







面临问题
1,当前深度学习网络规模越来越大,网络规模越来越大,网络中的参数也就也来越多,这就很有可能在训练中造成过拟合的问题。
2,当前的大规模网络涉及的计算量也是非常高,特别对于卷积层,卷积层的增加带来的就是计算量几何级别的上升。
问题思考
一味地位追求识别准确率而增加网络规模有一部分原因就是特征提取模块的设计没有能很好提取出图像的特征,如果能在基本的特征提取单元上做一些优化,然后用优化后的特征提取模块去构建网络,可能会有利于最红的识别效果。
解决方案
GoogLenet提出了Inception module的概念,旨在强化基本特征提取模块的功能,一般的卷积层只是一味增加卷积层的深度,但是在单层上卷积核却只有一种,比如对于VGG,单层卷积核只有3x3大小的,这样特征提取的功能可能就比较弱。GoogLenet想的就是能不能增加单层卷积层的宽度,即在单层卷积层上使用不同尺度的卷积核,GoogLenet构建了Inception module这个基本单元,基本的Inception module中有1x1卷积核,3x3卷积核,5x5卷积核还有一个3x3下采样,如下图所示,
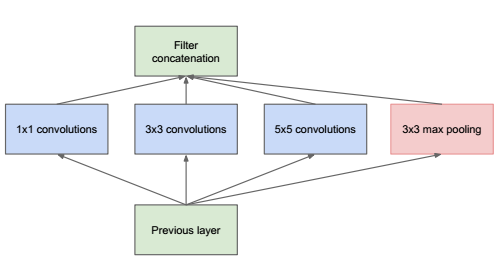
这样尺寸不同的卷积核就可以提取不同尺寸的特征,单层的特征提取能力增强了,但是我在读的过程中想到的问题是,对于像VGG这种网络,我同样可以通过卷积-下采样-卷积这种方式提取不同尺寸的信息,所以为何Inception module这种网络会有很好的效果的,我想到的原因是卷积-下采样-卷积虽然能够提取不同尺寸的信息,但是由于是通过下采样这种方式实现的,所以必会带来信息的丢失,和Inception module这种方式相比,显然丢失的信息更多。
上面Inception module结构会存在一个问题,就是前一层的输出不经任何处理直接输入到下一层的卷积层中,这样如果前一层的特征图数量很多,有经过5x5这种大尺寸的卷积,带来的计算量也是非常大,所以在修正过后的Inception module在输出到下一层卷积之前,会对数据进行一次降维,怎么降维,就是采用1x1卷积核实现,比如原来有256个输入特征图,先用1x1的卷积核对特征图进行线性组合,使得输出只有96的特征图,这样不会带来信息损失,有减小了下一层卷积的计算量,修正后的Inception module如下图所示,
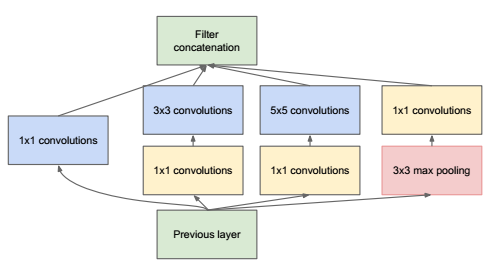
这种Inception module既能大大提升卷积提取特征的能力,又不会使计算量提升很多。
GoogLenet
GoogLenet就是由上面的这种Inception module一点点构建出来的,从GoogLenet我们可以看出,构建体征提取的基本单元其实是非常重要的,单纯用单个卷积核进行卷积,然后一味增加网络深度是不可取的。
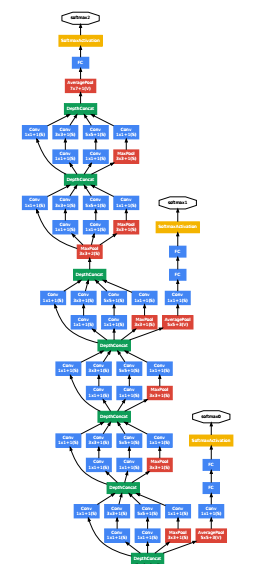
GoogLenet的训练过程也是很有特点的,我们可以看出GoogLenet的
网络其实也是非常深的,如果梯度从最后一层传递到第一层,梯度基本已经没有了,所以GoogLenet在网络的中间加了softmax层,通过这些层获取额外的训练loss,然后根据这个loss计算对应的梯度,最后把梯度加到整个网络的梯度中,进行梯度传播,这样可以有效缓解梯度消失的问题。
其实这种训练方式可以看作将几个不同深度的子网络合并到一块进行训练,由于网络的卷积核共享,因此计算的梯度也可以累加,这样最终的梯度也不会很小。关于这一点做的最彻底的应该就是ResNet
关于ResNet的结构和特点将在另一篇文章里总结。
疑问
关于GoogLenet没有看懂的一点就是,Inception module和网络的稀疏化有什么关联吗,论文中提及Inception module是有稀疏化的考虑的,但是我完全没有明白从什么角度考虑的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









