









欠拟合,正常,过拟合图:
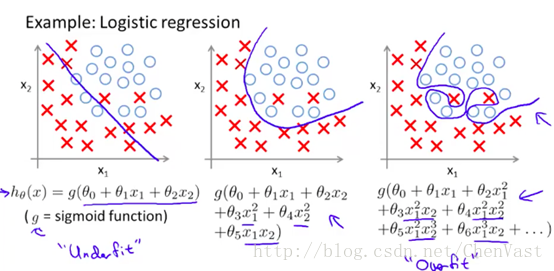
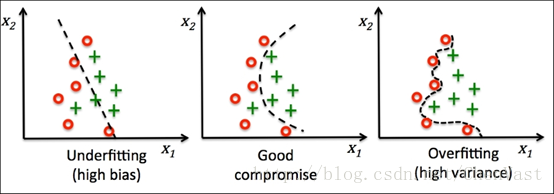
偏差 - 方差权衡就是通过正则化调整模型的复杂度
正则化是解决共线性的一个很有用的方法,可以过滤数据中的噪声,并最终防止过拟合。
正则化背后的概念是引入额外的信息(偏差)来对极端数据参数权重做出惩罚。
最常用的正则化为L2正则化也称为L2收缩或者权重衰减。
L2公式:
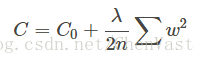
正则化的使用方法:在逻辑斯蒂回归的代价函数中加入正则化项,降低回归系数带来的副作用。
建议使用jupyter notebook运行程序:
数据集和库文件定义在该章节有定义了,链接:http://mp.blog.csdn.net/postedit/79196206
#绘制对两个权重系数进行L2正则化后的图像:
# 正则化路径:
def Regularization():
weights, params = [], []
for c in np.arange (-5, 5,dtype = float):
lr = LogisticRegression (C=10 ** c, random_state=0)
lr.fit (X_train_std, y_train)
weights.append (lr.coef_[1])
params.append (10 ** c)
weights = np.array (weights)
plt.plot (params, weights[:, 0],
label='花瓣长度')
plt.plot (params, weights[:, 1], linestyle='--',
label='花瓣宽度')
plt.ylabel ('权重系数')
plt.xlabel ('C')
plt.legend (loc='upper left')
plt.xscale ('log')
# plt.savefig('./figures/regression_path.png', dpi=300)
plt.show ()
# Regularization()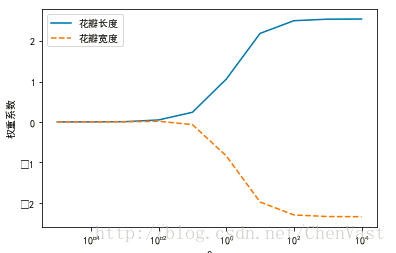














 1928
1928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









