










前言
使用Python开发一个股票项目。
项目地址:
https://github.com/pythonstock/stock
相关资料:
http://blog.csdn.net/freewebsys/article/details/78294566
主要使用开发语言是python。
使用的lib库是pandas,tushare,TensorFlow,tornado等。
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/78559737
未经博主允许不得转载。
博主地址是:http://blog.csdn.net/freewebsys
1,简单的股票分析
python 真的是一个大宝库,里面的api真的超级多,而且使用超级方便。 是科学计算,数据统计分析的高效工具。程序员的最爱。入门很简单。各种类库也超级方便。
如果得到一个股票数据,要计算股票的波峰,波谷。这个是一个 【Top N 问题】 我们只需要维护一个N 个大小的数组,初始化放入N Query,按照每个Query的统计次数由大到小排序, 然后遍历这300万条记录,每读一条记录就和数组最后一个Query对比,遍历。
实现算法就忽略了,这里可以直接使用heapq 包的方法。 heapq.nlargest(n) 计算最大值,既是波峰。 heapq.nsmallest(n) 计算最大值,既是波谷。
为啥不直接取得股票的最大值,最小值。因为股票一个最高点可能是特殊的事件造成的。不具备代表性。 获得多个值能预测的充分些。
2,代码说明
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import heapq
import tushare as ts
import datetime
#使用平安银行的数据
date_end = datetime.datetime(int(2017), int(11), int(6))
date_start = (date_end + datetime.timedelta(days=-90)).strftime("%Y-%m-%d") #往前90 天数据
date_end = date_end.strftime("%Y-%m-%d")
code = "601857"
#测试
print(code, date_start, date_end)
#假设股票数据
# open, high, close, low, volume, price_change, p_change, ma5, ma10, ma20, v_ma5, v_ma10, v_ma20, turnover
stock = ts.get_hist_data(code, start=date_start, end=date_end)
stock = stock.sort_index(0) # 将数据按照日期排序下。
#打印头和尾部数据
print(len(stock))
print(stock.head(1))
print(stock.tail(1))
def wave_guess(arr):
wn = int(len(arr)/4) #没有经验数据,先设置成1/4。
print(wn)
#计算最小的N个值,也就是认为是波谷
wave_crest = heapq.nlargest(wn, enumerate(arr), key=lambda x: x[1])
wave_crest_mean = pd.DataFrame(wave_crest).mean()
#计算最大的5个值,也认为是波峰
wave_base = heapq.nsmallest(wn, enumerate(arr), key=lambda x: x[1])
wave_base_mean = pd.DataFrame(wave_base).mean()
print("######### result #########")
#波峰,波谷的平均值的差,是波动周期,对于股票就是天。
wave_period = abs(int( wave_crest_mean[0] - wave_base_mean[0]))
print("wave_period_day:", wave_period)
print("wave_crest_mean:", round(wave_crest_mean[1],2))
print("wave_base_mean:", round(wave_base_mean[1],2))
############### 以下为画图显示用 ###############
wave_crest_x = [] #波峰x
wave_crest_y = [] #波峰y
for i,j in wave_crest:
wave_crest_x.append(i)
wave_crest_y.append(j)
wave_base_x = [] #波谷x
wave_base_y = [] #波谷y
for i,j in wave_base:
wave_base_x.append(i)
wave_base_y.append(j)
#将原始数据和波峰,波谷画到一张图上
plt.figure(figsize=(20,10))
plt.plot(arr)
plt.plot(wave_base_x, wave_base_y, 'go')#红色的点
plt.plot(wave_crest_x, wave_crest_y, 'ro')#蓝色的点
plt.grid()
plt.show()
#使用收盘价格画图:
arr1 = pd.Series(stock["close"].values)
wave_guess(arr1)
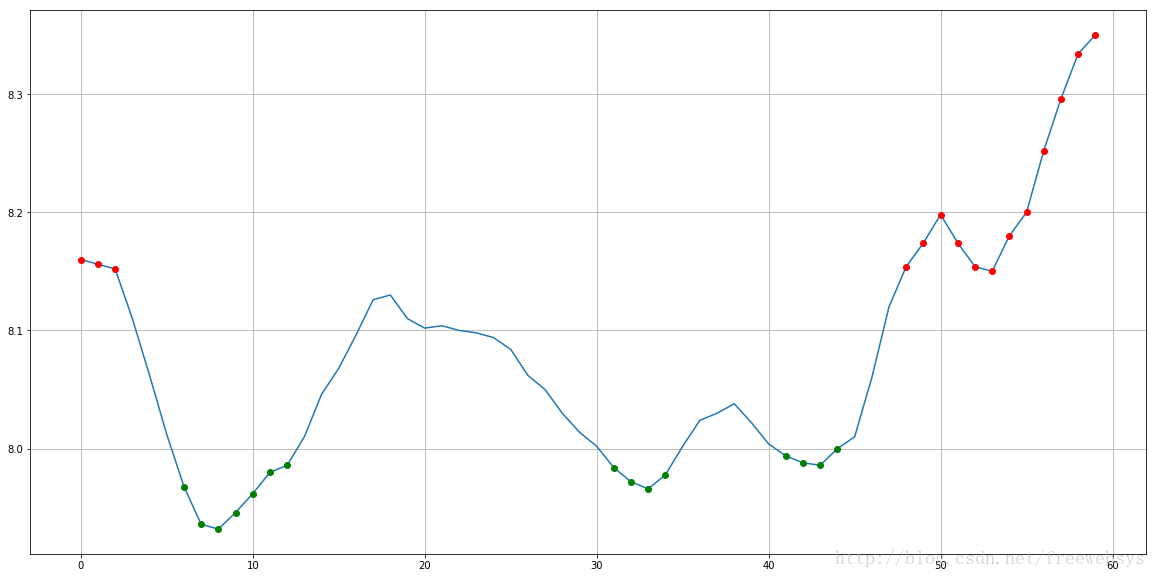
arr2 = pd.Series(stock["ma5"].values)
wave_guess(arr2)
arr3 = pd.Series(stock["v_ma5"].values)
wave_guess(arr3)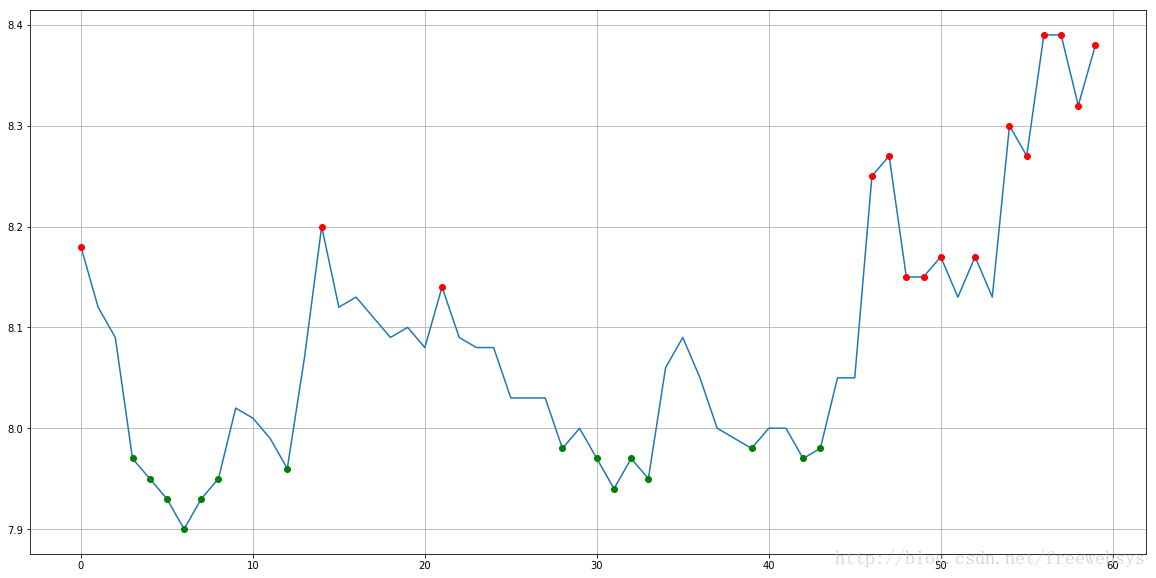
3,股票数据分析
计算最小的N个值,也就是认为是波谷
wave_crest = heapq.nlargest(wn, enumerate(arr), key=lambda x: x[1])
wave_crest_mean = pd.DataFrame(wave_crest).mean()
计算最大的5个值,也认为是波峰
wave_base = heapq.nsmallest(wn, enumerate(arr), key=lambda x: x[1])
怎样从一个集合中获得最大或者最小的 N 个元素列表?
http://python3-cookbook.readthedocs.io/zh_CN/latest/c01/p04_find_largest_or_smallest_n_items.html
使用堆进行计算。
4,总结
python的类库非常的丰富,使用起来非常方便。
其实运算速度也挺快的。关键是开发速度快,节约人力成本。
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/78559737
未经博主允许不得转载。
博主地址是:http://blog.csdn.net/freewebsys















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









