







 本文探讨如何加速深度学习模型的收敛速度,主要介绍mini-batch和Stochastic gradient descent两种方法。mini-batch通过分组计算梯度,提高更新参数的效率,而Stochastic gradient descent每次迭代使用单个样本,尽管速度较快但收敛路径曲折。对比来看,mini-batch在速度和稳定性间取得平衡,常优于传统的batch gradient descent。
本文探讨如何加速深度学习模型的收敛速度,主要介绍mini-batch和Stochastic gradient descent两种方法。mini-batch通过分组计算梯度,提高更新参数的效率,而Stochastic gradient descent每次迭代使用单个样本,尽管速度较快但收敛路径曲折。对比来看,mini-batch在速度和稳定性间取得平衡,常优于传统的batch gradient descent。
在深层神经网络那篇博客中讲了,深层神经网络的局部最优解问题,深层神经网络中存在局部极小点的可能性比较小,大部分是鞍点。因为鞍面上的梯度接近于0,在鞍面上行走是非常缓慢的。因此,必须想办法加速收敛速度,使其更快找到全局最优解。本文将介绍mini-batch与Stochastic gradient descent方法。
1.mini-batch
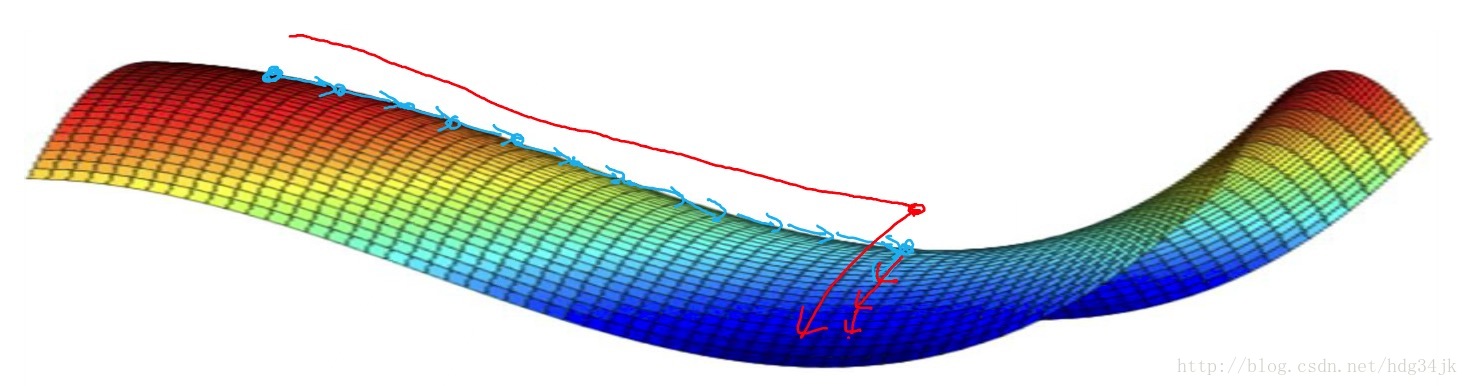
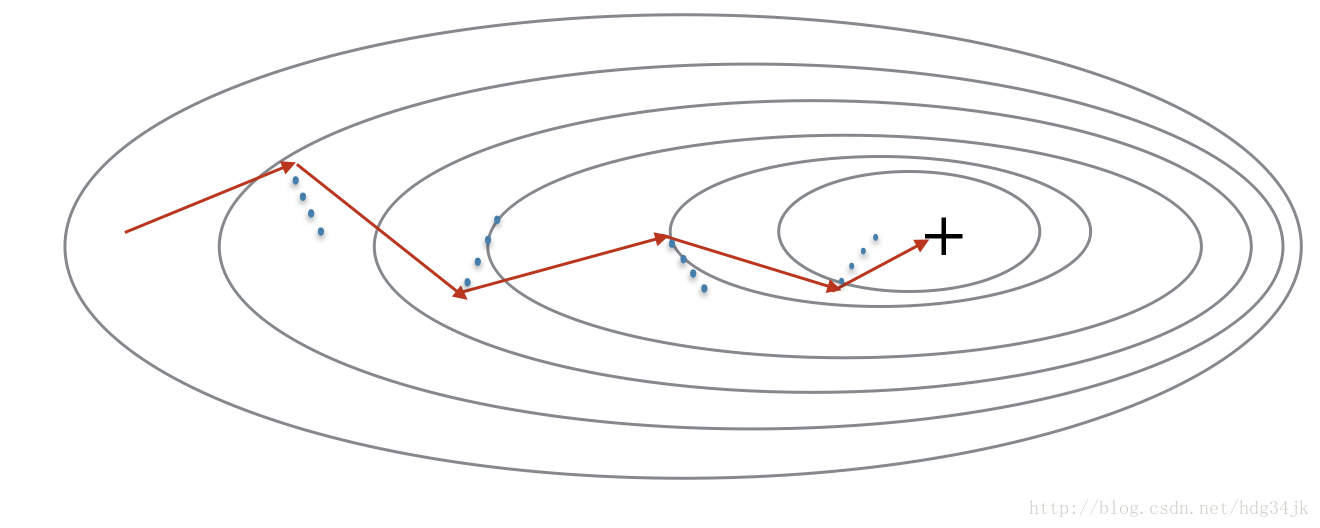
之前的梯度下降法是将训练集所有的梯度计算之后,再更新参数,这样大部分时间浪费在计算梯度上。而mini-batch是将训练集分组,分组之后,分别对每组求梯度,然后更新参数。加入分 8组,则每次迭代将会做8次梯度下降,更新8次参数。所以mini-batch比传统的梯度下降法下降的速度快,但是mini-batch的cost曲线没有传统梯度下降法的cost曲线光滑,大致对比如下:
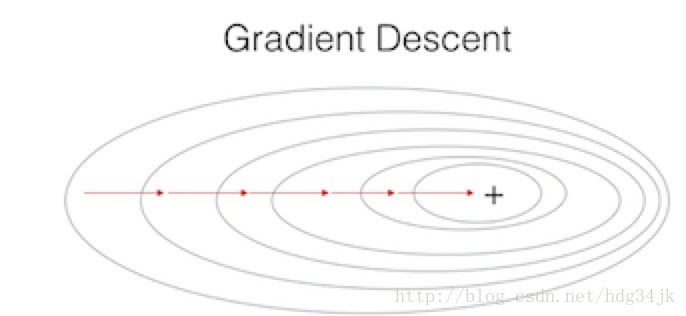
梯度下降过程
mini-batch下降过程
mini-batch实现步骤:
- 确定mini-batch size,一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3871
3871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









