们希望IoU越大的对loss的贡献越大吧~所以本文就用Integral loss代替了原来Fast-RCNN的分类loss:
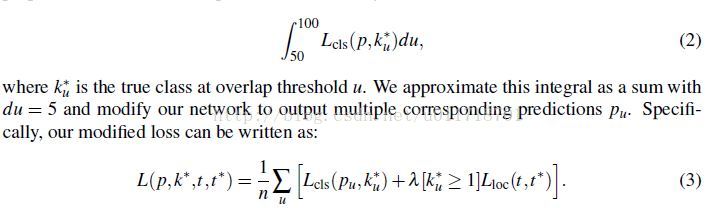
那当然积分就要用加和的方式近似啦,本文选择用n=6个不同的阈值,所以现在对每一个object rpoposal实际上有n个ground-truth label了,每个阈值一个~相应的每个阈值应该也得有一个分类输出的概率吧,所以我们看到结构图最后有6个分类器。在inference的时候,每个分类器的softmax概率输出求平均得到最终的class probabilities。















 3161
3161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









