









此部分内容参考了三人的博客,写的东西有相同之处和不同之处,互相补充吧.
1. 转载链接:http://blog.csdn.net/chenriwei2/article/details/46367023
主要功能:
Blob 是Caffe作为数据传输的媒介,无论是网络权重参数,还是输入数据,都是转化为Blob数据结构来存储,网络,求解器等都是直接与此结构打交道的。
其直观的可以把它看成一个有4纬的结构体(包含数据和梯度),而实际上,它们只是一维的指针而已,其4维结构通过shape属性得以计算出来(根据C语言的数据顺序)。
其成员变量有:
protected:
shared_ptr<SyncedMemory> data_;// 存放数据
shared_ptr<SyncedMemory> diff_;//存放梯度
vector<int> shape_; //存放形状
int count_; //数据个数
int capacity_; //数据容量成员函数,见的最多的有:
const Dtype* cpu_data() const; //cpu使用的数据
void set_cpu_data(Dtype* data);//用数据块的值来blob里面的data。
const Dtype* gpu_data() const;//返回不可更改的指针,下同
const Dtype* cpu_diff() const;
const Dtype* gpu_diff() const;
Dtype* mutable_cpu_data();//返回可更改的指针,下同
Dtype* mutable_gpu_data();
Dtype* mutable_cpu_diff();
Dtype* mutable_gpu_diff();总之,带mutable_开头的意味着可以对返回的指针内容进行更改,而不带mutable_开头的返回const 指针,不能对其指针的内容进行修改,
int offset(const int n, const int c = 0, const int h = 0,const int w = 0) const
// 通过n,c,h,w 4个参数来计算一维向量的偏移量。
Dtype data_at(const int n, const int c, const int h,const int w) const//通过n,c,h,w 4个参数来来获取该向量位置上的值。
Dtype diff_at(const int n, const int c, const int h,const int w) const//同上
inline const shared_ptr<SyncedMemory>& data() const {
CHECK(data_);
return data_;//返回数据,不能修改
}
inline const shared_ptr<SyncedMemory>& diff() const {
CHECK(diff_);
return diff_;//返回梯度,不能修改
}
Reshape(...)//reshape 有多种多态的实现,可以是四个数字,长度为四的vector,其它blob等。
if (count_ > capacity_) {
capacity_ = count_;
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
}//当空间不够的时候,需要扩大容量,reset。
源代码:
#ifndef CAFFE_BLOB_HPP_
#define CAFFE_BLOB_HPP_
#include <algorithm>
#include <string>
#include <vector>
#include "caffe/common.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/syncedmem.hpp"
#include "caffe/util/math_functions.hpp"
const int kMaxBlobAxes = INT_MAX;
namespace caffe {
/**
* @brief A wrapper around SyncedMemory holders serving as the basic
* computational unit through which Layer%s, Net%s, and Solver%s
* interact.
*
* TODO(dox): more thorough description.
*/
template <typename Dtype>
class Blob {
public:
Blob()
: data_(), diff_(), count_(0), capacity_(0) {}
/// @brief Deprecated; use <code>Blob(const vector<int>& shape)</code>.
explicit Blob(const int num, const int channels, const int height,
const int width);
explicit Blob(const vector<int>& shape);
/// @brief Deprecated; use <code>Reshape(const vector<int>& shape)</code>.
void Reshape(const int num, const int channels, const int height,
const int width);
/**
* @brief Change the dimensions of the blob, allocating new memory if
* necessary.
*
* This function can be called both to create an initial allocation
* of memory, and to adjust the dimensions of a top blob during Layer::Reshape
* or Layer::Forward. When changing the size of blob, memory will only be
* reallocated if sufficient memory does not already exist, and excess memory
* will never be freed.
*
* Note that reshaping an input blob and immediately calling Net::Backward is
* an error; either Net::Forward or Net::Reshape need to be called to
* propagate the new input shape to higher layers.
*/
void Reshape(const vector<int>& shape);
void Reshape(const BlobShape& shape);
void ReshapeLike(const Blob& other);
inline string shape_string() const {
ostringstream stream;
for (int i = 0; i < shape_.size(); ++i) {
stream << shape_[i] << " ";
}
stream << "(" << count_ << ")";
return stream.str();
}
inline const vector<int>& shape() const { return shape_; }
/**
* @brief Returns the dimension of the index-th axis (or the negative index-th
* axis from the end, if index is negative).
*
* @param index the axis index, which may be negative as it will be
* "canonicalized" using CanonicalAxisIndex.
* Dies on out of range index.
*/
inline int shape(int index) const {
return shape_[CanonicalAxisIndex(index)];
}
inline int num_axes() const { return shape_.size(); }
inline int count() const { return count_; }
/**
* @brief Compute the volume of a slice; i.e., the product of dimensions
* among a range of axes.
*
* @param start_axis The first axis to include in the slice.
*
* @param end_axis The first axis to exclude from the slice.
*/
inline int count(int start_axis, int end_axis) const {
CHECK_LE(start_axis, end_axis);
CHECK_GE(start_axis, 0);
CHECK_GE(end_axis, 0);
CHECK_LE(start_axis, num_axes());
CHECK_LE(end_axis, num_axes());
int count = 1;
for (int i = start_axis; i < end_axis; ++i) {
count *= shape(i);
}
return count;
}
/**
* @brief Compute the volume of a slice spanning from a particular first
* axis to the final axis.
*
* @param start_axis The first axis to include in the slice.
*/
inline int count(int start_axis) const {
return count(start_axis, num_axes());
}
/**
* @brief Returns the 'canonical' version of a (usually) user-specified axis,
* allowing for negative indexing (e.g., -1 for the last axis).
*
* @param index the axis index.
* If 0 <= index < num_axes(), return index.
* If -num_axes <= index <= -1, return (num_axes() - (-index)),
* e.g., the last axis index (num_axes() - 1) if index == -1,
* the second to last if index == -2, etc.
* Dies on out of range index.
*/
inline int CanonicalAxisIndex(int axis_index) const {
CHECK_GE(axis_index, -num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
CHECK_LT(axis_index, num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
if (axis_index < 0) {
return axis_index + num_axes();
}
return axis_index;
}
/// @brief Deprecated legacy shape accessor num: use shape(0) instead.
inline int num() const { return LegacyShape(0); }
/// @brief Deprecated legacy shape accessor channels: use shape(1) instead.
inline int channels() const { return LegacyShape(1); }
/// @brief Deprecated legacy shape accessor height: use shape(2) instead.
inline int height() const { return LegacyShape(2); }
/// @brief Deprecated legacy shape accessor width: use shape(3) instead.
inline int width() const { return LegacyShape(3); }
inline int LegacyShape(int index) const {
CHECK_LE(num_axes(), 4)
<< "Cannot use legacy accessors on Blobs with > 4 axes.";
CHECK_LT(index, 4);
CHECK_GE(index, -4);
if (index >= num_axes() || index < -num_axes()) {
// Axis is out of range, but still in [0, 3] (or [-4, -1] for reverse
// indexing) -- this special case simulates the one-padding used to fill
// extraneous axes of legacy blobs.
return 1;
}
return shape(index);
}
inline int offset(const int n, const int c = 0, const int h = 0,
const int w = 0) const {
CHECK_GE(n, 0);
CHECK_LE(n, num());
CHECK_GE(channels(), 0);
CHECK_LE(c, channels());
CHECK_GE(height(), 0);
CHECK_LE(h, height());
CHECK_GE(width(), 0);
CHECK_LE(w, width());
return ((n * channels() + c) * height() + h) * width() + w;
}
inline int offset(const vector<int>& indices) const {
CHECK_LE(indices.size(), num_axes());
int offset = 0;
for (int i = 0; i < num_axes(); ++i) {
offset *= shape(i);
if (indices.size() > i) {
CHECK_GE(indices[i], 0);
CHECK_LT(indices[i], shape(i));
offset += indices[i];
}
}
return offset;
}
/**
* @brief Copy from a source Blob.
*
* @param source the Blob to copy from
* @param copy_diff if false, copy the data; if true, copy the diff
* @param reshape if false, require this Blob to be pre-shaped to the shape
* of other (and die otherwise); if true, Reshape this Blob to other's
* shape if necessary
*/
void CopyFrom(const Blob<Dtype>& source, bool copy_diff = false,
bool reshape = false);
inline Dtype data_at(const int n, const int c, const int h,
const int w) const {
return cpu_data()[offset(n, c, h, w)];
}
inline Dtype diff_at(const int n, const int c, const int h,
const int w) const {
return cpu_diff()[offset(n, c, h, w)];
}
inline Dtype data_at(const vector<int>& index) const {
return cpu_data()[offset(index)];
}
inline Dtype diff_at(const vector<int>& index) const {
return cpu_diff()[offset(index)];
}
inline const shared_ptr<SyncedMemory>& data() const {
CHECK(data_);
return data_;
}
inline const shared_ptr<SyncedMemory>& diff() const {
CHECK(diff_);
return diff_;
}
const Dtype* cpu_data() const;
void set_cpu_data(Dtype* data);
const Dtype* gpu_data() const;
const Dtype* cpu_diff() const;
const Dtype* gpu_diff() const;
Dtype* mutable_cpu_data();
Dtype* mutable_gpu_data();
Dtype* mutable_cpu_diff();
Dtype* mutable_gpu_diff();
void Update();
void FromProto(const BlobProto& proto, bool reshape = true);
void ToProto(BlobProto* proto, bool write_diff = false) const;
/// @brief Compute the sum of absolute values (L1 norm) of the data.
Dtype asum_data() const;
/// @brief Compute the sum of absolute values (L1 norm) of the diff.
Dtype asum_diff() const;
/// @brief Compute the sum of squares (L2 norm squared) of the data.
Dtype sumsq_data() const;
/// @brief Compute the sum of squares (L2 norm squared) of the diff.
Dtype sumsq_diff() const;
/// @brief Scale the blob data by a constant factor.
void scale_data(Dtype scale_factor);
/// @brief Scale the blob diff by a constant factor.
void scale_diff(Dtype scale_factor);
/**
* @brief Set the data_ shared_ptr to point to the SyncedMemory holding the
* data_ of Blob other -- useful in Layer%s which simply perform a copy
* in their Forward pass.
*
* This deallocates the SyncedMemory holding this Blob's data_, as
* shared_ptr calls its destructor when reset with the "=" operator.
*/
void ShareData(const Blob& other);
/**
* @brief Set the diff_ shared_ptr to point to the SyncedMemory holding the
* diff_ of Blob other -- useful in Layer%s which simply perform a copy
* in their Forward pass.
*
* This deallocates the SyncedMemory holding this Blob's diff_, as
* shared_ptr calls its destructor when reset with the "=" operator.
*/
void ShareDiff(const Blob& other);
bool ShapeEquals(const BlobProto& other);
protected:
shared_ptr<SyncedMemory> data_;
shared_ptr<SyncedMemory> diff_;
vector<int> shape_;
int count_;
int capacity_;
DISABLE_COPY_AND_ASSIGN(Blob);
}; // class Blob
} // namespace caffe
#endif // CAFFE_BLOB_HPP_2. 转载链接:http://blog.csdn.net/sinat_22336563/article/details/68926382
一、前言
自下往上的顺序,在梳理完caffe的内存模型、全局资源管理、多线程系统这些基础设施之后,可以来看看包裹syncedmemory的这个Blob了。
Blob是caffe的基本数据结构,主要的作用是:
1、syncedmemory的一层封装,存储数据,并且是网络中数据交流的载体;
2、近似为N维的数组。
第一点很好理解,都是syncedmemory起到的作用。第二点N维的数组,在c++里完全可以用vector嵌套vector的方式模拟数组,为什么还这样做呢?
我的理解是
(1)在caffe中不同的场景所需要blob的维度是不一样的,维度的变换要很灵活,容器确实比数组强大,但是跟现在的方案比仍然很不方便。
(2)从syncedmemory看,caffe使用线性内存,如果想模拟多维数组的情况,只需要按照一维和多维的转换计算偏移量即可。
二、源码分析
1、数据表达方式
data_、diff_、shape_data_都是数据类型为syncedMemory的智能指针。
正是因为智能指针可以自动控制内存的释放,所以blob居然没有析构函数。
shared_ptr<SyncedMemory> data_;//原始数据
shared_ptr<SyncedMemory> diff_;//梯度数据
shared_ptr<SyncedMemory> shape_data_;
vector<int> shape_;//维度信息
int count_;//为blob的size,即总容量
int capacity_;//类比容器就是超过容量需要重新分配内存
而shape_是维度信息。
对于图像数据来说,blob是个四维数组(num,channels,height,width),计算count=num×channels×height×width。
num是batch_size,channels是颜色通道数,RGB就是3;h和w分别就是图像的高和宽了。
对于全连接网络来说,blob是二维数组(num,datum)。
对于参数来说,
如果是卷积层,blob是四维数组,与图像数据相同;
如果是全连接层那么就是二维数组(num_inputs,num_outputs)。
template <typename Dtype>
void Blob<Dtype>::Reshape(const int num, const int channels, const int height,
const int width) {//针对图像数据
vector<int> shape(4);
shape[0] = num;
shape[1] = channels;
shape[2] = height;
shape[3] = width;
Reshape(shape);
}
template <typename Dtype>
void Blob<Dtype>::Reshape(const vector<int>& shape) {//通用数据
CHECK_LE(shape.size(), kMaxBlobAxes);//CHECK_LE是判断小于等于的宏
count_ = 1;
shape_.resize(shape.size());
if (!shape_data_ || shape_data_->size() < shape.size() * sizeof(int)) {
shape_data_.reset(new SyncedMemory(shape.size() * sizeof(int)));//syncmem不会立即启动状态机,需要触发条件cpu_data等。
}
int* shape_data = static_cast<int*>(shape_data_->mutable_cpu_data());//**1、c++规范的数据类型转换 2、void*型内存按照下表访问是一个字节一个下标的,而float型则是4个字节的,所以需要强制转换数据类型。**
for (int i = 0; i < shape.size(); ++i) {
CHECK_GE(shape[i], 0);
if (count_ != 0) {
CHECK_LE(shape[i], INT_MAX / count_) << "blob size exceeds INT_MAX";
}
count_ *= shape[i];//count=num×channels×height×width
shape_[i] = shape[i];
shape_data[i] = shape[i];
}
if (count_ > capacity_) {//相当于resize
capacity_ = count_;
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
}
}如何用一维模拟n维呢?
根据这段源码可知,blob按照行优先的方式存储在线性表上,偏移的计算公式:
inline int offset(const int n, const int c = 0, const int h = 0,
const int w = 0) const {
CHECK_GE(n, 0);
CHECK_LE(n, num());
CHECK_GE(channels(), 0);
CHECK_LE(c, channels());
CHECK_GE(height(), 0);
CHECK_LE(h, height());
CHECK_GE(width(), 0);
CHECK_LE(w, width());
return ((n * channels() + c) * height() + h) * width() + w;访问只需要输入相应的偏移:
inline Dtype data_at(const int n, const int c, const int h,
const int w) const {
return cpu_data()[offset(n, c, h, w)];
}同时维度上引进轴的概念,可以采用类似python的负轴访问方式。
inline int CanonicalAxisIndex(int axis_index) const {
CHECK_GE(axis_index, -num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
CHECK_LT(axis_index, num_axes())
<< "axis " << axis_index << " out of range for " << num_axes()
<< "-D Blob with shape " << shape_string();
if (axis_index < 0) {//负轴访问
return axis_index + num_axes();
}
return axis_index;
}切片计算:count的重载函数 ,inline内联
后面会用到计算num*channel、h*w等等
inline int count() const { return count_; }
- 1
inline int count(int start_axis, int end_axis) const {
CHECK_LE(start_axis, end_axis);
CHECK_GE(start_axis, 0);
CHECK_GE(end_axis, 0);
CHECK_LE(start_axis, num_axes());
CHECK_LE(end_axis, num_axes());
int count = 1;
for (int i = start_axis; i < end_axis; ++i) {
count *= shape(i);
}
return count;
} inline int count(int start_axis) const {
return count(start_axis, num_axes());2、数学计算
涉及的计算有
/// L1正则化,绝对值之和
Dtype asum_data() const;
/// @brief Compute the sum of absolute values (L1 norm) of the diff.
Dtype asum_diff() const;
/// L2正则化,平方和
Dtype sumsq_data() const;
/// @brief Compute the sum of squares (L2 norm squared) of the diff.
Dtype sumsq_diff() const;
/// @brief Scale the blob data by a constant factor.
void scale_data(Dtype scale_factor);
/// @brief Scale the blob diff by a constant factor.
void scale_diff(Dtype scale_factor);
axpy的意思就是result=a*x+y,从表面即可推断出来。
caffe_axpy<Dtype>(count_, Dtype(-1),
static_cast<const Dtype*>(diff_->cpu_data()),
static_cast<Dtype*>(data_->mutable_cpu_data()));3、序列化和反序列化
protobuf后面再说吧。
template <typename Dtype>
void Blob<Dtype>::FromProto(const BlobProto& proto, bool reshape) {
if (reshape) {
vector<int> shape;
if (proto.has_num() || proto.has_channels() ||
proto.has_height() || proto.has_width()) {
// Using deprecated 4D Blob dimensions --
// shape is (num, channels, height, width).
shape.resize(4);
shape[0] = proto.num();
shape[1] = proto.channels();
shape[2] = proto.height();
shape[3] = proto.width();
} else {
shape.resize(proto.shape().dim_size());
for (int i = 0; i < proto.shape().dim_size(); ++i) {
shape[i] = proto.shape().dim(i);
}
}
Reshape(shape);
} else {
CHECK(ShapeEquals(proto)) << "shape mismatch (reshape not set)";
}
// copy data
Dtype* data_vec = mutable_cpu_data();
if (proto.double_data_size() > 0) {
CHECK_EQ(count_, proto.double_data_size());
for (int i = 0; i < count_; ++i) {
data_vec[i] = proto.double_data(i);
}
} else {
CHECK_EQ(count_, proto.data_size());
for (int i = 0; i < count_; ++i) {
data_vec[i] = proto.data(i);
}
}
if (proto.double_diff_size() > 0) {
CHECK_EQ(count_, proto.double_diff_size());
Dtype* diff_vec = mutable_cpu_diff();
for (int i = 0; i < count_; ++i) {
diff_vec[i] = proto.double_diff(i);
}
} else if (proto.diff_size() > 0) {
CHECK_EQ(count_, proto.diff_size());
Dtype* diff_vec = mutable_cpu_diff();
for (int i = 0; i < count_; ++i) {
diff_vec[i] = proto.diff(i);
}
}
}
template <>
void Blob<double>::ToProto(BlobProto* proto, bool write_diff) const {
proto->clear_shape();
for (int i = 0; i < shape_.size(); ++i) {
proto->mutable_shape()->add_dim(shape_[i]);
}
proto->clear_double_data();
proto->clear_double_diff();
const double* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
proto->add_double_data(data_vec[i]);
}
if (write_diff) {
const double* diff_vec = cpu_diff();
for (int i = 0; i < count_; ++i) {
proto->add_double_diff(diff_vec[i]);
}
}
}
template <>
void Blob<float>::ToProto(BlobProto* proto, bool write_diff) const {
proto->clear_shape();
for (int i = 0; i < shape_.size(); ++i) {
proto->mutable_shape()->add_dim(shape_[i]);
}
proto->clear_data();
proto->clear_diff();
const float* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
proto->add_data(data_vec[i]);
}
if (write_diff) {
const float* diff_vec = cpu_diff();
for (int i = 0; i < count_; ++i) {
proto->add_diff(diff_vec[i]);
}
}
}
三、总结
1、内存模型的封装;
2、维度信息
blob既能用作从第一层到最后一层的传输数据,也是每层的参数。
3. 转载链接:http://blog.csdn.net/mounty_fsc/article/details/51085654
Caffe中,Blob,Layer,Net,Solver是最为核心的类,以下介绍这几个类,Solver将在下一节介绍。
1 Blob
1.1 简介
Blob是:
- 对待处理数据带一层封装,用于在Caffe中通信传递。
- 也为CPU和GPU间提供同步能力
- 数学上,是一个N维的C风格的存储数组
总的来说,Caffe使用Blob来交流数据,其是Caffe中标准的数组与统一的内存接口,它是多功能的,在不同的应用场景具有不同的含义,如可以是:batches of images, model parameters, and derivatives for optimization等。
1.2 源代码
/**
* @brief A wrapper around SyncedMemory holders serving as the basic
* computational unit through which Layer%s, Net%s, and Solver%s
* interact.
*
* TODO(dox): more thorough description.
*/
template <typename Dtype>
class Blob {
public:
Blob()
: data_(), diff_(), count_(0), capacity_(0) {}
/// @brief Deprecated; use <code>Blob(const vector<int>& shape)</code>.
explicit Blob(const int num, const int channels, const int height,
const int width);
explicit Blob(const vector<int>& shape);
.....
protected:
shared_ptr<SyncedMemory> data_;
shared_ptr<SyncedMemory> diff_;
shared_ptr<SyncedMemory> shape_data_;
vector<int> shape_;
int count_;
int capacity_;
DISABLE_COPY_AND_ASSIGN(Blob);
}; // class Blob 注:此处只保留了构造函数与成员变量。
说明:
- Blob在实现上是对SyncedMemory(见1.5部分)进行了一层封装。
- shape_为blob维度,见1.3部分
- data_为原始数据
- diff_为梯度信息
- count_为该blob的总容量(即数据的size),函数count(x,y)(或count(x))返回某个切片[x,y]([x,end])内容量,本质上就是shape[x]shape[x+1]….*shape[y]的值
1.3 Blob的shape
由源代码中可以注意到Blob有个成员变量:vector shape_
其作用:
- 对于图像数据,shape可以定义为4维的数组(Num, Channels, Height, Width)或(n, k, h, w),所以Blob数据维度为n*k*h*w,Blob是row-major保存的,因此在(n, k, h, w)位置的值物理位置为((n * K + k) * H + h) * W + w。其中Number是数据的batch size,对于256张图片为一个training batch的ImageNet来说n = 256;Channel是特征维度,如RGB图像k = 3
- 对于全连接网络,使用2D blobs (shape (N, D)),然后调用InnerProductLayer
- 对于参数,维度根据该层的类型和配置来确定。对于有3个输入96个输出的卷积层,Filter核 11 x 11,则blob为96 x 3 x 11 x 11. 对于全连接层,1000个输出,1024个输入,则blob为1000 x 1024.
1.4 Blob的行优先的存储方式
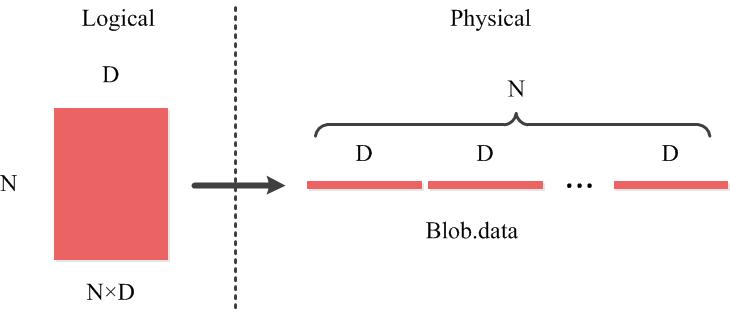
以Blob中二维矩阵为例(如全连接网络shape (N, D)),如图所示。同样的存储方式可以推广到多维。
1.5 SyncedMemory
由1.2知,Blob本质是对SyncedMemory的再封装。其核心代码如下:
/**
* @brief Manages memory allocation and synchronization between the host (CPU)
* and device (GPU).
*
* TODO(dox): more thorough description.
*/
class SyncedMemory {
public:
...
const void* cpu_data();
const void* gpu_data();
void* mutable_cpu_data();
void* mutable_gpu_data();
...
private:
...
void* cpu_ptr_;
void* gpu_ptr_;
...
}; // class SyncedMemory Blob同时保存了data_和diff_,其类型为SyncedMemory的指针。
对于data_(diff_相同),其实际值要么存储在CPU(cpu_ptr_)要么存储在GPU(gpu_ptr_),有两种方式访问CPU数据(GPU相同):
- 常量方式,void* cpu_data(),其不改变cpu_ptr_指向存储区域的值。
-
可变方式,void* mutable_cpu_data(),其可改变cpu_ptr_指向存储区值。
以mutable_cpu_data()为例void* SyncedMemory::mutable_cpu_data() { to_cpu(); head_ = HEAD_AT_CPU; return cpu_ptr_; } inline void SyncedMemory::to_cpu() { switch (head_) { case UNINITIALIZED: CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_); caffe_memset(size_, 0, cpu_ptr_); head_ = HEAD_AT_CPU; own_cpu_data_ = true; break; case HEAD_AT_GPU: #ifndef CPU_ONLY if (cpu_ptr_ == NULL) { CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_); own_cpu_data_ = true; } caffe_gpu_memcpy(size_, gpu_ptr_, cpu_ptr_); head_ = SYNCED; #else NO_GPU; #endif break; case HEAD_AT_CPU: case SYNCED: break; } }
说明:
- 经验上来说,如果不需要改变其值,则使用常量调用的方式,并且,不要在你对象中保存其指针。为何要这样设计呢,因为这样涉及能够隐藏CPU到GPU的同步细节,以及减少数据传递从而提高效率,当你调用它们的时候,SyncedMem会决定何时去复制数据,通常情况是仅当gnu或cpu修改后有复制操作,引用1官方文档中有一个例子说明何时进行复制操作。
- 调用mutable_cpu_data()可以让head转移到cpu上
- 第一次调用mutable_cpu_data()是UNINITIALIZED将执行9到14行,将为cpu_ptr_分配host内存
- 若head从gpu转移到cpu,将把数据从gpu复制到cpu中















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









