







用模型在测试集上进行性能评估前,通常是希望尽可能利用手头现有的数据对模型进行调优,甚至可以粗略地估计测试结果。通常,对现有数据进行采样分割:一部分数据用于模型参数训练,即训练集;一部分数据用于调优模型配置和特征选择,且对未知的测试性能做出估计,即验证集。
交叉验证可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现的更加可信。下图给出了十折交叉验证的示意图。
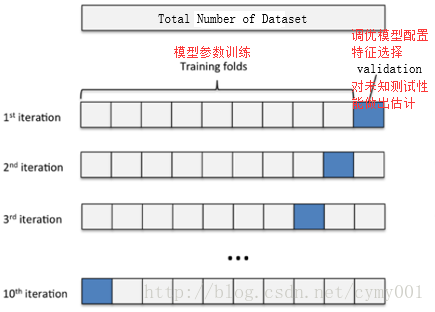
模型的超参数是指实验时模型的配置,通过网格搜索的方法对超参数组合进行调优,该过程并行计算。由于超参数的空间是无尽的,因此超参数的组合配置只能是“更优”解,没有最优解。通常,依靠网格搜索对多种超参数组合的空间进行暴力搜索。每一套超参数组合被代入到学习函数中作为新的模型,为了比较新模型之间的性能,每个模型都会采用交叉验证的方法在多组相同的训练和测试数据集下进行评估。
from sklearn.model_selection import GridSearchCV
from sklearn import svm
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
svc=svm.SVC()
param_grid = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
grid_search = GridSearchCV(svc, param_grid=param_grid, verbose=10)
grid_search.fit(X, y)
print(grid_search.best_estimator_)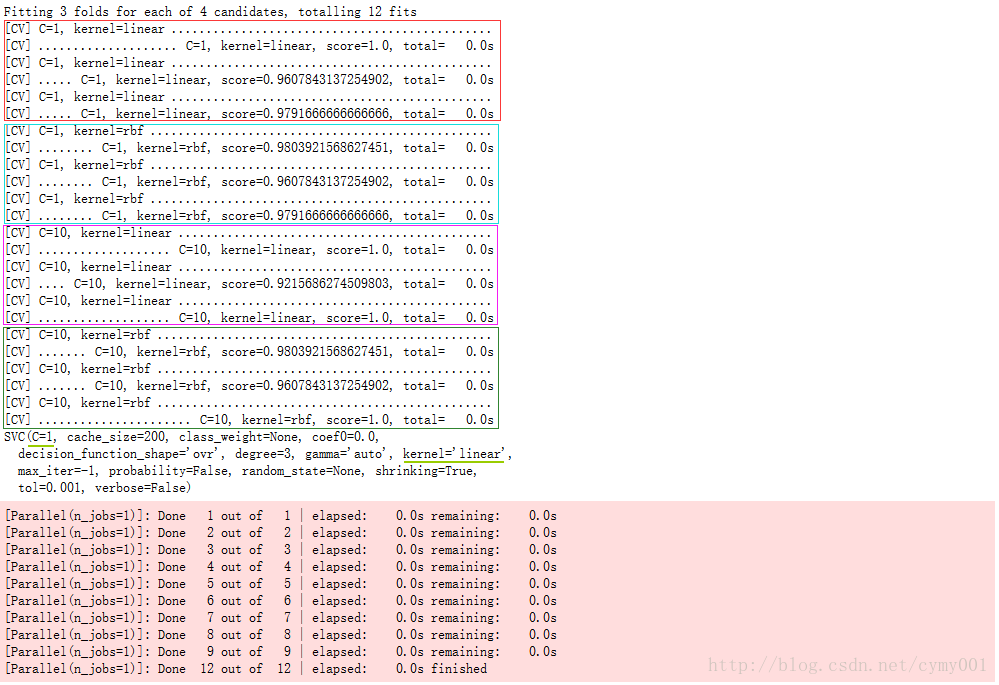
from __future__ import print_function
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
categories = ['alt.atheism','talk.religion.misc']
data = fetch_20newsgroups(subset='train', categories=categories)
print("Loading 20 newsgroups dataset for categories:",categories)
print("%d documents,%d categories" % (len(data.filenames),len(data.target_names)))
# Define a pipeline combining a text feature extractor with a simple classifier
pipeline = Pipeline([('vect', CountVectorizer()),('tfidf', TfidfTransformer()),('clf', SGDClassifier())])
parameters = {
#'vect__max_df': (0.5, 0.75, 1.0),
#'vect__max_features': (None, 5000, 10000, 50000),
'vect__ngram_range': ((1, 1), (1, 2)), # unigrams or bigrams
#'tfidf__use_idf': (True, False),
#'tfidf__norm': ('l1', 'l2'),
#'clf__alpha': (0.00001, 0.000001),
'clf__penalty': ('l2', 'elasticnet'),
#'clf__n_iter': (10, 50, 80),
}
# find the best parameters for both the feature extraction and the classifier
grid_search = GridSearchCV(pipeline, parameters,n_jobs=-1, verbose=10) #用全部CPU并行计算
grid_search.fit(data.data, data.target)
print("Best score: %0.3f" % grid_search.best_score_)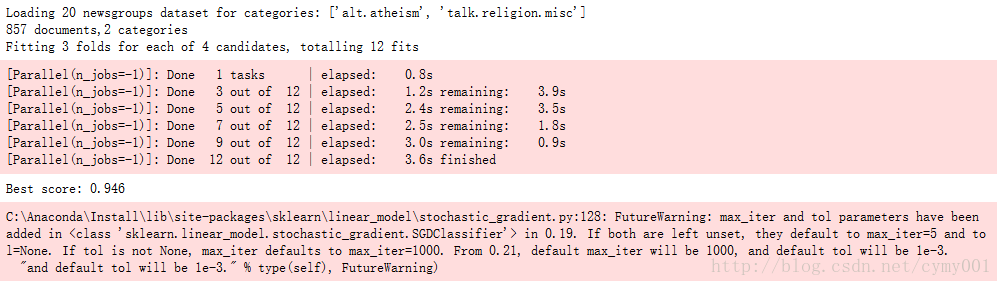














 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









