









《机器学习实战》笔记
k-邻近算法工作原理:
已存在一定的样本数据集合,并且集合中的每一组数据都存在数据标签。这样我们输入没有标签的新数据后,将新数据的每个特征与样本数据集合中的每组数据进行对应的特征比较,然后算法提取样本集合中最相似的标签。
一般我们选择样本数据集合中前k个最相似的数据
最后,我们在这前k个最相似的数据中选择出现次数最多的数据标签
上述工作相当于一个分类器
特征1 特征2 特征3 类型 0.9 0.7 8.9 B 3.9 0.6 8.2 A 0.5 1.5 4.5 A 0.7 0.2 6.7 B 0.8 0.3 2.9 ? 假定 类型只有A B两种类型,我们可以通过前四组数据 和 最后一组数据的特征相似比较,选择前k个最相似的数据,从而推断最后一组数据的类型。数据相似比较:
使用的方法主要是两点间距离公式:
如果数据集存在4个特征值时,则点(1,0,0,1)与(7,6,9,4)之间的距离计算为:
两个数据的特征值距离d越短,这两个数据就越相似。而我们要取得就是前k个与测试数据最相似的数据。
特征数值归一化:
当计算 样本A(1,20,2) 和样本B(2,80,4) 之间的距离时, 我们发现第二个特征的值对距离d的影响比较大,这样对其他特征来讲是不公平,于是我们需要对特征的数值进行归一化,防止某些属性的权重过大。 归一化方法: newValue = (oldValue - min)/(max - min) 其中 max为数据集合 某一特征A 的值出现过的最大值 min为数据集合 某一特征A 的值出现过的最小值 oldValue为数据集合中的某一数据的特征A的值 而newValue为数据集合中的某一数据的特征A的归一化后的值。 这样一来 样本A(1,20,2) 和样本B(2,80,4) 归一化的值为 A(0,0,0) B(1,1,1) 各个特征的值对距离d的影响就平等了 数据样本进行归一化后,测试数据也得进行归一化。所以我们得把(max-min)和 min 的值保留下来,用于对测试数据归一化。准备数据:可从文件中读取数据
方法:读取文件,解析字符串,建立数据矩阵。
例如上述AB可构成的数据样本矩阵为:
0 0 0 1 1 1也可以看成一个数组。
算法测试:
可选取数据样本中的数据进行算法测试,因为我们已经知道数据的标签
可选取新的数据,进行新数据的标签输出。但要注意的是,用k邻近算法时,新数据也要进行归一化。
问题:
- 为什么不直接选择k=1,这样看起来更直接准确点?(答:为避免过度拟合,预测过于绝对。)
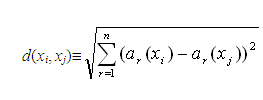
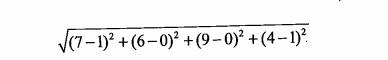
相关项目:
- 约会网站的配对:地址















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









