







题目:稀疏表示与匹配追踪
如果研究压缩感知重构算法,那么匹配追踪绝对是一个绕不过去的概念,虽然最原始的匹配追踪算法应用于重构的文献并不多,但基于匹配追踪改进后的正交匹配追踪算法在研究压缩感知的人群中可以说是家喻户晓、人尽皆知的。既然匹配追踪是与重构有关的,为什么本篇取名为《稀疏表示与匹配追踪》呢?一个重构算法与稀疏表示有什么关系?一般文献中讲到匹配追踪所引参考文献均为文献[1],而文献[1]就是在讲解基于匹配追踪算法的信号稀疏表示问题,这到底是怎么回事呢?(我想一个没有做过稀疏表示的人直接来学习研究压缩感知应该会有此问吧,比如说本人)。以下思路参考或直接引用了文献[2]中的内容。
在前面的“压缩感知稀疏基之XXX”系列博文里,实际是介绍了多种正交变换,给出了每一种正交变换的正交变换矩阵(正交基)。然而用正交基稀疏表达一个信号也有很多缺点,因为一组基表达信号的能力取决于信号的特征是否与基向量的特征相吻合;例如,光滑连续信号可以被傅里叶基稀疏的表达,但脉冲信号就不行;再如,带有孤立不连续点的平滑信号可以被小波基稀疏表达,但小波基在表达傅里叶频谱中有窄带高频支撑的信号时却是无效的。现实世界中的信号经常包含有用单一基所不能表达的特征。对于这些信号,你或许希望可以选择来自不同基的向量(如用小波基和傅里叶基来联合表达一个信号)。因为你想保证你可以表达一个信号空间的所有信号向量,所以由所有可选向量组成的字典应该能够张成这个信号空间。然而由于这组字典中的向量来自不同的基,它们可能不是线性独立的。由于这组字典中的向量不是线性独立的,会造成用这组字典做信号表达时系数不唯一。然而如果创建一组冗余字典,你就可以把你的信号展开在一组可以适应各种时频或时间-尺度特性的向量上。这样构造的字典可以极大地增加你稀疏表达各种特性信号的能力。
例如三维空间中有基向量vx=(1,0,0),vy=(0,1,0),vz=(0,0,1),三维空间中的任意向量均可由三个基向量唯一表示,如v1=(1,2,3)= vx+2 vy +3 vz。然而若取三维空间的一组冗余字典va=(1,1,1),vb=(1,1,2),vc=(2,1,1),vd=(1,2,4),这时若用这四个向量表示v1则有无穷多种表示方法,如v1=2va+ vb-vc或v1=va-vb + vd。当然,这个用矩阵的方法理解更容易,第一种情况求系数是三个独立的方程三个未知数,解唯一;第二种情况是三个方程四个未知数,必然有无穷多解。问题来了,既然在冗余字典里信号表达时的系数不唯一,那么是否存在一种最好的表达方式呢?
定义表达你的信号空间的归一化基本模块作为字典。这些归一化向量叫做原子。如果字典的原子张成了整个信号空间,那么字典就是完全的。如果有原子之间线性相关,那么字典就是冗余的。在大多数匹配追踪的应用中,字典都是完全且冗余的。
假设{φk}表示字典的原子。假设字典是完全且冗余的。使用字典的线性组合表达信号将是不唯一的。
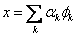
一个重要的问题是是否存在一种最好的表达方式,一种直观的最好方式是选择φk使得近似信号和原始信号有最大的内积,如最好的φk满足
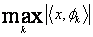
即对于正交原子,为投影到由φk张成的子空间上的幅值。匹配追踪的中心问题是你如何选择信号在字典中最优的M个展开项。
用Φ={φk}表示一个原子归一化的字典,x表示信号。匹配追踪算法流程如下:
(1)首先初始化残差e0=x;
(2)匹配追踪的第一步是从字典中找到与e0的内积绝对值最大的原子,表示为φ1;
(3)通过从e0减去其在φ1所张成空间上的正交投影得到残差e1;
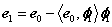
其中<e0, φ1>表示e0与φ1的内积。由于已经说明Φ为原子归一化的字典,即φ1为单位列向量,所以e0在φ1所张成空间上的正交投影可以表示为<e0, φ1>φ1 (由于为一个向量,所以e0在φ1所张成空间上的正交投影即为e0在φ1方向上的正交投影分量),若φ1不是单位列向量,则e0在φ1方向上的正交投影分量为<e0, φ1>φ1/(φ1Tφ1),其中上标T表示转置。
(4)对残差迭代执行(2)、(3)步;
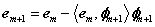
其中φm+1是从字典中找到与em的内积绝对值最大的原子。
(5)直到达到某个指定的停止准则后停止算法。
第(4)步对应到文献[1]中为文献中的式(12):
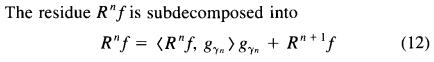
这里要从数学上说明一点:由于内积<em, φm+1>实际上为一个数(标量),所以
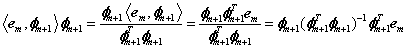
若令P=φm+1 (φTm+1φm+1)-1φTm+1 ,则第(4)步的迭代公式为
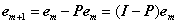
注意矩阵P每次迭代都是不同的。
在匹配追踪(MP)中,字典原子不是相互正交的向量。因此上面减去投影计算残差的过程中会再次引入与前面使用的原子不正交的成分。
为了更形象的看出这点,下面的例子非常清晰地展现了每一个细节(这是一个类比,不代表匹配追踪过程)。考虑欧几里得二维空间的归一化框架字典
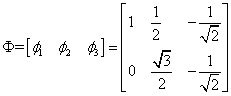
假设有如下信号
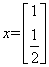
这个例子如图所示,字典原子以红色表示,信号向量蓝色表示
在matlab中如下创建此字典和信号:
dictionary = [1 0; 1/2 sqrt(3)/2;-1/sqrt(2) -1/sqrt(2)]';
x = [1 1/2]';
计算信号和字典原子的内积:
scalarproducts = dictionary'*x输出为:
scalarproducts =
1.0000
0.9330
-1.0607
内积绝对值最大的是第3个原子[-1/sqrt(2); -1/sqrt(2)]。这也很容易理解,因为两者之间的夹角约为π。从信号中减去信号在此原子上的正交投影得到残差:
residual = x-scalarproducts(3)*dictionary(:,3)residual =
0.2500
-0.2500
可以验证此时residual与原子[-1/sqrt(2); -1/sqrt(2)]正交。再次计算信号和字典原子的内积:
scalarproducts = dictionary'*x输出为:
scalarproducts =
0.2500
-0.0915
-0.0000residual = residual-scalarproducts(1)*dictionary(:,1) 输出为:
residual =
0
-0.2500可以验证此时residual与第1个原子[1;0]正交。再次计算信号和字典原子的内积:
scalarproducts = dictionary'*x输出为:
scalarproducts =
0
-0.2165
0.1768第一个值为0,这也说明residual与第1个原子[1;0]正交;但同时也应当注意到第3个值不再为零,也就是说此时residual与第3个原子[-1/sqrt(2);-1/sqrt(2)]不再正交,这意味着这个原子有可能被再次选择到。这个事实及与收敛相关的问题在正交匹配追踪中得以解决。现在内积绝对值最大的是第2个原子[1/2;sqrt(3)/2](内积值为-0.2165)。从信号中减去信号在此原子上的正交投影得到残差:
residual = residual-scalarproducts(2)*dictionary(:,2)输出为:
residual =
0.1083
-0.0625 到这里可能你会发现一个问题:三个原子都选择了一遍,但现在的residual仍然不为零;而二维空间中任意两个线性无关的二维向量即可生成整个二维空间,在这个例子中,三个列向量(原子)两两都是线性无关的,即我们要稀疏表达的信号x实际上可以由三个原子中任意两个的线性组合表示。将三个原子中的任意两个再加上信号x组合一个矩阵,用Matlab函数rref将矩阵化简为行阶梯最简形(Reduced row echelon form):
rref([dictionary(:,1) dictionary(:,2) x])
rref([dictionary(:,1) dictionary(:,3) x])
rref([dictionary(:,2) dictionary(:,3) x]) 三行代码的输出分别为:
ans =
1.0000 0 0.7113
0 1.0000 0.5774
ans =
1.0000 0 0.5000
0 1.0000 -0.7071
ans =
1.0000 0 -1.3660
0 1.0000 -2.3801由以上输出可以知道用其中任意两个原子表示x时的组合系数。下面把上面所有程序给出:
dictionary = [1 0; 1/2 sqrt(3)/2;-1/sqrt(2) -1/sqrt(2)]';
x = [1 1/2]';
scalarproducts = dictionary'*x
residual = x-scalarproducts(3)*dictionary(:,3)
scalarproducts = dictionary'*residual
residual = residual-scalarproducts(1)*dictionary(:,1)
scalarproducts = dictionary'*residual
residual = residual-scalarproducts(2)*dictionary(:,2)
rref([dictionary(:,1) dictionary(:,2) x])
rref([dictionary(:,1) dictionary(:,3) x])
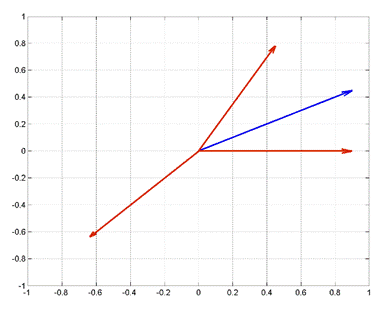
rref([dictionary(:,2) dictionary(:,3) x]) 虽然所有3个原子均选择了一遍后残差仍不为零,但如果继续迭代,残差将会越来越小,程序如下(以下迭代5*N=5*3=15次):
dictionary = [1 0; 1/2 sqrt(3)/2;-1/sqrt(2) -1/sqrt(2)]';
x = [1 1/2]';
[M,N] = size(dictionary);
residual = zeros(M,5*N+1);%残差矩阵,保存每次迭代后的残差
residual(:,1) = x;%初始化残差为x
L = size(residual,2);%得到残差矩阵的列
pos_mm = zeros(1,L);%用来保存每次选择的列序号
resi_norm = zeros(1,L);%用来保存每次迭代后的残差的2范数
resi_norm(1) = norm(x);%因为前面已初始化残差为x
for mm = 1:length(residual)
%求出dictionary每列与上次残差的内积
scalarproducts = dictionary'*residual(:,mm);
%找到内积中最大的列及其内积值
[val,pos] = max(abs(scalarproducts));
%更新残差
residual(:,mm+1) = residual(:,mm) - ...
scalarproducts(pos)*dictionary(:,pos);
%计算残差的2范数(平方和再开根号)
resi_norm(mm+1) = norm(residual(:,mm+1));
%保存选择的列序号
pos_mm(mm+1) = pos;
end
%绘出残差的2范数曲线
plot(resi_norm);grid;
将pos_mm输出:pos_mm=[0 3 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1],从第4次往后,交替选择第1个原子和第2个原子。有关采用匹配追踪算法在冗余字典中稀疏表达实际的信号可参见参考文献[3]。
在正交匹配追踪OMP中,残差是总与已经选择过的原子正交的。这意味着一个原子不会被选择两次,结果会在有限的几步收敛。OMP的算法如下
(1)用x表示你的信号,初始化残差e0=x;
(2)选择与e0内积绝对值最大的原子,表示为φ1;
(3)将选择的原子作为列组成矩阵Φt,定义Φt列空间的正交投影算子为
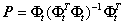
通过从e0减去其在Φt所张成空间上的正交投影得到残差e1;
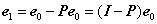
(4)对残差迭代执行(2)、(3)步;
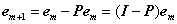
其中I为单位阵。需要注意的是在迭代过程中Φt为所有被选择过的原子组成的矩阵,因此每次都是不同的,所以由它生成的正交投影算子矩阵P每次都是不同的。有关正交投影的概念可以参见《压缩感知中的数学知识:投影矩阵(projectionmatrix)》。
(5)直到达到某个指定的停止准则后停止算法。
可以看出OMP与MP的不同根本在于残差更新过程:OMP减去的Pem是em在所有被选择过的原子组成的矩阵Φt所张成空间上的正交投影,而MP减去的Pem是em在本次被选择的原子φm所张成空间上的正交投影。基于此,OMP可以保证已经选择过的原子不会再被选择。有关正交匹配追踪的进一步分析见下一篇《施密特(Schimidt)正交化与正交匹配追踪》,有关究竟为什么把稀疏表示与匹配追踪放在一起参见下下篇《正交匹配追踪(OMP)在稀疏分解与压缩感知重构中的异同》。
推荐一篇有关匹配追踪与正交匹配追踪的详细分析博文,参见文献[4],写的很不错。
【1】S Mallat, Z Zhang. Matchingpursuit with time-frequency dictionaries[J]. IEEE Transactions on SignalProcessing, 1993, 41(12): 3397-3415.
【2】了凡春秋. Matlab匹配追踪(Matching Pursuit) 之一,https://chunqiu.blog.ustc.edu.cn/
【3】了凡春秋. Matlab匹配追踪(Matching Pursuit) 之二,https://chunqiu.blog.ustc.edu.cn/
【4】逍遥剑客. MP算法和OMP算法及其思想,http://blog.csdn.net/scucj/article/details/7467955

















 2816
2816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









