










1、数学模型

2、权值训练

3、Python代码
感知器收敛的前提是两个类别必须是线性可分的,且学习速率足够小。如果两个类别无法通过一个线性决策边界进行划分,要为模型在训练集上的学习迭代次数设置一个最大值,或者设置一个允许错误分类样本数量的阈值,否则感知器训练算法将永远不停地更新权值。
# -*- coding: utf-8 -*-
'''
Created on 2017年12月15日
@author: Jason.F
@summary: 感知器学习算法
'''
import numpy as np
import time
import matplotlib.pyplot as plt
import pandas as pd
class perceptron(object):
'''
Perceptron classifier.
Parameters
eta:float=Learning rate (between 0.0 and 1.0)
n_iter:int=Passes over the training dataset.
Attributes
w_:ld-array=weights after fitting.
errors_:list=Number of misclassifications in every epoch.
'''
def __init__(self,eta=0.01,n_iter=10):
self.eta=eta
self.n_iter=n_iter
def fit(self,X,y):
'''
Fit training data.
Parameters
X:{array-like},shape=[n_samples,n_features]
Training vectors,where n_samples is the number of the samples and n_features is the number of features.
y:array-like,shape=[n_samples]
Target values.
Returns
self:object
'''
self.w_=np.zeros(1+X.shape[1])
self.errors_=[]
for _ in range(self.n_iter):
errors=0
for xi , target in zip(X,y):
update=self.eta * (target - self.predict(xi))
self.w_[1:]+=update *xi
self.w_[0]+=update
errors += int (update !=0.0)
self.errors_.append(errors)
return self
def net_input(self,X):
'''
Calculate net input
'''
return np.dot(X, self.w_[1:])+self.w_[0]
def predict(self,X):
'''
Return class label after unit step
'''
return np.where(self.net_input(X) >=0.0,1,-1)
if __name__ == "__main__":
start = time.clock()
train =pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
ppn = perceptron(eta=0.01,n_iter=10)
X_train = train.drop([4], axis=1)
X_train=X_train.values #dataframe convert to array
y_train = train[4].values
y_train=np.where(y_train == 'Iris-setosa',-1,1)
ppn.fit(X_train,y_train)
#预测
print (ppn.predict([6.9,3.0,5.1,1.8]))
#绘制错误分类样本数量
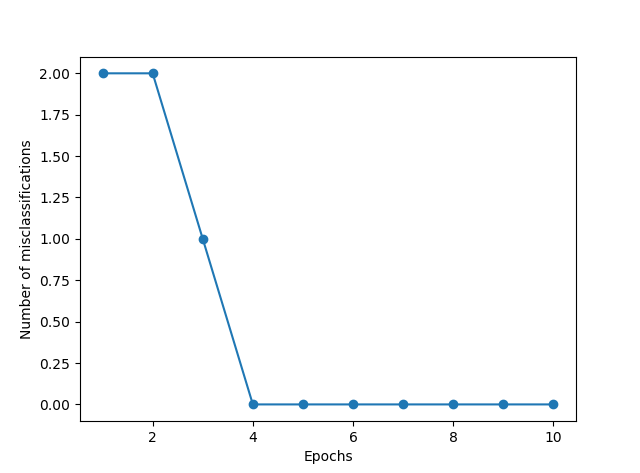
plt.plot(range(1,len(ppn.errors_)+1),ppn.errors_,marker='o')
plt.xlabel('Epochs')
plt.ylabel('Number of misclassifications')
plt.show()
end = time.clock()
print('finish all in %s' % str(end - start))
代码中用UCI机器学习库中的数据集做试验。可设置不同的学习速率eta和迭代次数n_iter观察收敛情况。














 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









