







HCLG.fst由四部分构成
1. G:语言模型WFST,输入输出符号相同,实际是一个WFSA(acceptor接受机),为了方便与其它三个WFST进行操作,将其视为一个输入输出相同的WFST。
2. L:发音词典WFST,输入符号:monophone,输出符号:词;
3. C:上下文相关WFST,输入符号:triphone(上下文相关),输出符号:monophnoe;
4. H:HMM声学模型WFST,输入符号:HMMtransitions-ids,输出符号:triphone。
将四者逐层合并,即可得到最后的图。
HCLG= asl(min(rds(det(H'omin(det(Co min(det(Lo G)))))))
其中asl==“add-self-loops”和rds==“remove-disambiguation-symbols“,H'为没有自环的H。
一、G.fst用于对语言模型进行编码。当使用统计语言模型时,用srilm训练出来的语言模型为arpa格式,可以用arpa2fst将arpa转换成fst,详见kaldi中的utils/format_lm.sh。
举个栗子:
假设语言模型由data.txt内的数据训练得到,$cat data.txt
今天天气怎么样
今天北京的天气怎么样
明天天气怎么样
分词后,$cat data.split
今天 天气 怎么 样
今天 北京 的 天气 怎么 样
明天 天气 怎么 样
训练语言模型
$ngram-count -text data.split -order 3 -lm query.arpa
$cat query.arpa\data\
ngram1=9
ngram2=10
ngram3=2
\1-grams:
-0.7533277 </s>
-99 <s> -0.7907404
-0.9294189今天-1.059586
-1.230449北京-0.6268836
-0.7533277天气-0.5177391
-0.7533277怎么-0.5177391
-1.230449明天-0.5688916
-0.7533277样-0.5177391
-1.230449的-0.5688916
\2-grams:
-0.39794 <s>今天
-0.3309932 <s>明天
-0.3309932今天 北京
-0.3309932今天 天气
-0.1091445北京 的
-0.1249387天气 怎么0
-0.1249387怎么 样0
-0.1091445明天 天气
-0.1249387样</s>
-0.1091445的 天气
\3-grams:
-0.1249387天气 怎么 样
-0.1249387怎么 样</s>
\end\
同时还需要给每一个词赋予一个唯一的id(symboltable)
$cat data.split | tr ' ' '\n' | grep -v ^$ | sort -u |awk '{print $1""NR }END{print "<eps>"" "0;print "#0"""NR+1;print "<s>"" "NR+2;print "</s>"""NR+3 }' > words.txt
$cat words.txt今天 1
北京 2
天气 3
怎么 4
明天 5
样 6
的 7
<eps> 0
#0 8
<s> 9
</s> 10
这样做的原因是:Kaldi运行时不会使用文本形式,而是用整数标号形式来表达和传递信息。
word.txt文件包含单个消歧符号“#0”(用于G.fst输入上的epsilon)。在语言模型G中的退避弧上有一个符号#0;
这确保了G在删除epsilons之后是可确定的。
然后即可用arpa2fst将arpa格式语言模型转换为fst
arpa2fst--disambig-symbol=#0 --max-arpa-warnings=-1--read-symbol-table=words.txt query.arpa G.fst在实际应用中,需要有剔除不可用/包含集外词的N元语法等的操作,详见local/wsj_format_data.sh
至此,G.fst已经构好,想看构好的图长什么样,可以用fstdraw与dot
$fstdraw --isymbols=words.txt --osymbols=words.txt G.fst > fst.dot通常dot转换为jpg后分辨率会过低且不支持显示中文,因此打开fst.dot文件,将其中的size大小扩大,
并将编码格式转换为utf-8,在每个fontsize前加上fontname="simsun.ttc",
vim中:%s:fontsize= 14:fontname="simsun.ttc",fontsize = 20:g
$dot -Tjpg fst.dot > fst.jpg
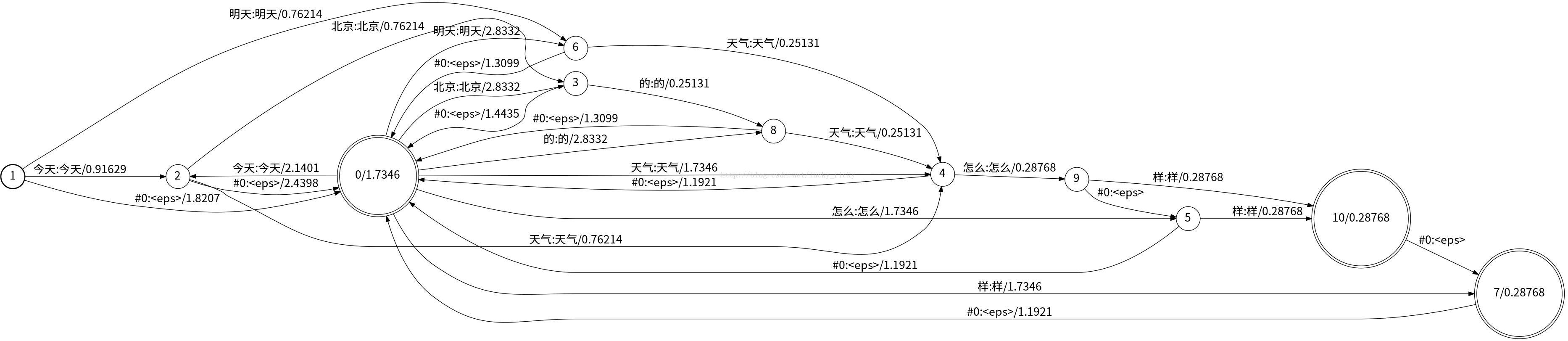
这部分最后一条命令是fstisstochastic,这是一个诊断步骤,他打印出两个数字,最小权重和最大权重,以告诉用户FST不随机的程度。
eg:9.14233e-05 -0.259833
第一个数字很小,它证实没有状态的弧的概率加上最终状态明显小于1。第二个数字是重要的,这意味着有些状态具有“太多”的概率。对于具有回退的语言模型的FST来说,有一些具有“太多”概率的状态是正常的。
(thenumeric values of the weights in the FSTs can generally be interpreted as negated log probabilities)FST中权重的数值通常可以解释为负对数概率。
二、L.fst是一个把音素映射成为词的发音词典FST,L.fst位于data/lang目录(language,与“语言”本身相关),在该目录下有如下内容:
L.fst L_disambig.fst oov.int oov.txt phones phones.txt topo words.txt
L.fst是FST形式的发音词典,对每个词的发音进行编码,输入是音素,输出是词。
L_disambig.fst也是FST形式的发音词典,不过它还包含为了消歧而引入的消歧符号(如#1、#2)和为自环(self-loop)而引入的#0。#0是来自G.fst的特殊消歧符号,它的作用是让消歧符号能够“通过”(passthrough)整个语言模型。
oov.txt中仅有一个元素:<UNK>,其作用是将所有词汇表以外的词都映射为这个词,这使得这个词的发音只包含一个被指定为“垃圾音素”(garbagephone)的音素。该音素被称为<SPN>,就是“spokennoise”的缩写,该音素会与各种口语噪声对齐。
#grep -w UNK data/local/dict/lexicon.txt<UNK>SPN
oov.int中有<UNK>所对应的id。
phones.txt和words.txt为符号表(symboltable)文件,第一列为文本,第二列为数字。这两个文件用于将每个元素对应到唯一的id上。
topo指明了所用的HMM模型的拓扑结构//待补充
phones文件夹下有一系列文件,指明音素集合的各种信息,这些文件大多数包含三个不同版本:txt、int、csl。详见http://www.kaldi-asr.org/doc/data_prep.html
以上这些文件都不需要手动创建,kaldi提供了一个脚本utils/prepare_lang.sh可以用于创建这个目录中的多数文件:
utils/prepare_lang.shdata/local/dict "<UNK>" data/local/lang data/lang。
脚本utils/prepare_lang.sh支持很多选项。
--position-dependent-phones(true|false)。默认ture;用于决定是否将phone更详细地拆分为开始、
中间、结束、孤立灯给未知相关的phones。如果允许,则在每个phone后面加上_B_I _E _S用于标定位置[(B)egin,(E)nd, (I)nternal and (S)ingleton]。在构建决策树时可以对phone的位置进行提问,然后产生分裂。
-share-silence-phones(true|false)。该选项默认是false。如果该选项被设为true,所有静音音素(如静音、发声噪声、噪声和笑声)会共享同一个pdf(高斯混合模型),只有模型中的转移概率不同。这对IARPA的BABEL项目中的广东话数据集非常有效。它会构造一个roots文件,在文件中同一行出现的所有音素对应的HMM会共享他们的混合高斯分布。如果不想共享,可以把他们放在不同行。roots文件中,每一行前面都会有shared/not-shared和split/not-split修饰。
--sil-prob <probability of silence> # default: 0.5 [must have0 < silprob < 1]也可能很重要,只是具体该设置成多少需要更多的实验。
输入目录是data/local/dict/,<UNK>需要在字典中,是标注中所有OOV词的映射词(映射情况会写入data/lang/oov.txt中)。data/local/lang/只是脚本使用的一个临时目录,data/lang/才是输出文件将会写入的地方。
我们需要做的是准备好data/local/dict/。该目录下需包含以下文件:
extra_questions.txt lexicon.txt[lexiconp.txt] nonsilence_phones.txt optional_silence.txt silence_phones.txt
nonsilence_phones.txt内容为“真正”的音素,kaldi建议将每个basephone的不同形式都组织在单独的一行中。他们可以有不用的重音或者声调,例如aa1 a2 a3 a4
silence_phones.txt内容为“静音”音素,包含各种噪声、笑声、咳嗽、填充停顿等(SIL SPN NSN LAU)
extra_questions.txt有可能是空的;但通常会包含多行音素,每行的音素成员都有相同的声调,有的行可能是静音音素。这样做可以增强自动产生问题。在nonsilence_phones.txt中每个音素的不同声调表示都在同一行,这确保了他们在data/lang/phones/roots.txt和data/lang/phones/sets.txt也属同一行,这反过来又确保了它们共享同一个(决策)树根,并且不会有决策问题弄混它们。因此,我们需要提供一个特别的问题,能为决策树的建立过程提供一种区分音素的方法。注意:我们在sets.txt和roots.txt中将音素分组放在一起的原因是,这些同一音素的不同声调变体可能缺乏足够的数据去稳健地估计一个单独的决策树,或者是产生问题集时需要的聚类信息。像这样把它们组合在一起,我们可以确保当数据不足以对它们分别估计决策树时,这些变体能在决策树的建立过程中“聚集在一起”(staytogether)。
optional_silence.txt只包含一个音素来作为字典中的选择静音音素,通常是SIL。
lexicon.txt每个词的发音,格式为:<词><phone1> <phone2> …
注意: lexicon.txt中,如果一个词有不同发音,则会在不同行中出现多次。
在这些输入中,没有词位信息,即没有像_B和_E这样的后缀。
脚本prepare_lang.sh会帮我们添加这些后缀。
lexiconp.txt带概率的发音词典,格式为:<词><pron-prob><phone1> <phone2> …
注: 0.0<pron-prob<=1.0
如果存在lexiconp.txt,则优先使用lexiconp.txt而不用lexicon.txt
消歧符号是在词典中的音素序列末尾插入的符号#1,#2,#3等。当音素序列是词典中另一个音素序列的前缀,或者出现在一个以上的单词中时,需要在其后加上这些符号之一。需要这些符号以确保产品Lo G是可确定的。
可以使用脚本utils/make_lexicon_fst.pl将词典转换成fst输入文件的格式。
Usage:make_lexicon_fst.pl [--pron-probs] lexicon.txt [silprob silphone[sil_disambig_sym]] >lexiconfst.txt
使用fstcompile可以将text描述性的fst转换为二进制形式:
fstcompile–isymbols=phones.txt --osymbols=words.txt text_format.fstbinary.fst
为了之后要做的compose操作,这里还需要fstaddselfloops和fstarcsort。
生成的二进制fst可以使用fstdraw可视化,命令为:
fstdraw--isymbol=phones.txt –osymbol=words.txt binary.fst |dot -Tjpg >fst.jpg
三、有了G和L,我们就可以计算min(det(Lo G)),命令行如下:
fsttablecomposedata/L_disambig.fst data/G.fst | \
fstdeterminizestar--use-log=true | \
fstminimizeencoded| fstpushspecial | \
fstarcsort--sort-type=ilabel > somedir/LG.fst
四、上下文相关FST:triphone到monophone的转换器,加入他可以避免枚举所有可能的monophone
我们还有一个消歧符号#-1代替出现在上下文FSTC的左边的epsilons,在开始的话语(在我们开始输出符号之前)。这是必要的,以解决一个相当微妙的问题,当我们有一个空的语音表示的话(例如句子符号的开始和结束<s>和</s>)。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









