







本文是周志华《机器学习》第二章的学习笔记。
| 衡量指标 |
错误率error_rate=分类错误的样本数/样本总数;精度accuracy=1-错误率。
训练误差:学习器在训练集上的误差;泛化误差:学习器在新样本上的误差。
过拟合:把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,模型的泛化性能下降;欠拟合:对训练样本的一般性质尚未学好。
| 模型训练(train/validation/test划分;调参) |
在现实任务中往往有多种学习算法可供选择,甚至对同一学习算法使用不同的参数配置时,也会产生不同的模型。“模型选择”方案是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。在实验测试过程中,利用“测试集”来测试学习器对新样本的判别能力,即用测试集上的“测试误差”作为泛化误差的近似。测试样本尽量不在训练集中出现、未在训练过程中使用过。
| 留出法:Data==>留一部分作test |
train/test的划分要尽可能保存数据分布的一致性,在分类任务中至少要保持样本的类别比例相似,即“分层采样(stratified sampling)”。单次使用留出法得到的估计结果不够稳定可靠,一般进行若干次随机划分、重复进行实验评估后,取平均。(通常,将大约2/3~4/5的样本用于训练,剩余样本用于测试)
| 交叉验证法:Data==> D 1 , D 2 , ⋯   , D k ( D i 与 D j 互 斥 ) D_1,D_2,\cdots,D_k(D_i与D_j互斥) D1,D2,⋯,Dk(Di与Dj互斥) |
(1)Data的每个子集 D i D_i Di要尽可能保持数据分布的一致性,即从Data里“分层采样”得到。(2)每次用 k − 1 k-1 k−1个子集的并集作为train集,余下的那个子集作为test集,从而得 k k k组train/test集,即进行 k k k次训练和测试,最终返回的是这 k k k个测试结果的均值,即“ k k k折交叉验证”。(3)将数据集Data划分为 k k k个子集时,存在多种划分方式,为减小因样本划分不同引入的误差,通常,“ k k k折交叉验证”要随机试验不同的划分重复 P P P次,最终的评估结果是这 P P P次“ k k k折交叉验证”结果的均值。
| 自助法:对Data进行有放回采样得数据集Data1 |
样本在
m
m
m次采样中始终不被采到的概率
lim
m
→
∞
(
1
−
1
m
)
m
=
1
e
≈
0.368
\lim\limits_{m\to\infty}(1-\frac{1}{m})^m=\frac{1}{e}\approx0.368
m→∞lim(1−m1)m=e1≈0.368
即原始数据集Data里约有36.8%的样本未出现在采样数据集Data1里,即将Data1作为train集,将Data\Data1作为test集。此外,自助法可从初始数据集中产生多个不同的train集,对集成学习等方法有很大的好处;但该方法产生的train集改变了初始数据的分布,会引入估计偏差。
自助法适用于数据集较小,难以划分train\test集。当初始Data量足够时,交叉验证法更常用一些。
机器学习常涉及两类参数:(1)算法的参数,即“超参数”(数目常在10以内)(2)模型的参数(数目可能很多)。前者通常是由人工设定多个参数候选值后产生模型[SGD algorithm],后者通过学习来产生多个候选模型[LR里的多维参数 θ \theta θ]。
Data==>train/validation/test
train/validation==>get final model
| 性能度量:衡量模型泛化能力的评价标准 |
| 回归问题的性能度量 |
MSE(mean squared error):
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2
E(f;D)=m1i=1∑m(f(xi)−yi)2
若数据分布是
F
F
F,数据的概率密度函数是
p
(
x
)
p(x)
p(x)
E
(
f
;
D
)
=
∫
x
∼
F
(
f
(
x
)
−
y
)
2
p
(
x
)
d
x
E(f;D)=\int_{x\sim F}(f(x)-y)^2 p(x)dx
E(f;D)=∫x∼F(f(x)−y)2p(x)dx
| 分类问题的性能度量 |
(1)错误率v.s.精度
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
I
(
f
(
x
i
)
≠
y
i
)
E(f;D)=\frac{1}{m}\sum_{i=1}^{m}I(f(x_i)\neq y_i)
E(f;D)=m1i=1∑mI(f(xi)̸=yi)
a
c
c
(
f
;
D
)
=
1
m
∑
i
=
1
m
I
(
f
(
x
i
)
=
y
i
)
=
1
−
E
(
f
;
D
)
acc(f;D)=\frac{1}{m}\sum_{i=1}^{m}I(f(x_i)=y_i)=1-E(f;D)
acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
若数据分布是
F
F
F,数据的概率密度函数是
p
(
x
)
p(x)
p(x)
E
(
f
;
D
)
=
∫
x
∼
F
I
(
f
(
x
)
≠
y
)
p
(
x
)
d
x
E(f;D)=\int_{x\sim F}I(f(x)\neq y) p(x)dx
E(f;D)=∫x∼FI(f(x)̸=y)p(x)dx
a
c
c
(
f
;
D
)
=
∫
x
∼
F
I
(
f
(
x
)
=
y
)
p
(
x
)
d
x
=
1
−
E
(
f
;
D
)
acc(f;D)=\int_{x\sim F}I(f(x)=y) p(x)dx=1-E(f;D)
acc(f;D)=∫x∼FI(f(x)=y)p(x)dx=1−E(f;D)
(2)Precision/Recall/F1——>P-R曲线
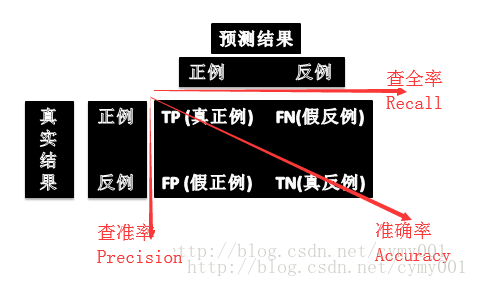
对于二分类问题,可将样例根据“真实类别”和“学习器预测类别”的组合划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)和假反例(false negative,FN)四种情形,即得如下“混淆矩阵”
Precision和Recall是一对矛盾的度量,一般,Precision高时,Recall往往偏低;而Recall高时,Precision往往偏低。通常只有一些简单任务中,才可能使Precision和Recall都很高。
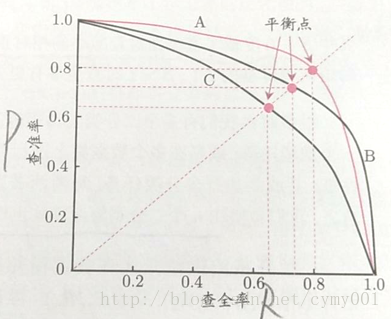
P-R曲线
原理及绘制方法:
P-R曲线:Precision-Recall曲线,横轴是Recall,纵轴是Precision。
【A】根据学习器的预测结果对样例进行排序:排最前面(max probability正例样本),排最后面(min probability正例样本)。
【B】将阈值
δ
k
\delta_k
δk从大到小变化(1——>0),对上述排序的样例进行预测,当学习器对样例
i
i
i的预测概率
P
i
>
δ
k
P_i>\delta_k
Pi>δk时,将该样例预测为正例;当学习器对样例
i
i
i的预测概率
P
i
<
δ
k
P_i<\delta_k
Pi<δk时,将该样例预测为负例。
【C】针对每个阈值
δ
k
\delta_k
δk,对全部样例进行正负分类之后,可得混淆矩阵,从而可计算Precision和Recall,即得P-R曲线。
分析标准:
【a】若一个学习器的P-R曲线©被另一个学习器的P-R曲线(A)完全“包住”,则可断言曲线(A)对应的学习器性能优于曲线©对应的学习器。
【b】当两个学习器的P-R曲线相交时,则要根据
P
−
R
曲
线
与
x
,
y
轴
围
成
的
封
闭
区
域
面
积
P-R曲线与x,y轴围成的封闭区域面积
P−R曲线与x,y轴围成的封闭区域面积大小决定,或者根据
平
衡
点
(
B
E
P
,
b
r
e
a
k
−
e
v
e
n
p
o
i
n
t
,
P
r
e
c
i
s
i
o
n
=
R
e
c
a
l
l
)
平衡点(BEP,break-even point,Precision=Recall)
平衡点(BEP,break−evenpoint,Precision=Recall)的取值大小决定。
【c】BEP标准过于简化,常用的是
F
1
度
量
F1度量
F1度量及其改进版本
F
β
F_\beta
Fβ
F
β
=
(
1
+
β
2
)
×
P
×
R
(
β
2
×
P
)
+
R
F_{\beta}=\frac{(1+\beta^2)\times P\times R}{(\beta^2\times P)+R}
Fβ=(β2×P)+R(1+β2)×P×R
β
>
0
\beta>0
β>0,度量Recall对Precision的相对重要性。
β
=
1
\beta=1
β=1退化为标准的
F
1
度
量
F1度量
F1度量,
β
>
1
\beta>1
β>1Recall有更大影响,
β
<
1
\beta<1
β<1时Precision有更大影响。
【d】对于多分类,有两种性能度量策略:
[d.1]先对两两分类计算混淆矩阵,在各混淆矩阵上分别计算出Precision和Recall,再计算平均值——
“
m
a
c
r
o
_
P
,
m
a
c
r
o
_
R
,
m
a
c
r
o
_
F
1
”
“macro\_P,macro\_R,macro\_F1”
“macro_P,macro_R,macro_F1”
m
a
c
r
o
_
P
=
1
n
∑
i
=
1
n
P
i
macro\_P=\frac{1}{n}\sum_{i=1}^{n}P_{i}
macro_P=n1i=1∑nPi
m
a
c
r
o
_
R
=
1
n
∑
i
=
1
n
R
i
macro\_R=\frac{1}{n}\sum_{i=1}^{n}R_{i}
macro_R=n1i=1∑nRi
m
a
c
r
o
_
F
1
=
2
×
m
a
c
r
o
_
P
×
m
a
c
r
o
_
R
m
a
c
r
o
_
P
+
m
a
c
r
o
_
R
macro\_F1=\frac{2\times macro\_P\times macro\_R}{macro\_P+macro\_R}
macro_F1=macro_P+macro_R2×macro_P×macro_R
[d.2]先对两两分类计算混淆矩阵,再将各混淆矩阵的4个对应元素
T
P
,
F
P
,
T
N
,
F
N
TP,FP,TN,FN
TP,FP,TN,FN分别计算均值,得
T
P
‾
,
F
P
‾
,
T
N
‾
,
F
N
‾
\overline{TP},\overline{FP},\overline{TN},\overline{FN}
TP,FP,TN,FN,再基于这些均值计算——
“
m
i
c
r
o
_
P
,
m
i
c
r
o
_
R
,
m
i
c
r
o
_
F
1
”
“micro\_P,micro\_R,micro\_F1”
“micro_P,micro_R,micro_F1”
m
i
c
r
o
_
P
=
T
P
‾
T
P
‾
+
F
P
‾
micro\_P=\frac{\overline{TP}}{\overline{TP}+\overline{FP}}
micro_P=TP+FPTP
m
i
c
r
o
_
R
=
T
P
‾
T
P
‾
+
F
N
‾
micro\_R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}
micro_R=TP+FNTP
m
i
c
r
o
_
F
1
=
2
×
m
i
c
r
o
_
P
×
m
i
c
r
o
_
R
m
i
c
r
o
_
P
+
m
i
c
r
o
_
R
micro\_F1=\frac{2\times micro\_P\times micro\_R}{micro\_P+micro\_R}
micro_F1=micro_P+micro_R2×micro_P×micro_R
(3)ROC/AUC
ROC曲线与AUC
原理及绘制方法:
ROC曲线:Receiver Operating Characteristic曲线,横轴是FPR(False Positive Rate),纵轴是TPR(True Positive Rate)。
T
P
R
=
T
P
T
P
+
F
N
,
F
P
R
=
F
P
T
N
+
F
P
TPR=\frac{TP}{TP+FN},FPR=\frac{FP}{TN+FP}
TPR=TP+FNTP,FPR=TN+FPFP
AUC(Area Under ROC Curve):ROC曲线下的面积。
针对理想条件下的阈值可连续取值绘制ROC曲线:ROC曲线与P-C曲线类似,首先根据学习器对每个样本的概率预测结果进行排序——排最前面(max probability正例样本),排最后面(min probability正例样本)。将阈值
δ
k
\delta_k
δk从大到小变化(1——>0),对上述排序的样例进行预测,当学习器对样例
i
i
i的预测概率
P
i
>
δ
k
P_i>\delta_k
Pi>δk时,将该样例预测为正例;当学习器对样例
i
i
i的预测概率
P
i
<
δ
k
P_i<\delta_k
Pi<δk时,将该样例预测为负例。针对每个阈值
δ
k
\delta_k
δk,对全部样例进行正负分类之后,可得混淆矩阵,从而可计算该阈值对应的TPR和FPR,即得ROC曲线。
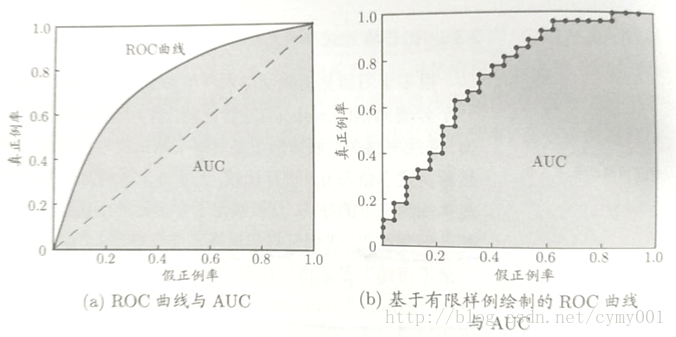
针对有限个测试样例绘制ROC曲线:给定 m + m^+ m+个正例和 m − m^- m−个反例,首先,根据学习器的预测结果对样例排序,把分类阈值设为最大(即把所有样例均预测为反例),此时真正例和假正例都为0,在原点(0,0)标记一个点;然后,将分类阈值依次设为每个样例的预测值,即依次将每个样例划分为正例——设前一个标记点坐标为 ( x , y ) (x,y) (x,y),当前样例若为真正例,则对应标记点的坐标为 ( x , y + 1 m + ) (x,y+\frac{1}{m^+}) (x,y+m+1);当前样例若为假正例,则对应标记点的坐标为 ( x + 1 m − , y ) (x+\frac{1}{m^-},y) (x+m−1,y),最终用线段连接相邻点即可。
分析标准:
若一个学习器的ROC曲线被另一个学习器的ROC曲线完全“包住”,则可断言后者的性能更好;若两个学习器的ROC曲线发生交叉,则需要比较各自学习器的AUC,值大的性能更好
A
U
C
=
1
2
∑
i
=
1
m
−
1
(
x
i
+
1
−
x
i
)
⋅
(
y
i
+
y
i
+
1
)
AUC=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1}-x_{i})\cdot(y_i+y_{i+1})
AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)
(4)代价敏感错误率/代价曲线
考虑现实任务中不同类型的错误所造成的后果不同,为了均衡不同类型错误所造成的不同损失,可以给错误赋予“非均等代价”。在二分类问题中,定义如下“代价矩阵(cost matrix)”
为了最小化“总体代价(total cost)”,通常计算如下“代价敏感(cost-sensitive)”错误率
E
(
f
;
D
;
c
o
s
t
)
=
1
m
(
∑
x
i
∈
D
+
I
(
f
(
x
i
)
≠
y
i
)
×
c
o
s
t
01
+
∑
x
i
∈
D
−
I
(
f
(
x
i
)
≠
y
i
)
×
c
o
s
t
10
)
E(f;D;cost)=\frac{1}{m}\Big(\sum_{x_i\in D^+} I(f(x_i)\neq y_i)\times cost_{01}\\ +\sum_{x_i\in D^-} I(f(x_i)\neq y_i)\times cost_{10}\Big)
E(f;D;cost)=m1(xi∈D+∑I(f(xi)̸=yi)×cost01+xi∈D−∑I(f(xi)̸=yi)×cost10)

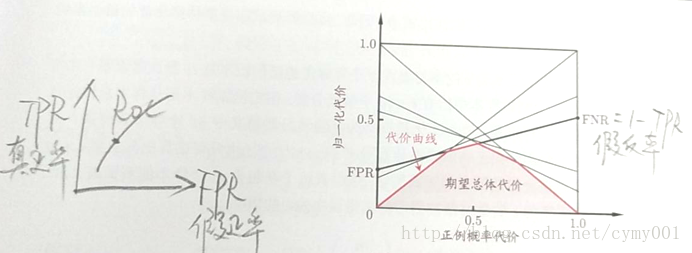
在非均等代价下,ROC曲线无法直接反映出学习器的期望总体代价,需要使用“代价曲线(cost curve)”。
代价曲线(cost curve):横轴是“正例代价概率”,取值[0,1]
P
(
+
)
c
o
s
t
=
p
×
c
o
s
t
01
p
×
c
o
s
t
01
+
(
1
−
p
)
×
c
o
s
t
10
P(+)cost=\frac{p\times cost_{01}}{p\times cost_{01}+(1-p)\times cost_{10}}
P(+)cost=p×cost01+(1−p)×cost10p×cost01
纵轴是归一化代价,取值[0,1]
c
o
s
t
n
o
r
m
=
F
N
R
×
p
×
c
o
s
t
01
+
F
P
R
×
(
1
−
p
)
×
c
o
s
t
10
p
×
c
o
s
t
01
+
(
1
−
p
)
×
c
o
s
t
10
cost_{norm}=\frac{FNR\times p\times cost_{01}+FPR\times(1-p)\times cost_{10}}{p\times cost_{01}+(1-p)\times cost_{10}}
costnorm=p×cost01+(1−p)×cost10FNR×p×cost01+FPR×(1−p)×cost10
其中,
F
P
R
FPR
FPR是假正例率,
F
N
R
=
1
−
T
P
R
FNR=1-TPR
FNR=1−TPR是假反例率。
代价曲线的绘制:将ROC曲线上的每个点转化成代价平面上的一条线段,取所有线段的下界,围成的面积即在所有条件下学习器的期望总体代价。
| 偏差与方差 |
除了通过实验估计学习算法的泛化性能,人们往往还希望对算法表现出的泛化性能进行解释,通常使用的方法是**“偏差-方差分解(bias-variance decomposition)”。
对给定的样例
x
x
x,其真实的标签为
y
y
y,采集到的数据集里的标签为
y
D
y_D
yD,模型预测的标签为
f
(
x
;
D
)
f(x;D)
f(x;D),则学习算法的期望预测**
f
‾
(
x
)
=
E
D
[
f
(
x
;
D
)
]
\overline{f}(x)=E_{D}[f(x;D)]
f(x)=ED[f(x;D)]
使用样本数相同的不同训练集产生的方差(variance)
v
a
r
(
x
)
=
E
D
[
(
f
(
x
;
D
)
−
f
‾
(
x
)
)
2
]
var(x)=E_{D}[(f(x;D)-\overline{f}(x))^2]
var(x)=ED[(f(x;D)−f(x))2]
噪声
ε
2
=
E
D
[
(
y
D
−
y
)
2
]
\varepsilon^2=E_{D}[(y_D -y)^2]
ε2=ED[(yD−y)2]
期望输出与真实标记的差别,即偏差(bias)
b
i
a
s
2
(
x
)
=
(
f
‾
(
x
)
−
y
)
2
bias^2(x)=(\overline{f}(x)-y)^2
bias2(x)=(f(x)−y)2
在假定期望噪声
E
D
[
y
D
−
y
]
=
0
E_D[y_D-y]=0
ED[yD−y]=0的情况下,可得如下偏差-方差分解
E
(
f
;
D
)
=
E
D
[
(
f
(
x
;
D
)
−
y
D
)
2
]
=
E
D
[
(
f
(
x
;
D
)
−
f
‾
(
x
)
)
2
]
+
(
f
‾
(
x
)
−
y
)
2
+
E
D
[
(
y
D
−
y
)
2
]
=
b
i
a
s
2
(
x
)
+
v
a
r
(
x
)
+
ε
2
E(f;D)=E_D[(f(x;D)-y_D)^2]\\ =E_{D}[(f(x;D)-\overline{f}(x))^2]+(\overline{f}(x)-y)^2+E_{D}[(y_D -y)^2]\\ =bias^2(x)+var(x)+\varepsilon^2
E(f;D)=ED[(f(x;D)−yD)2]=ED[(f(x;D)−f(x))2]+(f(x)−y)2+ED[(yD−y)2]=bias2(x)+var(x)+ε2
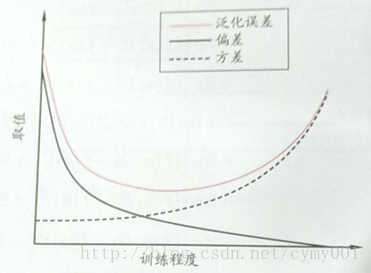
偏差表示学习算法的期望预测与真是结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差表示同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声表示在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差-方差窘境(bias-variance dilemma):在训练模型时,可以控制学习算法的训练程度。训练刚开始时,(a)由于训练不足,学习器的拟合能力不够强,训练数据的扰动不足以是学习器产生显著变化,此时偏差主导了泛化错误率;随着训练长度的加深,(b)学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐会被学习器学到,方差逐渐住到了泛化错误率。















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









