






梯度下降法是深度学习中常用的优化算法,主要有批量随机梯度下降(Batch Stochastic Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)、小批量随机梯度下降(Mini-Batch Stochastic Gradient Descent)三种形式,这边大致介绍下三者的区别:
1.Batch SGD:基于所有的样本求解梯度,而后更新参数完成一次迭代;
2.SGD:基于一个样本求解梯度,而后更新参数完成一次迭代;
3.Mini Batch SGD:从整个数据集取部分的样本,而后基于这些样本求解梯度,并更新参数完成一次迭代
Mini Batch SGD利用小批量样本进行优化,一方面避免的SGD容易陷入局部收敛的问题,一方面较Batch SGD更快地完成一次更新,因此可以有效地加快训练速度。
为了掌握Mini Batch SGD算法,在网上学习了一些博主的内容,现在总结总结,并就一元一次函数、二元二次函数来玩一玩Mini Batch SGD。
详细了解三者的区别可以参考:批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)
算法流程
整体算法流程很简单,主要以下4步,然后不断迭代,直到收敛就行了。
1.构建前向传播模型
2.计算损失函数
3.求解梯度
4.反向传播, 更新权重
公式求解
从知乎看到一篇文章,通过公式十分直观地地介绍了Mini Batch SGD的基本原理,看后十分受益,公式我就不再推导了,链接直接放这:手撕公式代码比较GD/SGD/mini-batch SGD
代码编写
上面的博文主要介绍了基于线性模型的公式推导,因此我们先就一次函数来了解Mini Batch SGD整体算法的编写。
假设我们要求解一个一次函数的系数,形式为:
y=a*x+b
为了方便理解算法的编写过程,这里直接求解y=3x+4这个函数,看看Mini Batch SGD是怎么把a=3,b=4给优化出来的。
前向传播模型
def forward_single(a,b,x): # 单个样本作为输入
return a*x+b
def forward_multi(a,b,X): # 多个样本作为输入
y_list=[]
for j in range(len(X)):
y_list.append(forward_single(a,b,X[j]))
return np.array(y_list)
计算损失函数
为了与上面的博文一致,损失函数也选择均方误差(Mean Squared Error,MSE)。
def loss_single (y, ypred): # 单个样本的MSE
return (y - ypred)**2
def loss_whole(y, ypred): # 多个样本的MSE
loss_sum = 0.0
n = len(y)
for j in range(n):
loss_sum += loss_single(y[j], ypred[j])
return loss_sum/n
求解梯度
def loss_a_single(X, y, ypred): # dl/da 单样本计算
return -1*X*(y - ypred)
def loss_a(X, y, ypred): # dl/da 多样本计算
s = 0
n = len(y)
for i in range(n):
s += loss_a_single(X[i], y[i], ypred[i])
return (2/n)*s
def loss_b_single(y, ypred): # dl/db 单样本计算
return -1*(y - ypred)
def loss_b(y, y_pred): # dl/db 多样本计算
n=len(y)
s=int(0)
for i in range(len(y)):
s += loss_b_single(y[i], y_pred[i])
return (2/n) * s
反向传播更新权重
def mb_SGD(X, y, epochs):
a = np.random.randn()
b = np.random.rand()
mse_loss_list = []
lr = 0.005 # learning rate,暂定个0.005
n = len(X) # n 为数据集大小
n_iter = [] # 分析迭代次数
c_iter = 1 # 储存迭代次数
batch_size = 100
for e in range(1, epochs + 1):
iter_per_epoch = int(n / batch_size)
for j in range(iter_per_epoch):
rand_ind_list = np.random.choice(X.shape[0], batch_size, replace=False) # 从整个数据集X中随机抽取batch_size个元素
X_samples = X[rand_ind_list]
y_samples = y[rand_ind_list]
y_pred = forward_multi(a, b,X_samples)
# 根据求解的梯度更新权重
a = a - lr * loss_a(X_samples, y_samples, y_pred)
b = b - lr * loss_b(y_samples, y_pred)
mse_loss_list.append(loss_whole(y_samples, y_pred))
n_iter.append(c_iter)
c_iter += 1
if e % 100== 0:
print(
f"[mbSGD] | epoch: [{e} / {epochs}], batch_szie: {len(rand_ind_list)}, {iter_per_epoch} iterations per epoch")
return a, b, n_iter, mse_loss_list
上面的算法基本就完成整个mini batch SGD的编写了,为了验证,首先需要搞一个数据集,然后迭代一圈看看效果。
构建数据集
# A.定义目标函数
def target_y(x):
y=3*x+4 # 直接利用目标函数生成数据集
return y
# B. 根据所需数量产生数据集
def my_dataset(size): # size: 数据集大小
X=np.random.rand(size)
Y=target_y(X)
dataset=(X,Y)
return dataset
验证
if __name__ == "__main__":
EPOCH=500 # 进行500轮的全数据集遍历
dataset=my_dataset(5000)
a, b, n_iter, mse_loss_list=mb_SGD(dataset[0],dataset[1],EPOCH)
print('a= %10.6f b= %10.6f' % (a,b))
plt.plot(n_iter, mse_loss_list)
plt.xlabel('iteration')
plt.ylabel('loss')
plt.show()
运行结果如下:

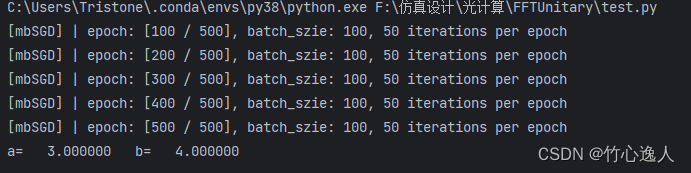
收敛还是蛮快的,求解得到a=3, b=4,与我们预期的一致。
别忘了import:
import numpy as np
import matplotlib.pyplot as plt
ok,现在进阶一下,看看二次函数的Mini Batch SGD。
假设要求解的二元二次函数形式是:
y=ax1+bx22
为了方便演示,直接求解y=3x1+2x22,此时我们知道如果算法正确的话,迭代优化后应该得到a=3, b=2。
过程和上面一致,就不一步步说了,直接上代码:
import math
import numpy as np
import matplotlib.pyplot as plt
'''
step1: 定义随机梯度下降法需要的函数
'''
# A.前向传播模型
def forward_single (a,b, X): # 单个样本作为输入
return a*X[0]+b*X[1]**2
def forward_multi(a,b,X): # 多个样本作为输入
y_list=[]
for j in range(len(X)):
y_list.append(forward_single(a,b,X[j]))
return np.array(y_list)
# B.计算损失函数
def loss_single (y, ypred): # 单个样本的MSE
return (y - ypred)**2
def loss_whole(y, ypred): # 多个样本的MSE
loss_sum = 0.0
n = len(y)
for j in range(n):
loss_sum += loss_single (y[j], ypred[j])
return loss_sum/n
# C.求解梯度
def loss_a_single(X, y, ypred): # dl/da 单样本计算
return -1*X[0]*(y - ypred)
def loss_a(X, y, ypred): # dl/da 多样本计算
s = 0
n = len(y)
for i in range(n):
s += loss_a_single(X[i], y[i], ypred[i])
return (2/n)*s
def loss_b_single(X, y, ypred): # dl/db 单样本计算
return -1*X[1]**2*(y - ypred)
def loss_b(X, y, ypred): # dl/db 多样本计算
s = 0
n = len(y)
for i in range(n):
s += loss_b_single(X[i], y[i], ypred[i])
return (2/n)*s
'''
step2: 反向传播求解梯度,并更新权重
'''
# A.定义mini_batch SGD函数
def mb_SGD(X, y,epochs): # y_max是防止溢出
a = np.random.randn()
b = np.random.rand()
mse_loss_list = []
lr = 0.005
n = len(X) # n 为数据集大小
n_iter = [] # 分析迭代次数
c_iter = 1 # 储存迭代次数
batch_size = 50
for e in range(1, epochs + 1):
iter_per_epoch = int(n / batch_size)
for j in range(iter_per_epoch):
# 从整个数据集X中随机抽取batch_size个元素
rand_ind_list = np.random.choice(X.shape[0], batch_size, replace=False)
X_samples = X[rand_ind_list]
y_samples = y[rand_ind_list]
y_pred = forward_multi(a,b, X_samples)
# 根据求解的梯度更新权重
a = a - lr * loss_a(X_samples, y_samples, y_pred)
b = b- lr * loss_b(X_samples, y_samples, y_pred)
mse_loss_list.append(loss_whole(y_samples, y_pred))
n_iter.append(c_iter)
c_iter += 1
if e % 100 == 0:
print(
f"[mbSGD] | epoch: [{e} / {epochs}], batch_szie: {len(rand_ind_list)}, {iter_per_epoch} iterations per epoch")
return a,b, n_iter, mse_loss_list
'''
step3: 生成数据集
'''
# A.定义目标函数
def target_y(X):
y=3*X[:,0]+2*X[:,1]**2
return y
# B. 根据所需数量产生数据集
def my_dataset(size):
X=np.random.rand(size,2)
Y=target_y(X)
dataset=(X,Y)
return dataset
if __name__ == "__main__":
EPOCH = 500 # 进行500轮的全数据集遍历
dataset = my_dataset(5000)
a, b, n_iter, mse_loss_list = mb_SGD(dataset[0], dataset[1], EPOCH)
print('a= %10.6f b= %10.6f' % (a, b))
plt.plot(n_iter, mse_loss_list)
plt.xlabel('iteration')
plt.ylabel('loss')
plt.show()
运行结果如下:
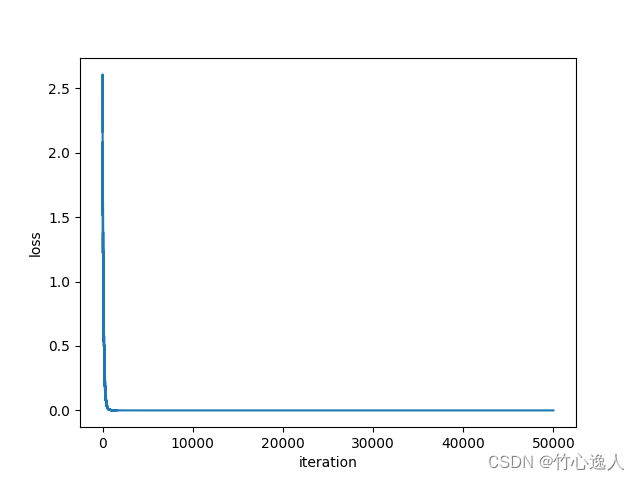
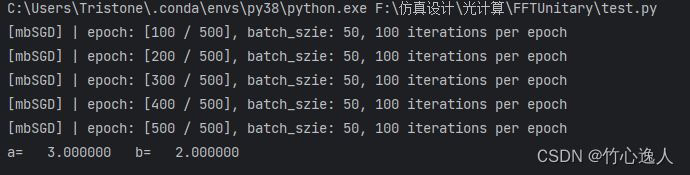
跟一次函数一样,收敛很快,求解也很正确。
以上是关于小批量随机梯度下降算法基本原理的示例,为了避免套公式求解梯度,可以考虑把权重放到神经网络里面。参考:
玩一玩小批量随机梯度下降——进阶 by tensflow















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









