






 本文介绍了一种基于字符级别的卷积神经网络模型,用于文本分类任务。模型无需预训练词向量,直接从字符层面训练,适用于不同语言和领域的文本数据。
本文介绍了一种基于字符级别的卷积神经网络模型,用于文本分类任务。模型无需预训练词向量,直接从字符层面训练,适用于不同语言和领域的文本数据。
卷积神经网络从ImageNet做起,后来自然语言处理领域开始觉察到CNN对于文本处理可能会有用,因此也开始自觉使用CNN。专栏前三篇文章讲了文本相似度方向的论文,本文实现论文为Text Understanding from Scratch和Character-level Convolutional Networks for Text Classification 这两篇文章作者都是纽约大学Yann LeCun团队,两者实现内容也80%相似。
深度学习处理自然语言处理问题,有的基于短语,有的基于单词。该篇文章受启发于CV领域的像素级别,因此采用从字符角度出发重新训练神经网络。神经网络就不需要提前知道关于单词的知识(lookupTable or word2vec),并且这些单词的知识往往是高维的,很难应用于卷积神经网络中。除此之外,卷积神经网络也不再需要提前知道语法和语义的知识。因此,论文作者称这种基于的字符学习为从零开始学习(learn from scratch)。值得一提的是,这种from scratch网络的学习一般都需要比较大的数据集,否则根本拟合不了模型。
整个论文的实现代码已上传至github。 欢迎fork和start。
数据集
论文中提到了五种数据集,如果单独寻找的话效率太低。我也是在网上找了两天还没有找全。巧合的是在知乎上看到一个数据集的链接,然后发现了这五个数据集。 为了方便起见,我在这里只采用了AG’s corpus。它由超过2000个数据源和496,835种类型的新闻组成。这里选用数量最多的四种类型的新闻作为数据集,使用title和description作为输入,类别作为标签。
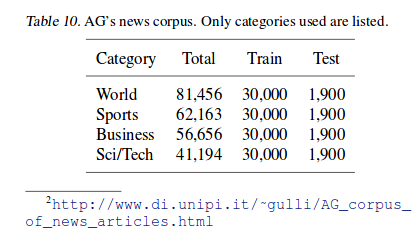
之前文章提到过,对于神经网络的tensorflow代码来说,模型的构建问题都不大,只要理清过程中tensor的变化,写出的代码就不会太差。初学者大部分时间都浪费在了数据的处理上,这篇论文的仿真也是这样,数据处理的data_helper.py占用了大概50%的时间。因为是基于字符的神经网络,这里将字符用onehot向量表示出来,总共69个字符,未知的和空字符都用全零向量表示。
alphabet = "abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:'\"/\\|_@#$%^&*~`+-=<>()[]{}"代码上都有注释,相信看过数据集的同学,应该会很好理解代码的内容。
# coding=utf-8
import numpy as np
from config import config
import csv
class Dataset(object):
def __init__(self, data_source):
self.data_source = data_source
self.index_in_epoch = 0
self.alphabet = config.alphabet
self.alphabet_size = config.alphabet_size
self.num_classes = config.nums_classes
self.l0 = config.l0
self.epochs_completed = 0
self.batch_size = config.batch_size
self.example_nums = config.example_nums
self.doc_image = []
self.label_image = []
def next_batch(self):
# 得到Dataset对象的batch
start = self.index_in_epoch
self.index_in_epoch += self.batch_size
if self.index_in_epoch > self.example_nums:
# Finished epoch
self.epochs_completed += 1
# Shuffle the data
perm = np.arange(self.example_nums)
np.random.shuffle(perm)
self.doc_image = self.doc_image[perm]
self.label_image = self.label_image[perm]
# Start next epoch
start = 0
self.index_in_epoch = self.batch_size
assert self.batch_size <= self.example_nums
end = self.index_in_epoch
batch_x = np.array(self.doc_image[start:end], dtype='int64')
batch_y = np.array(self.label_image[start:end], dtype='float32')
return batch_x, batch_y
def dataset_read(self):
# doc_vec表示一个一篇文章中的所有字母,doc_image代表所有文章
# label_class代表分类
# doc_count代表数据总共有多少行
docs = []
label = []
doc_count = 0
csvfile = open(self.data_source, 'r')
for line in csv.reader(csvfile, delimiter=',', quotechar='"'):
content = line[1] + ". " + line[2]
docs.append(content.lower())
label.append(line[0])
doc_count = doc_count + 1
# 引入embedding矩阵和字典
print "引入嵌入词典和矩阵"
embedding_w, embedding_dic = self.onehot_dic_build()
# 将每个句子中的每个字母,转化为embedding矩阵的索引
# 如:doc_vec表示一个一篇文章中的所有字母,doc_image代表所有文章
doc_image = []
label_image = []
print "开始进行文档处理"
for i in range(doc_count):
doc_vec = self.doc_process(docs[i], embedding_dic)
doc_image.append(doc_vec)
label_class = np.zeros(self.num_classes, dtype='float32')
label_class[int(label[i]) - 1] = 1
label_image.append(label_class)
del embedding_w, embedding_dic
print "求得训练集与测试集的tensor并赋值"
self.doc_image = np.asarray(doc_image, dtype='int64')
self.label_image = np.array(label_image, dtype='float32')
def doc_process(self, doc, embedding_dic):
# 如果在embedding_dic中存在该词,那么就将该词的索引加入到doc的向量表示doc_vec中,不存在则用UNK代替
# 不到l0的文章,进行填充,填UNK的value值,即0
min_len = min(self.l0, len(doc))
doc_vec = np.zeros(self.l0, dtype='int64')
for j in range(min_len):
if doc[j] in embedding_dic:
doc_vec[j] = embedding_dic[doc[j]]
else:
doc_vec[j] = embedding_dic['UNK']
return doc_vec
def onehot_dic_build(self):
# onehot编码
alphabet = self.alphabet
embedding_dic = {}
embedding_w = []
# 对于字母表中不存在的或者空的字符用全0向量代替
embedding_dic["UNK"] = 0
embedding_w.append(np.zeros(len(alphabet), dtype='float32'))
for i, alpha in enumerate(alphabet):
onehot = np.zeros(len(alphabet), dtype='float32')
embedding_dic[alpha] = i + 1
onehot[i] = 1
embedding_w.append(onehot)
embedding_w = np.array(embedding_w, dtype='float32')
return embedding_w, embedding_dic
# 如果运行该文件,执行此命令,否则略过
if __name__ == "__main__":
data = Dataset("data/ag_news_csv/train.csv")
data.dataset_read()模型构建
论文中设计了两种神经网络,一个大的一个小的。他们都有6个卷积层和3个全连接层总共9层,区别是卷基层通道的个数frame和全连接层神经元的个数。
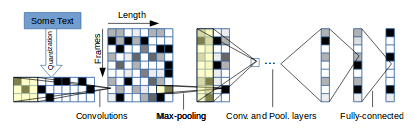
论文中给出了大小两种模型详细的卷积层和全连接层的配置参数,卷积和池化的方式都采用“VALID”,即不进行补零操作。另外在全连接层中间还有两个dropout层,dropout的概率为0.5,以防止出现过拟合。权重初始化的方式为高斯分布,大模型的均值方差为(0,0.02),小模型的均值方差为(0,0.05)。
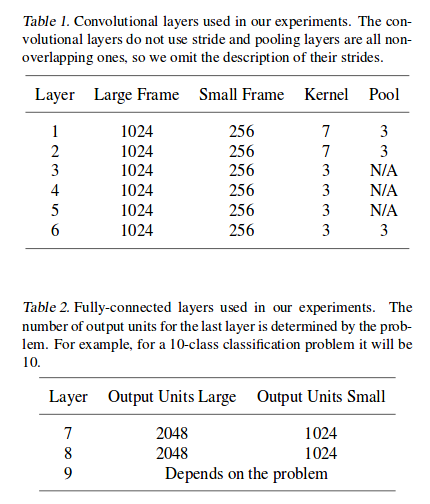
另外文中给出了公式l6=(l0 - 96)/27。这个公式乍一看不好理解,但其实就是6个卷积层结束以后,l的长度变化。这里以小模型举例,具体情况如下图所示:

模型构建(cnnModel.py)的代码如下,具体解释代码中也会有:
# coding=utf-8
import tensorflow as tf
from data_helper import Dataset
from math import sqrt
from config import config
class CharCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, l0, num_classes, conv_layers, fc_layers, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, l0], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
train_data = Dataset(config.train_data_source)
self.W, _ = train_data.onehot_dic_build()
self.x_image = tf.nn.embedding_lookup(self.W, self.input_x)
self.x_flat = tf.expand_dims(self.x_image, -1)
for i, cl in enumerate(conv_layers):
with tf.name_scope("conv_layer-%s" % (i+1)):
print "开始第" + str(i + 1) + "卷积层的处理"
filter_width = self.x_flat.get_shape()[2].value
filter_shape = [cl[1], filter_width, 1, cl[0]]
stdv = 1 / sqrt(cl[0] * cl[1])
w_conv = tf.Variable(tf.random_uniform(filter_shape, minval=-stdv, maxval=stdv),
dtype='float32', name='w')
# w_conv = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.05), name="W")
b_conv = tf.Variable(tf.random_uniform(shape=[cl[0]], minval=-stdv, maxval=stdv), name='b')
# b_conv = tf.Variable(tf.constant(0.1, shape=[cl[0]]), name="b")
conv = tf.nn.conv2d(
self.x_flat,
w_conv,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv"
)
h_conv = tf.nn.bias_add(conv, b_conv)
if not cl[-1] is None:
ksize_shape = [1, cl[2], 1, 1]
h_pool = tf.nn.max_pool(
h_conv,
ksize=ksize_shape,
strides=ksize_shape,
padding='VALID',
name='pool')
else:
h_pool = h_conv
self.x_flat = tf.transpose(h_pool, [0, 1, 3, 2], name='transpose')
with tf.name_scope('reshape'):
fc_dim = self.x_flat.get_shape()[1].value * self.x_flat.get_shape()[2].value
self.x_flat = tf.reshape(self.x_flat, [-1, fc_dim])
weights = [fc_dim] + fc_layers
for i, fl in enumerate(fc_layers):
with tf.name_scope('fc_layer-%s' % (i+1)):
print "开始第" + str(i + 1) + "全连接层的处理"
stdv = 1 / sqrt(weights[i])
w_fc = tf.Variable(tf.random_uniform([weights[i], fl], minval=-stdv, maxval=stdv),
dtype='float32', name='w')
b_fc = tf.Variable(tf.random_uniform(shape=[fl], minval=-stdv, maxval=stdv), dtype='float32', name='b')
# 不同的初始化方式
# w_fc = tf.Variable(tf.truncated_normal([weights[i], fl], stddev=0.05), name="W")
# b_fc = tf.Variable(tf.constant(0.1, shape=[fl]), name="b")
self.x_flat = tf.nn.relu(tf.matmul(self.x_flat, w_fc) + b_fc)
with tf.name_scope('drop_out'):
self.x_flat = tf.nn.dropout(self.x_flat, self.dropout_keep_prob)
with tf.name_scope('output_layer'):
print "开始输出层的处理"
# w_out = tf.Variable(tf.truncated_normal([fc_layers[-1], num_classes], stddev=0.1), name="W")
# b_out = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
stdv = 1 / sqrt(weights[-1])
w_out = tf.Variable(tf.random_uniform([fc_layers[-1], num_classes], minval=-stdv, maxval=stdv),
dtype='float32', name='W')
b_out = tf.Variable(tf.random_uniform(shape=[num_classes], minval=-stdv, maxval=stdv), name='b')
self.y_pred = tf.nn.xw_plus_b(self.x_flat, w_out, b_out, name="y_pred")
self.predictions = tf.argmax(self.y_pred, 1, name="predictions")
# CalculateMean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.y_pred, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
训练过程
训练的代码(training.py)中,大部分都是为了存储变量,在tensorboard中可视化而写的代码,因此有很多和之前代码重复的部分。代码中也有注释:
# coding=utf-8
import tensorflow as tf
from data_helper import Dataset
import time
import os
from tensorflow.python import debug as tf_debug
from charCNN import CharCNN
from char_cnn import CharConvNet
import datetime
from config import config
# Load data
print("正在载入数据...")
# 函数dataset_read:输入文件名,返回训练集,测试集标签
# 注:embedding_w大小为vocabulary_size × embedding_size
train_data = Dataset(config.train_data_source)
dev_data = Dataset(config.dev_data_source)
train_data.dataset_read()
dev_data.dataset_read()
print "得到120000维的doc_train,label_train"
print "得到9600维的doc_dev, label_train"
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False)
sess = tf.Session(config=session_conf)
# sess = tf_debug.LocalCLIDebugWrapperSession(sess)
with sess.as_default():
cnn = CharCNN(
l0=config.l0,
num_classes=config.nums_classes,
conv_layers=config.model.conv_layers,
fc_layers=config.model.fc_layers,
l2_reg_lambda=0)
# cnn = CharConvNet()
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(config.model.learning_rate)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables())
# Initialize all variables
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: config.model.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
print "初始化完毕,开始训练"
for i in range(config.training.epoches):
batch_train = train_data.next_batch()
# 训练模型
train_step(batch_train[0], batch_train[1])
current_step = tf.train.global_step(sess, global_step)
# train_step.run(feed_dict={x: batch_train[0], y_actual: batch_train[1], keep_prob: 0.5})
# 对结果进行记录
if current_step % config.training.evaluate_every == 0:
print("\nEvaluation:")
dev_step(dev_data.doc_image, dev_data.label_image, writer=dev_summary_writer)
print("")
if current_step % config.training.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
经过一晚上的训练,差不多达到和论文中相似的结果,训练集能达到96%的正确率,测试集能达到87%的正确率,结果还是好的。但是,跑之前将dropout的概率设为了1,并且没有加正则化约束,所以可以看到在差不多七千多步出现了严重的过拟合。这也可以看作是经验的一部分,在github上传代码中config文件里已经作了修改。
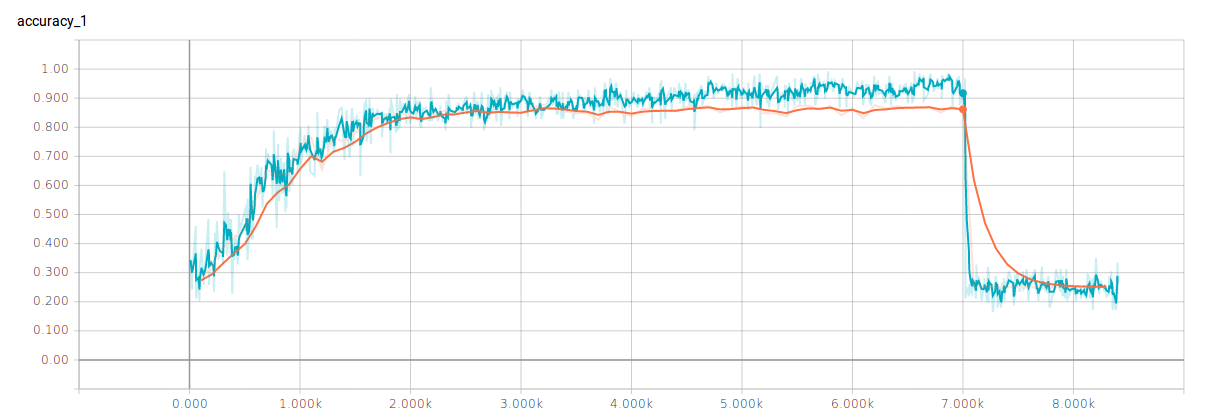
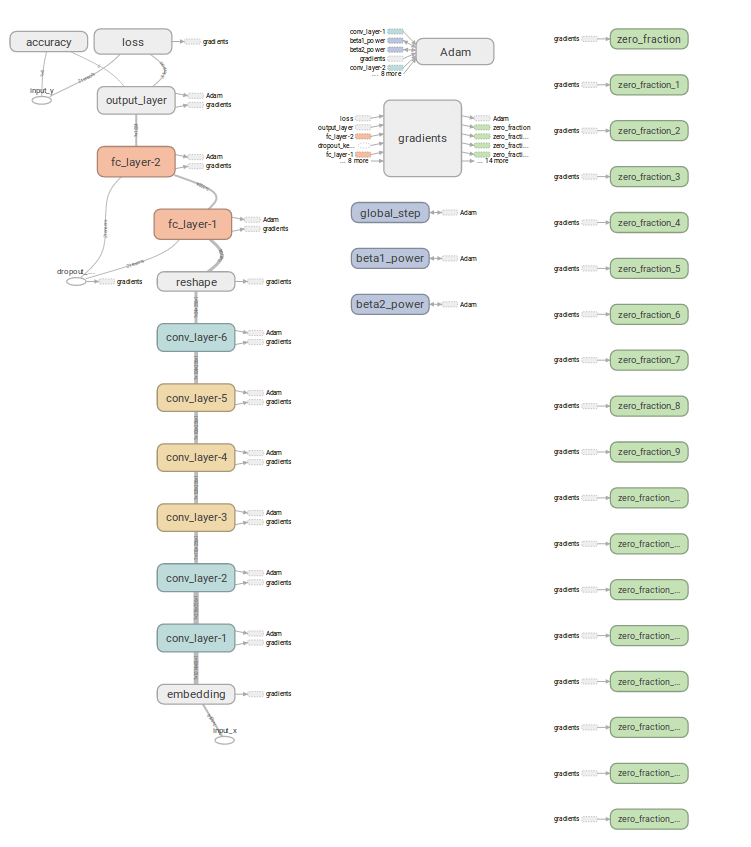
神经网络的图为:
一点想法
在模型的文件cnnModle.py中,最开始我使用的初始化方式为高斯模型,后来换了一种根值定义方差的初始化方式,这两种方式都没办法收敛,我就一直在焦头烂额的找到底问题出在了哪里,这个占据了我剩余的50%的时间。后来一行一行的找完之后,发现是在卷积完以后,我直接加了relu的激活函数,然后再进行池化。
无法收敛:
conv = tf.nn.conv2d(
self.x_flat,
w_conv,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv"
)
h_conv = tf.nn.relu(tf.nn.bias_add(conv, b_conv))可以收敛:
conv = tf.nn.conv2d(
self.x_flat,
w_conv,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv"
)
h_conv = tf.nn.bias_add(conv, b_conv)可能是出于惯性,只要有bias_add函数出现的地方我就会想着加激活,但是这里是不能加的。我猜想,因为权重初始化是有正有负的,卷积完加relu,对于负区域影响较大,导致求导的梯度下降很慢,所以收敛会很难。当然这是我猜想的结果。有大神看到这里可以讲一下,你们卷积之后池化之前加过激活函数吗?效果怎么样?为什么我这里加了relu之后会不能收敛?
谢谢。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









