







在自然语言处理中,最常见的两个问题分别是,将文本按主题归类和将词汇按意思归类。这两个问题都可以通过矩阵运算来圆满地,一次次能够解决。首先来看一看余弦定理和新闻分类这个问题
新闻分类其实就是一个聚类问题,关键是计算两篇新闻的相似程度。问了完成这个任务,我们可以将新闻表示成代表它们内容的实词序列,即向量,然后求两个向量的夹角。夹角越小,表示两篇新闻越相关;当它们垂直正交时,表示两篇新闻无关。从理论上来讲,这种算法非常简单,,也易于实现。但问题是,当我们需要对大量的新闻进行分类时,我们需要两两比较,这需要很多次迭代,因此非常耗时。尤其当新闻数量非常大,同时词汇数量也很大时,这个问题可能会趋于无解。那么我们有没有一种方法,能够一次性地把所有新闻的相关性计算出来呢?答案是肯定的,这就是我们在“线性代数”中学过的SVD(奇异值分解)。
现在让我们来看看奇异值分解是怎么回事。首先,我们可以用一个大矩阵A来描述这一百万篇文章和五十万词的关联性。这个矩阵中,每一行对应一篇文章,每一列对应一个词。
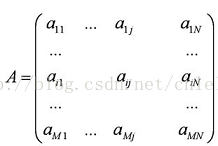
奇异值分解就是把上面这样一个大矩阵,分解成三个小矩阵相乘,如下图所示。比如把上面的例子中的矩阵分解成一个一百万乘以一百的矩阵X,一个一百乘以一百的矩阵B,和一个一百乘以五十万的矩阵Y。这三个矩阵的元素总数加起来也不过1.5亿,仅仅是原来的三千分之一。相应的存储量和计算量都会小三个数量级以上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5351
5351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









