







一、确保caffe环境已经搭建好,由于没有N卡GPU,只能使用CPU,反正有的是时间。
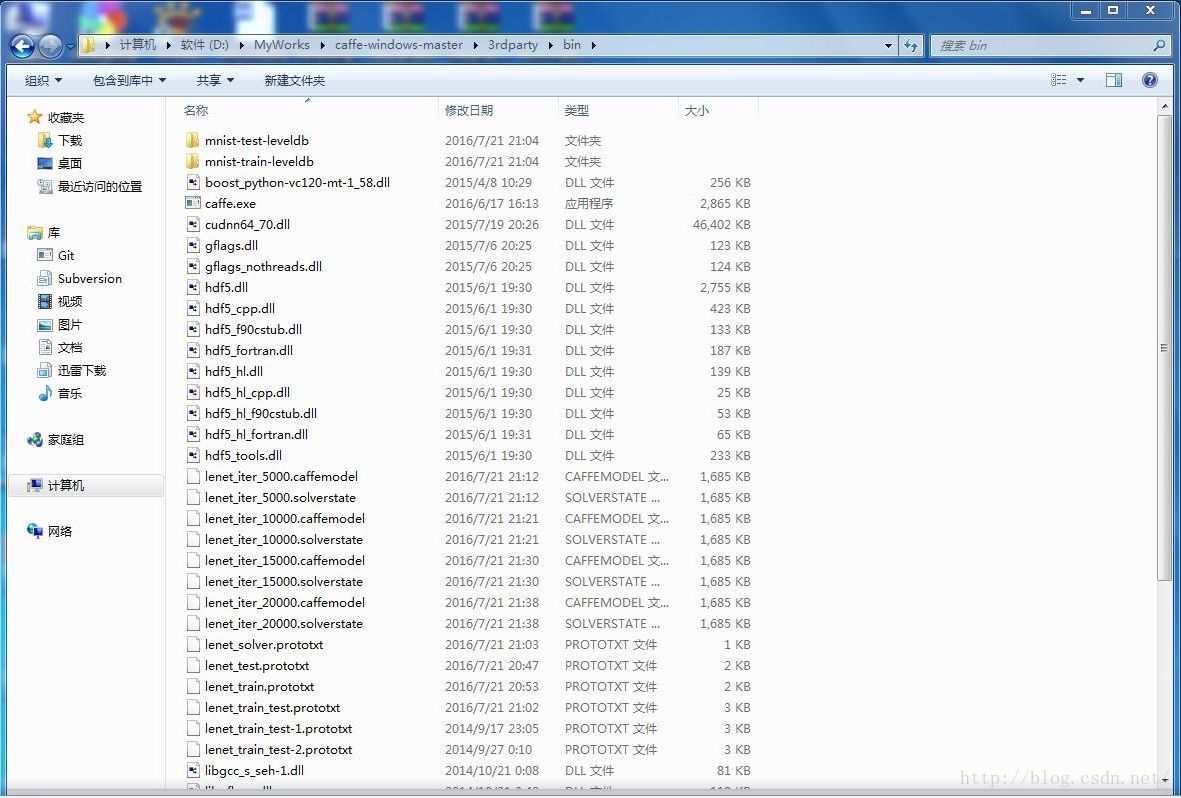
二、准备相关的配置文件:
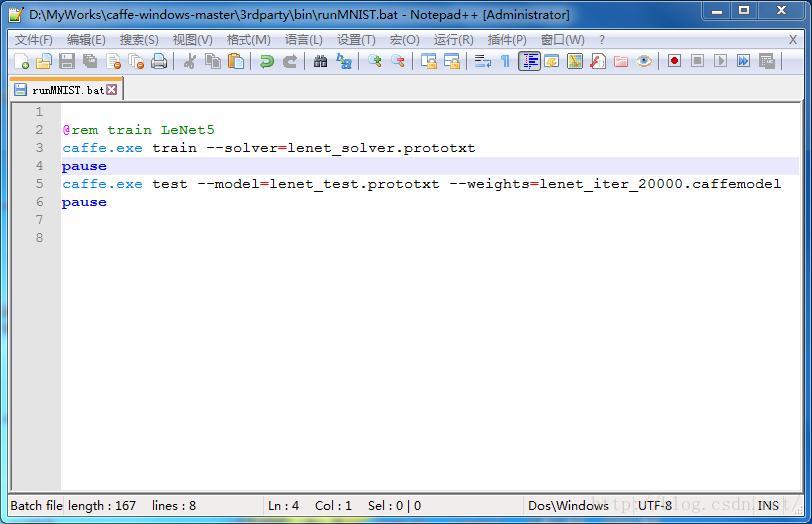
lenet_solver.prototxt ——
# The train/test net protocol buffer definition
net: "D:/MyWorks/caffe-windows-master/3rdparty/bin/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 20000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "lenet"
# solver mode: 0 for CPU and 1 for GPU
solver_mode: 0
lenet_train_test.prototxt ——
name: "LeNet"
layers {
name: "mnist"
type: DATA
top: "data"
top: "label"
data_param {
source: "D:/MyWorks/caffe-windows-master/3rdparty/bin/mnist-train-leveldb"
backend: LEVELDB
batch_size: 128
}
transform_param {
scale: 0.00390625
}
include: { phase: TRAIN }
}
layers {
name: "mnist"
type: DATA
top: "data"
top: "label"
data_param {
source: "D:/MyWorks/caffe-windows-master/3rdparty/bin/mnist-test-leveldb"
backend: LEVELDB
batch_size: 100
}
transform_param {
scale: 0.00390625
}
include: { phase: TEST }
}
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
blobs_lr: 1
blobs_lr: 2
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layers {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
name: "conv2"
type: CONVOLUTION
bottom: "pool1"
top: "conv2"
blobs_lr: 1
blobs_lr: 2
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layers {
name: "pool2"
type: POOLING
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
name: "ip1"
type: INNER_PRODUCT
bottom: "pool2"
top: "ip1"
blobs_lr: 1
blobs_lr: 2
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layers {
name: "relu1"
type: RELU
bottom: "ip1"
top: "ip1"
}
layers {
name: "ip2"
type: INNER_PRODUCT
bottom: "ip1"
top: "ip2"
blobs_lr: 1
blobs_lr: 2
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layers {
name: "accuracy"
type: ACCURACY
bottom: "ip2"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layers {
name: "loss"
type: SOFTMAX_LOSS
bottom: "ip2"
bottom: "label"
top: "loss"
}
lenet_test.prototxt ——
name: "LeNet-test"
layers {
layer {
name: "mnist"
type: "data"
source: "D:/MyWorks/caffe-windows-master/3rdparty/bin/mnist-test-leveldb"
batchsize: 100
scale: 0.00390625
}
top: "data"
top: "label"
}
layers {
layer {
name: "conv1"
type: "conv"
num_output: 20
kernelsize: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "data"
top: "conv1"
}
layers {
layer {
name: "pool1"
type: "pool"
kernelsize: 2
stride: 2
pool: MAX
}
bottom: "conv1"
top: "pool1"
}
layers {
layer {
name: "conv2"
type: "conv"
num_output: 50
kernelsize: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool1"
top: "conv2"
}
layers {
layer {
name: "pool2"
type: "pool"
kernelsize: 2
stride: 2
pool: MAX
}
bottom: "conv2"
top: "pool2"
}
layers {
layer {
name: "ip1"
type: "innerproduct"
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool2"
top: "ip1"
}
layers {
layer {
name: "relu1"
type: "relu"
}
bottom: "ip1"
top: "ip1"
}
layers {
layer {
name: "ip2"
type: "innerproduct"
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "ip1"
top: "ip2"
}
layers {
layer {
name: "prob"
type: "softmax"
}
bottom: "ip2"
top: "prob"
}
layers {
layer {
name: "accuracy"
type: "accuracy"
}
bottom: "prob"
bottom: "label"
top: "accuracy"
}
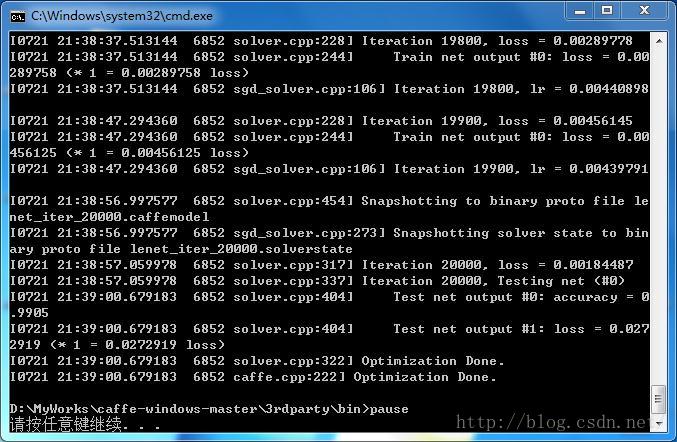
三、开始训练,去干点别的事情吧!
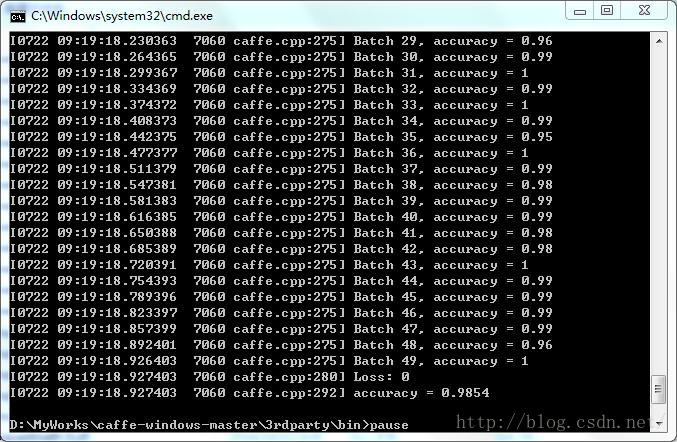
四、回来发现已经训练好了,测试!














 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









