










论文题目:Lifelong aspect extraction from big data knowledge engineering
论文地址:http://casmodeling.springeropen.com/articles/10.1186/s40294-016-0018-7
论文大体内容:
本文通过调查、分析现有的基于知识库的主题模型,对比彼此的相同与不同,并分析各自的缺点,以及在不同任务需求下的挑战。
1、概率主题模型是依赖于词的共现度来确定哪些词属于同一主题下,而在aspect级别(细粒度)观点挖掘下,由于aspect观点词在同一个文档下的出现率低,会导致现有的概率主题模型不能很好地挖掘出aspect级别的主题词。(P.S. 目前比较好的aspect level sentiment mining模型有LAST[1],该模型的说明可以看之前的一篇博文[2])
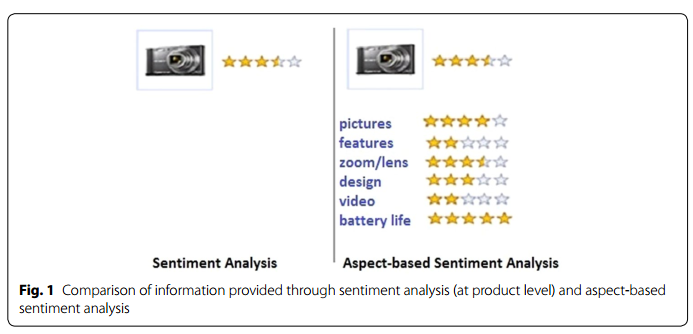
2、对文本进行aspect级别挖掘是为了能够发现更多有用的信息,如下图。粗粒度看一个相机(商品),只能知道它是多少分,但通过细粒度挖掘,能够知道在设计、电池寿命、拍照、录像等方面的表现。
3、对于现在商品的big data,如商品评论,里面有大量主观的、不太正式的标注(包括语法错误、俚语、词语缩写等),会对aspect抽取模型造成很不好的结果。
4、aspect抽取面临的问题是:如何利用无监督的数据,进行更有效地进行aspect抽取。
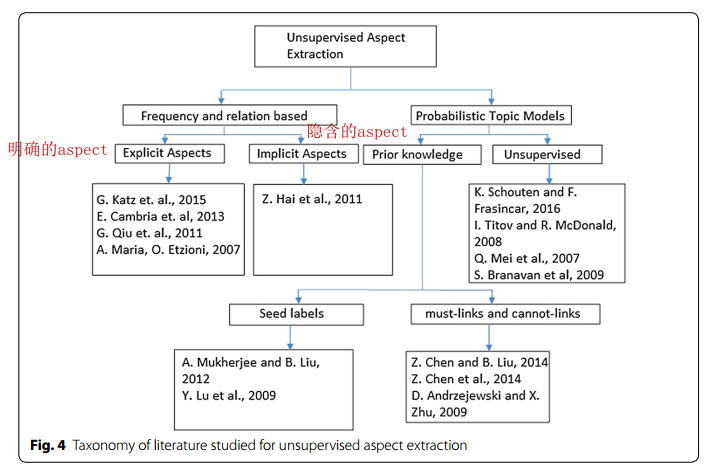
5、前人的一些研究方向如下图。包括以下几个方面:
①基于出现频率与关系的技术,包括抽取显式aspect和隐式aspect。主要思想是生成一个候选aspect集合,根据出现频率进行过滤、选择aspect。(非监督的)
②基于概率主题模型的,包括基于非监督主题模型和利用先验知识进行改进。其中先验知识包括Lifelong Machine Learning中使用的must-link和cannot-link。
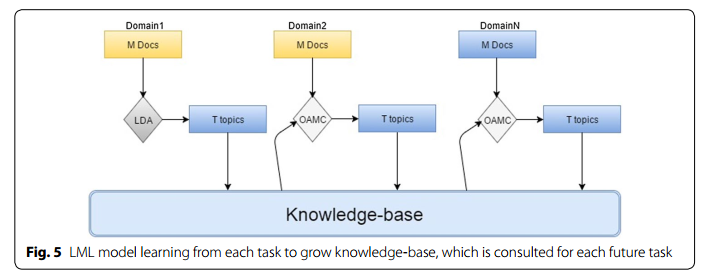
6、Lifelong Machine Learning的Online版OAMC[3]的大体框架如下图。
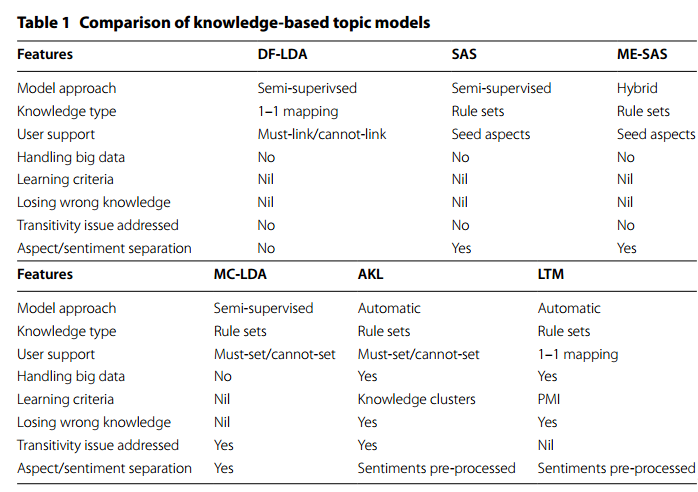
7、几种使用了知识库的模型的对比如下图。
8、Lifelong Machine Learning可以应用到层次主题模型,但需要对学习和知识迁移的算法改进一下;也可以应用到流数据。
参考资料:
[1]、http://dl.acm.org/citation.cfm?id=2883086
[2]、http://blog.csdn.net/john159151/article/details/52750351
[3]、https://www.hindawi.com/journals/cin/2016/6081804/abs/
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









