






 本文介绍如何使用Caffe框架训练自定义图像数据集,包括数据预处理、生成lmdb格式、计算图像均值、定义网络结构及训练过程。
本文介绍如何使用Caffe框架训练自定义图像数据集,包括数据预处理、生成lmdb格式、计算图像均值、定义网络结构及训练过程。
本文主要参考文末资料中的步骤,自己重新跑了一遍,大部分和上述资料中的相同,有些补充和改动.
Caffe提供mnist, cifar10, ImageNet1000等数据库,对于mnist和cifar10,数据集的准备是通过调用代码自己下载并完成,而ImageNet10的数据需要自己下载.我们可以参考ImageNet10的处理方式来生成caffe需要的lmdb/leveldb数据格式,然后进行training和testing.
1.准备图片数据
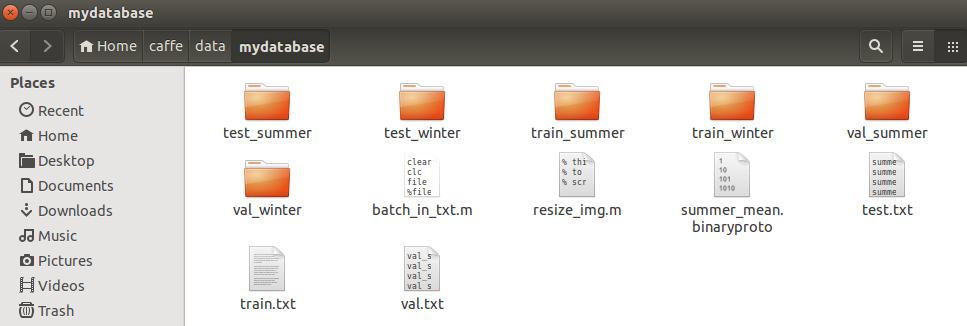
在data中新建文件夹mydatabase. 我有100个类,100张训练图片,30张评估,60张测试.
training和validation的输入用train.txt和val.txt描述,这两个txt文件列出所有文件名和他们的labels.
生成train.txt和val.txt可以用caffe提供的命令:
find-name*.jpeg|cut-d’/’-f2-3train.txt
注意文件路径;然后自行手动做分类标签.同理,生成val.txt.
当样本过多时,可以自己编写指令批量处理.
matlab代码,生成train.txt和val.txt:
batch_in_txt.m
clear all
clc
file = dir('train_summer/');
%file = dir('val_summer/');
tmp = length(file);
file = file(3:tmp);
fp = fopen('train.txt','at'); % 'at' open or create file for reading and writing, append data to end of file
%fp = fopen('val.txt','at');
for n = 1:length(file)
txt = [file(n).name ' ' num2str(n) '\n'];
fprintf(fp, txt);
end
fclose(fp);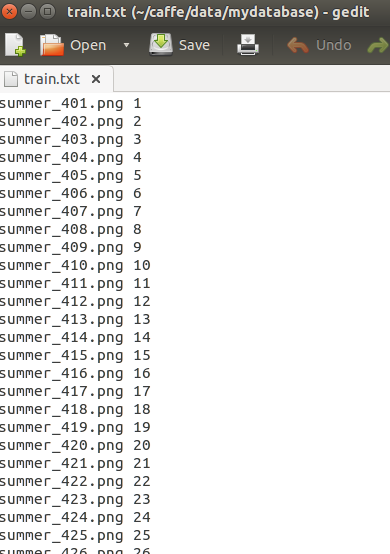
此外,我们还需要把图片大小变成256x256, caffe主页上的命令是:
(http://caffe.berkeleyvision.org/gathered/examples/imagenet.html)
for name in /path/to/imagenet/val/*.JPEG;
do
convert -resize 256x256!
name
name
done
也可以在后面修改create_imagenet.sh时把里面的RESIZE=false改成true,以生成256x256的图片.
我自己的图片尺寸是1920x1080,用matlab resize到960x540,打算先看看效果如何.对于training, validation, test set, matlab 把图片resize到960x540的代码:
file = dir(cd);
tmp = length(file);
file = file(3:tmp);
for n = 1:length(file)
tmp = imread(file(n).name);
tmp = imresize(tmp, 0.5, 'bilinear');
imwrite(tmp, file(n).name);
end注意在matlab窗口,我是进入到图片所在文件夹,然后把以上代码直接粘贴到命令行得到resize之后的图片.
2.生成所需的lmdb格式
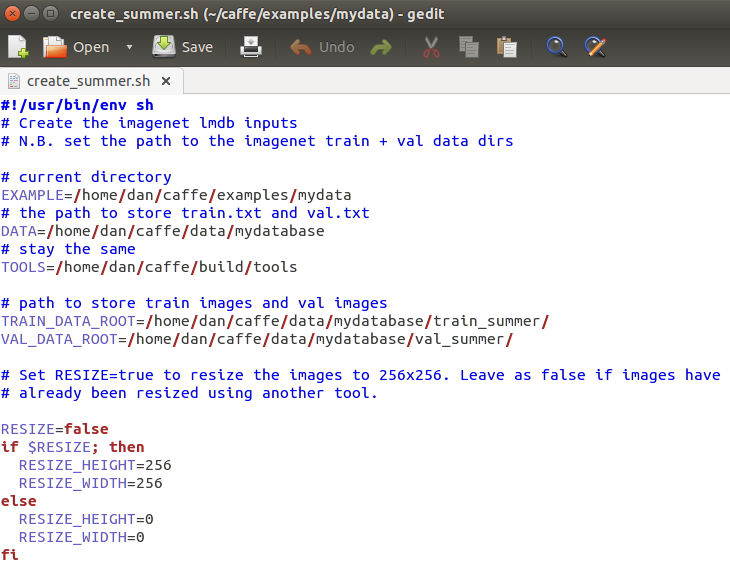
在examples/新建文件夹mydata,将examples/imagenet文件夹下的create_imagenet.sh复制到该文件夹下,改名为create_summer.sh,修改training和validation的路径,如下图:
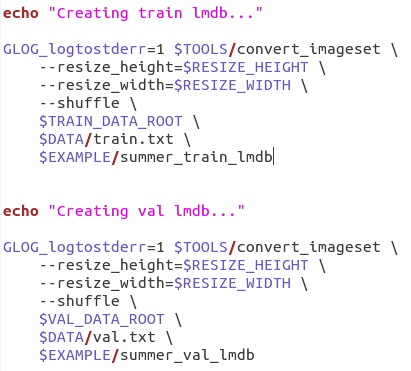
修改完成后,运行该sh:
./examples/mydata/create_summer.sh
最后会得到summer_train_lmdb和summer_val_lmdb,如下图:
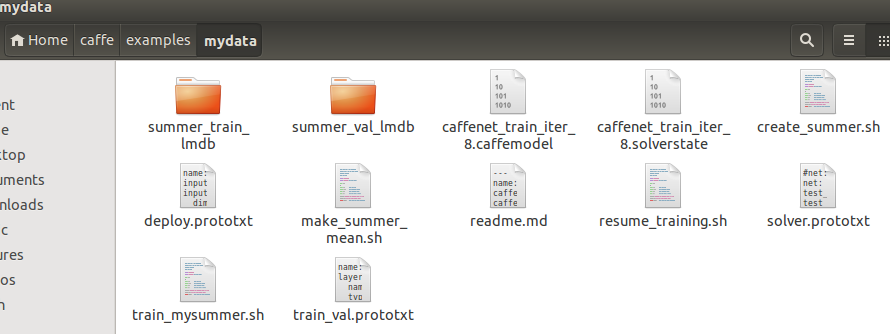
小插曲:我在运行create_summer.sh时一直出现一个错误:/convert_imageset: not found
后来发现是由于我粘贴TOOLS路径名时后面跟了几个空格,导致
TOOLS/convertimageset找不到…因为
TOOLS/convert_imageset变成了build/tools(此处有空格) /convert_imageset.
3.计算图像均值
模型需要从每张图片减去均值,所以我们需要获取training images的均值,用tools/compute_image_mean.cpp实现.这个cpp是一个很好的例子去熟悉如何操作多个组件,例如协议的缓冲区,leveldb,登陆等.
同样地,我们复制examples/imagenet的make_imagenet_mean.sh到examples/mydata中,改名为make_summer_mean.sh,修改该文件中的路径.
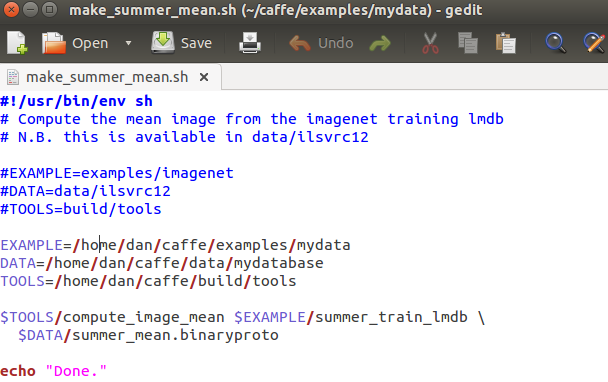
4.定义网络
把models/bvlc_reference_caffenet中的所有文件复制到examples/mydata文件夹中,修改train_val.prototxt,主要是修改各数据层的文件路径.如下图:
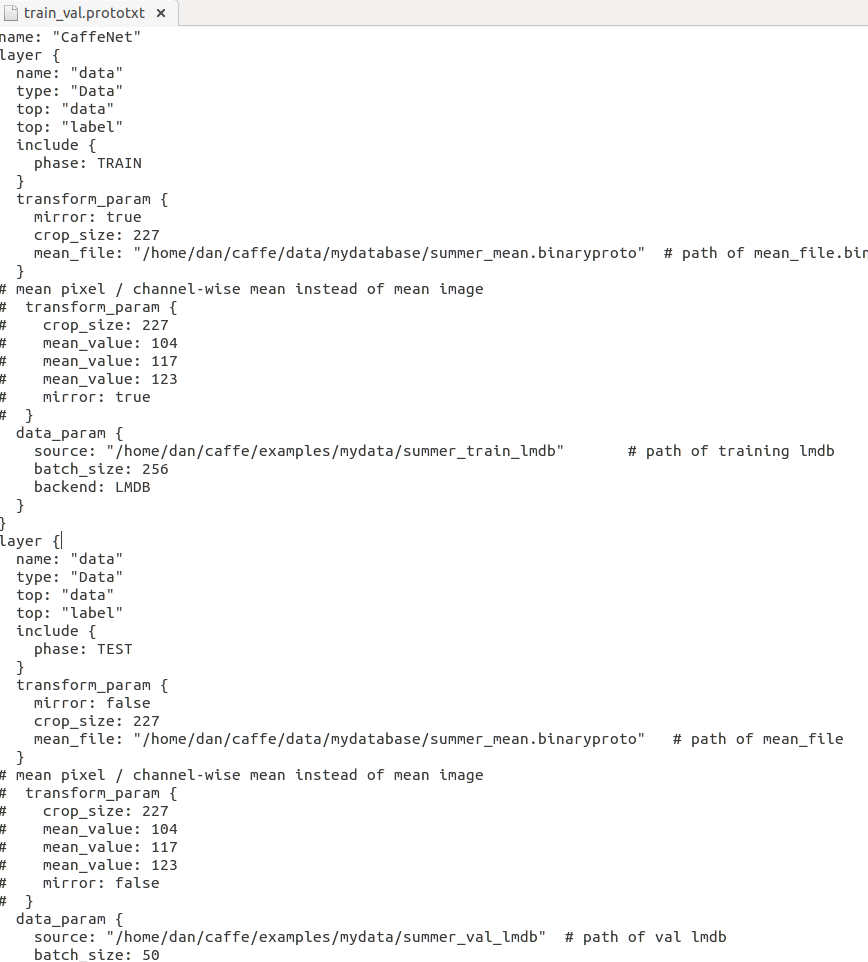
如果细心观察train_val.prototxt,可以发现他们除了数据来源和最后一层不同以外,其他基本相似.在training时,我们用softmax-loss层计算损失函数和初始化反向传播,而在验证时,我们使用精度层检测精度.
还有一个运行协议solver.prototxt,复制过来,将第一行路径改为我们自己的路径net:”examples/mydata/train_val.prototxt”. 从里面可以观察到,我们将运行256批次,迭代4500000次(90期),每1000次迭代,我们测试学习网络验证数据,我们设置初始的学习率为0.01,每100000(20期)次迭代减少学习率,显示一次信息,训练的weight_decay为0.0005,每10000次迭代,我们显示一下当前状态。
以上是教程的,实际上,以上需要耗费很长时间,因此,我们稍微改一下
test_iter: 1000是指测试的批次,我们就10张照片,设置10就可以了。
test_interval: 1000是指每1000次迭代测试一次,我们改成500次测试一次。
base_lr: 0.01是基础学习率,因为数据量小,0.01就会下降太快了,因此改成0.001
lr_policy: “step”学习率变化
gamma: 0.1学习率变化的比率
stepsize: 100000每100000次迭代减少学习率
display: 20每20层显示一次
max_iter: 450000最大迭代次数,
momentum: 0.9学习的参数,不用变
weight_decay: 0.0005学习的参数,不用变
snapshot: 10000每迭代10000次显示状态,这里改为2000次
solver_mode: GPU末尾加一行,代表用GPU进行
5.训练阶段
把examples/imagenet中的train_caffenet.sh复制到examples/mydata,改名为train_mysummer.sh,修改路径,如图:
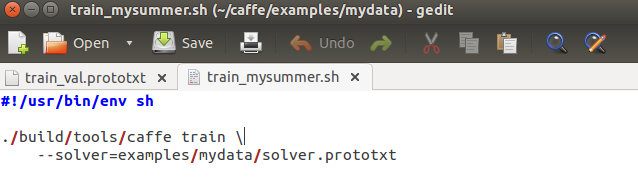
运行:./examples/mydata/train_mysummer.sh
6.恢复数据
把examples/imagenet中的resume_training.sh复制过来并运行.

















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









