








原文教程:tensorflow官方教程
翻译教程:极客学院
记录关键内容与学习感受。未完待续。。
面向机器初学者的MNIST教程(MNIST For ML Beginners)
—–适用于对机器学习和tensorflow初学者。而这里MNIST就好比学语言时候的打印hello world。
—–MNIST是一个简单的计算机视觉数据集,它包括各种手写数字的图像,比如:

—–它也包含每张图像对应的标签,告诉我们这是哪个数字,上面四张图像的标签分别是5、0、4、1。
—–在本教程中,我们训练一个模型观察图像来预测这个数字是多少。我们的目标并不是训练一个真正复杂的模型,这个模型可以实现最先进性能。尽管后面我们会给你源代码去实现这件事,但是我们主要是介绍如何使用tensorflow。所以,我们会从一个简单的数学模型学起,softmax regression。
—–对应于这个教程的实际代码非常短,所有有意思的内容只在三行代码中。然后去理解这些代码背后的意义是十分重要的,包括tensorflow是如何运作,机器学习核心概念。因为,本教程会详细介绍这些代码。
1、关于教程
——你可以以下面几种不同的方法使用这篇教程。
- 每读一行解释,就在Python环境中复制粘贴一行代码。
- 在阅读解释前或者后,运行这个mnist_softmax.py的Python文件,并使用这个教程来理解你不明白的那几行代码。
—–我们在篇教程中完成:
- 学习MNIST数据集和softmax regression。
- 基于观察图像中的每个像素,创建一个函数,也就是这个模型来识别数字。
- 使用tensorflow,通过“看”成千上万的例子,训练这个模型来识别数字。
- 利用测试数据检查模型的精确度。
2、MNIST数据集
—–MNIST数据由Yann LeCun’s website提供。你可以将这两行代码复制粘贴到你的代码中,或者下载数据集,然后运行这两行代码,就会自动下载和读取这个数据集。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)—–写到这里,为了运行这两段代码,可谓出了各种错误。AttributeError: ‘module’ object has no attribute ‘_base’,大坑。如下:


—–起初以为是路径不对的原因,修改如下:

—–竟然出现语法错误。继续修改,还不行:
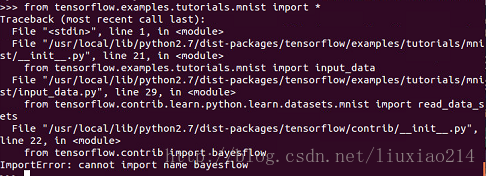
—–继续修改,还是不行,已崩溃,先不管。

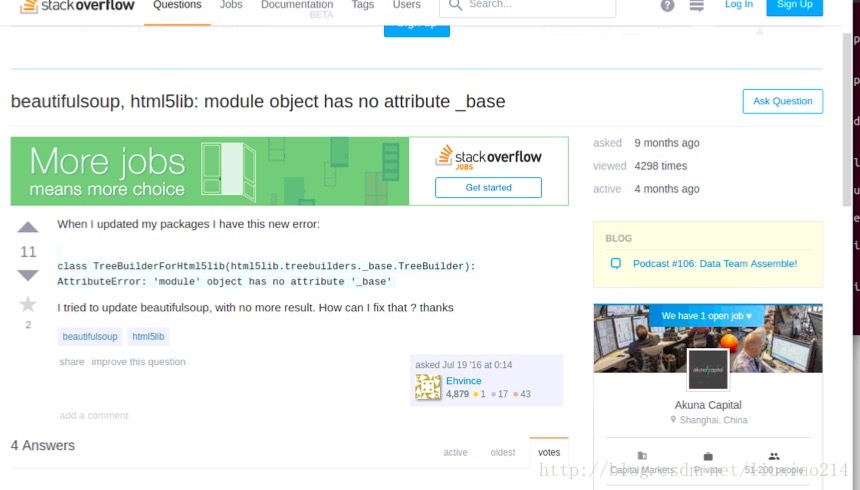
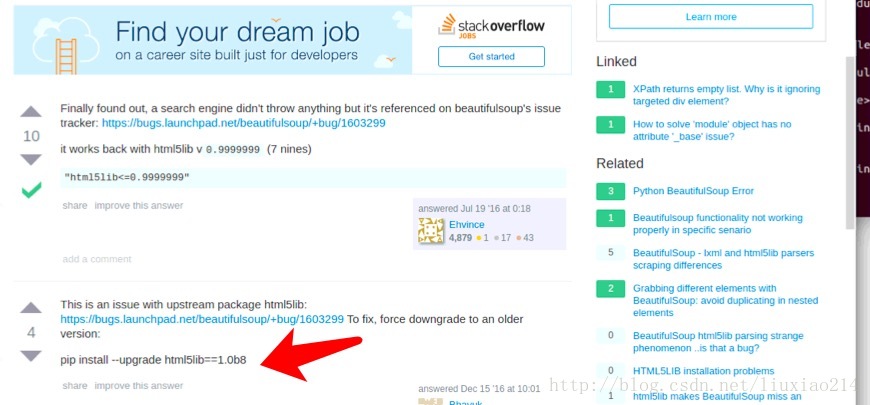
—–最后问题解决,当第一次出现错误时,就提醒了是“调用这个html5lib的一个模块的时候,没找到_base”,于是升级html5 Python lib 库,结果还是不行,最后发现有人遇到过着这个问题,需要降级为1.08b,终于解决了,折腾过程如下:
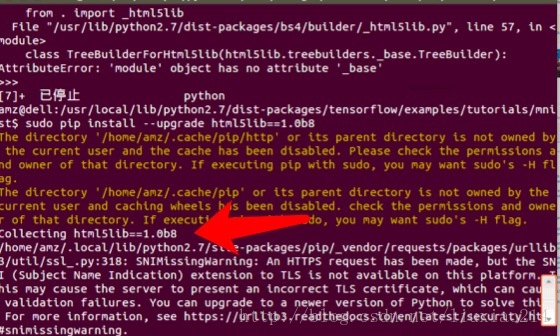

—–模块导入终于成功了,第二句代码,又又又出错了。IOError: [Errno socket error] [Errno110][Connecton timed out]如下:
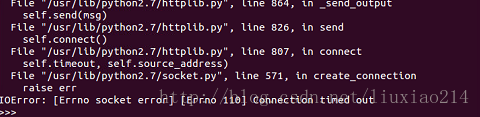
—–这时不要怕,外国网站嘛,总有那么几次连不上,多试几次,就可以了。成功结果如下:
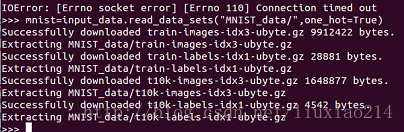
—–这个数据集分成三部分,55000个数据点用来训练数据(mnist.train),10000个点用来测试数据(mnist.test),5000个点用来验证数据(mnist.validation),这种切分很重要:这在机器学习中很有效率,我们分开我们不需要学习的数据,这样确保我们真正学到了泛化。
—–正如前面提到的,每个MNIST数据点有两个部分,一个手写数字的图像和与之相关的标签,我们可以称图像为x,标签为y。训练集和测试集都包含了图像和与之相关的标签,例如训练集的图像是mnist.train.images,训练标签是mnist.train.labels。
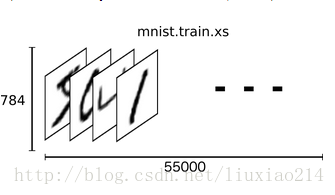
—–每张图像都是28x28像素的,我们可以用一个数字数组来表示这张图像。
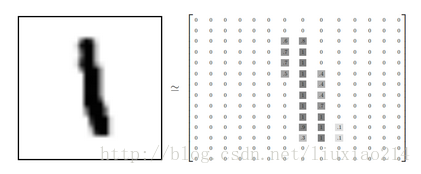
—–我们把这个数组展开成一个向量,长度是28x28=784。如何展开这个数组并不重要,只要保持每个图像展开的方式一样就可以。从这个角度看,MNIST图像就是784维向量空间中的一堆点,并且有比较复杂的结构。(警告:计算密集型可视化)
—–展开图像数字数组会丢失图像二维结构的信息,这显然不好,最好的计算机视觉方法挖掘并利用这些信息,我们会在稍后的教程中提到。但是,我们在这里用的简单的方法,softmax regression(后面会给出定义),不会利用这些结构信息。
—–在MNIST训练数据集上,mnist.train.images是一个形状为[55000,784]的tensor(一个n维数组)。第一个维度是用来索引图像列表中图像的位置,第二个维度是索引每个图像中的每个像素点。在这个tensor中的每个元素,表示某个某图像中的某个像素点的强度值,在0和1之间。
—–在MNIST中的每个图像都有一个与之对应的标签,用0到9的数字描述图像中代表的数字。
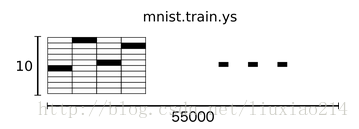
—–为了用于这个教程,我们希望我们的标签都是one-hot vectors形式的,一个one-hot向量除了某一个维度是1以外,其他维度都是0。所以在这种情况下,数字n表示成一个只有在第n维度(从0开始)数字为1的10维向量。例如,数字3的向量表示为[0,0,1,0,0,0,0,0,0,0]。因此,mnist.train.labels是一个 [55000, 10]的数字矩阵。
—–现在,我们开始真正构造我们的模型。
3、softmax回归
—–我们知道MNIST中的每个图像都是0到9之间的一个手写数字,因此给定一个图像,只有10中可能性。我们希望做到的是,看到一张图像,我们给出是每个数字的可能性大小。例如,我们的模型可能看到一张手写数字是9的图像,有80%的概率确定它是9,有5%的概率确定它是8(因为8和9都有相同的上半部分:小圈),然后是给更小的概率确定它是其他数字。
—–这是使用softmax regression(一个自然简单的模型)一个经典的案例。如果你想给一个对象假定是其他几个不同事物的概率,softmax模型就可以做到,因为softmax给我们一个0到1之间的值的列表,这些值加起来刚好是1。即使是后面我们训练更为复杂的模型时,最后一层也是用到了softmax层。
—–softmax regression分为两步:第一步我们把我们的输入图像是某个特定数字类别的证据加起来,第二步将这个证据转化成概率。
—–首先第一步,为了得到给定一张图像是某个特定数字类别的证据,对每个像素值进行加权求和,如果这个像素有很高的强度说明这个图像不属于该类,则这个权值是负数,相反,如果这个像素能够有力地证明这个图像属于该类,则权值为正数。
—–下面的图片展示了模型学习到的每一个像素对应特定数字类的权值。红色代表负数权值,蓝色代表正数权值。

—–我们也添加了一些额外的证据称之为偏置值(bias),基本上,我们是想有能力说,有些事情是更独立于输入的,即输入往往会带有一些干扰量。对于给定输入图像x,它是数字类别i的证据结果是:
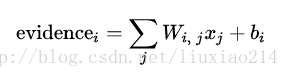
—–在这里,Wi表示类i的权值,bi表示类i的偏置值,j表示对给定输入图像x的像素求和的索引,然后我们利用softmax函数将这个证据转换成我们预测的概率y:
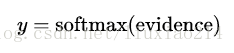
—–在这里softmax可以看做成一个激励函数或者连接函数,把我们线性函数的输出转化成我们想要的形式,也就是关于10个数字类的概率分布。你可以这样想,将证据转化成我们的输入是某个数字类的概率。这个softmax函数这样定义:
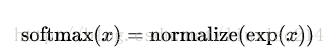
—–如果你展开等式右边的式子,你可以得到:
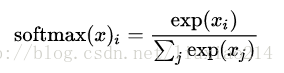
—–但是把softmax定义成前一种形式更有用:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应于更大的假设模型里面的乘数权重值。反之,拥有更少的证据表示假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0和负数。接着,softmax正则化这些权值,使他们加起来是1,构造一个有效的概率分布。
—–你可以用下面的图来理解softmax regression。对于大量的输入x,对x进行加权求值,再加上偏置值,得到的输出作为softmax函数的输入:
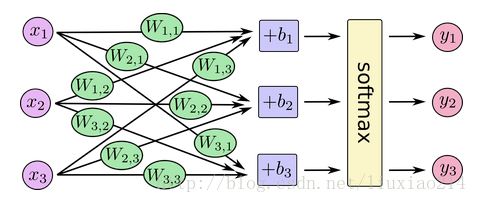
—–如果我们把它写成一个等式,我们会得到:
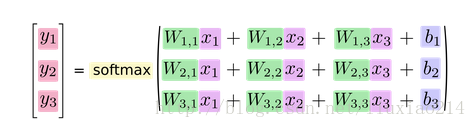
—–我们可以向量化这个过程,用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)
—–更进一步,我们可以写成:
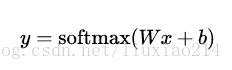
—–现在,把这些转换成tensorflow可以使用的东西。
4、实现回归
—–为了在Python中做更有效的数字计算,我们经常会使用函数库,如NumPy,来做一些复杂的操作,如使用非Python语言用更有效的代码来计算矩阵乘法。不幸的是,从外部运算切换回Python仍然是一个巨大的开销。如果你想用GPU计算,开销会更大,如果使用分布式计算,也会花费大量资源传输数据。
—–tensorflow把复杂的计算放在Python之外来完成,为了避免前面所说的开销也做了进一步的改善。并不是在Python之外单独运行单一复杂的操作,tensorflow先让我们用图来描述一系列可交互的操作,然后最后全部一起在Python之外运行。(这种类似的运作方式在不少机器学习库中可以看到)
—–为了使用tensorflow,首先我们需要导入它,如下:
import tensorflow as tf—–我们通过操作符号变量来描述这些可交互操作,例如,创建一个:
x = tf.placeholder(tf.float32,[None,784])—–x不是一个特定的值,而是一个占位符placeholder,当我们用tensorflow计算时我们来输入这个值。我们希望可以输入任意数量的MNIST图像,每一个图都被展开成784维的向量。我们用2维的浮点数tensor来表示这些图,这个tensor的形状是[None, 784]。(Node表示这个tensor的第一个维度可以是任意长度)
—–我们的模型也需要权重和偏置值,我们可以想象,把训练这些当成额外的输入,但是tensorflow有更好的办法去处理它:Variable。一个Variable代表一个可修饰的tensor,存在于tensorflow中用于描绘可交互操作的图中。在计算中可以被使用,甚至被修改。在机器学习应用中,一般会有的模型参数就是Variables。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))—–我们想通过tf.Variables赋予Variable不用的初值来创建不同的Variables:在这种情况下,我们用全为0的tensor来初始化W和b。因为我们还要学习W和b,所以如何初始化它们是无关紧要的。
—–注意到W的形状是[784, 10],这是因为我们想要用784维的图像向量来乘以它以得到一个10维的证据向量,每一维对应不同的类别。b的形状是[10],因此我们可以直接将他加在输出上。
—–现在我们可以实现这个模型了,用下面的一行代码:
y = tf.nn.softmax(tf.matmul(x,w)+b)—–首先我们用tf.matmul(x,w)来表示将x与W乘起来。对应于之前方程式中的乘法Wx,这里的x是一个拥有多个输入的2维tensor。我们接着再加上b把它应用到tf.nn.softmax中。
—–至此,我们只用了一行代码来定义模型,几行代码来设置变量。这是因为tensorflow的设计不仅使得softmax regression变得特别简单,而且使用特别灵活的方式来描述其他各种类别的数值运算,从机器学习模型到物理仿真模型。一旦被定义好,我们的模型就可以在不同的设备上运行:计算机的GPU,CPU,甚至是手机。
5、训练
—–为了训练我们的模型,我们需要定义一个指标来表示模型的好坏。实际上,在机器学习中,这个指标称之为cost或者loss,这代表着我们的模型离理想输出差距有多远。我们要尽力最小化这个error,error矩阵越小,模型就越好。
—–一个定义模型loss非常常见,非常好的函数就是交叉熵(cross-entropy)。交叉熵产生于信息论中的信息压缩编码技术,但后来成为从博弈论到机器学习很多领域中的重要技术手段,它定义为:
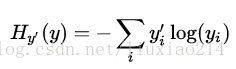
—–其中y就是我们预测的概率分布,y’是真正的分布(带有数字标签的one-hot向量)。比较粗糙的理解起来,交叉熵是用来衡量我们的预测用于描述真相的低效性。更详细的关于交叉熵的介绍超出本教程,最好参考understanding。
—–为了实现交叉熵,我们需要一个新的占位符来输入正确答案:
y_ = tf.placeholder(tf.float32,[None,10])—–接着,我们需要实现交叉熵函数,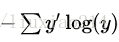
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices=[1]))—–首先,tf.log计算y每个元素的对数,接着我们把y’中的每个元素和tf.log(y)对应的每个元素相乘。然后tf.reduce_sum将y的第二维的每个元素加起来,这是因为reduction_indices=[1]。最后,tf.reduce_mean计算同批次中所有例子的平均值。
—–(注意到源代码中,我们并不用这个计算公式,这是因为用数字表示不稳定,实际上我们用tf.nn.softmax_cross_entropy_with_logits来处理非规格化对数(例如我们调用softmax_cross_entropy_with_logits来处理tf.matmul(x, W) + b)),这是因为用内部计算softmax激励更数字稳定。在你的代码中,考虑使用tf.nn.(sparse_)而不是softmax_cross_entropy_with_logits。)
——现在已经知道我们想要模型做什么,这很容易用tensorflow来训练它。因为tensorflow知道你整个计算图,它可以自动的使用后向传播算法来有效地决定你的variables是如何影响你想要最小化的那个loss。接着tensorflow会采用你选定的优化算法来修改variables以减少loss。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)—–在这种情况下,我们要求tensorflow使用梯度下降法以0.5的学习速率来最下化交叉熵。梯度下降算法是一个简单的算法,tensorflow通过调整variables的方向来最小化损失。但是tensorflow也提供了很多其他优化算法,只要简单的调用一行代码就可以使用其他的算法。
—–tensorflow实际做的是,在后台,它会在你的计算图中添加一些操作用来实现反向传播算法和梯度下降算法。然后它返回给你的只是一个单一的操作,当运行这个操作时,它利用梯度下降训练模型,微调变量来减少损失。
—–现在,我们已经设置好模型来训练。在我们运行之前做的最后一件事,我们必须创建一个操作来初始化之前创建的变量。注意这只是定义操作而不是运行它。
init = tf.global_variables_initializer()—–现在我们在一个会话中运行模型,并且运行初始化变量的操作。
sess = tf.Session()
sess.run(init)—–开始训练模型,我们将循环训练1000次。
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys})—–在循环的每一步中,从我们的训练数据集中随机获取100个批处理数据点,我们用这些数据点来替代之前的占位符作为参数运行train_step。
—–使用一小部分随机数据进行训练称为随机训练,在这里,更确切的说是随机梯度下降训练。理想情况下,我们希望用所有数据来进行每一步训练,因为这样能给我们很好的训练结果,但开销太大了。因此每次我们使用不同的子数据集,这样做可以减少开销,并且最大化地做到一样好。
6、评估模型
—–我们的模型做的怎么样?
—–首先,找出那些我们预测到的正确标签。tf.argmax是一个非常有用的函数,它能给出某个tensor实体在某一维上面数值最大的值的下标也就是索引值。例如,tf.argmax(y,1)是我们的模型认为的对每一个输入最接近的标签,tf.argmax(y_,1)是真正的标签,我们可以用tf.equal来检查我们预测的是否符合事实(由于标签向量就是由0、1构成的,最大值的下标也就是1所在的下标,而1的下标就是标签)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))—–这行代码会给我们一组布尔值,为了确定正确预测项的比例,我们把布尔值转化为浮点数,然后取平均值。例如,[True, False, True, True]将变成[1,0,1,1],平均值是0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))—–最终,在我们测试数据集上获取正确率:
print(sess.run(accuracy,feed_dict={x:mnist.test.images, y_:mnist.test.labels}))—–最终结果应该是大约92%。
—–这是好的吗?事实上,并不是,这非常差。这是因为我们用了一个非常简单的模型。做一些小的改进,我们就可以达到97%。最好的模型可以达到99.7%的准确度(更多信息可以点击list of results)。
—–更重要的是我们从这个模型中学到什么。如果你对这个结果感到失望,下一个教程我们将做的更好,用tensorflow构建更加复杂的模型。
7、实际运行
—–以上,最终实际运行代码和结果如下:
—–第一次尝试:
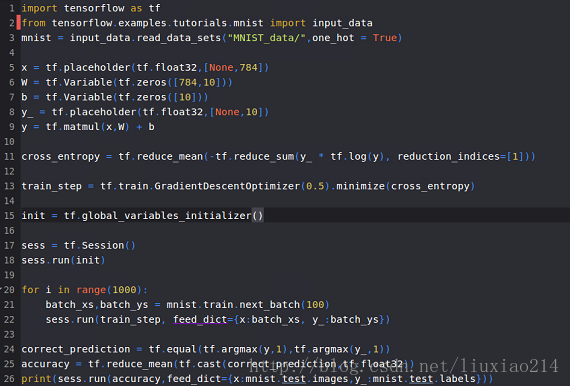
——结果,正确率,呵呵呵:
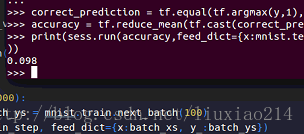
——不敢相信,查看了官网代码后发现,自己用了不稳定的计算交叉熵的方法,要用内部计算函数,于是,改动:
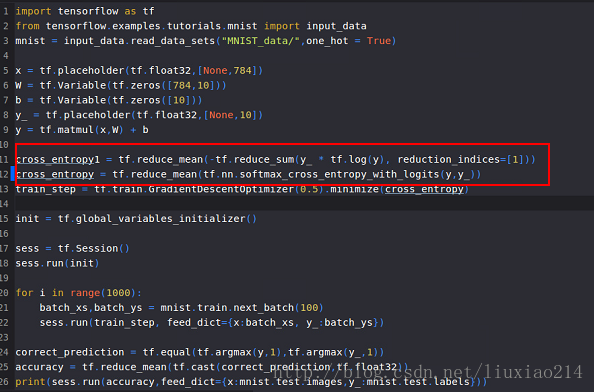
—–这里出现一个问题,ValueError: Only call softmax_cross_entropy_with_logits with named arguments (labels=…, logits=…, …),如下:
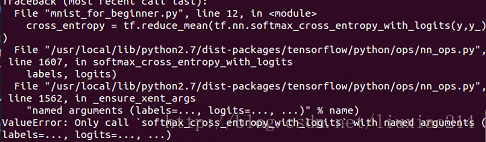
—–这是由于没有指定参数名的原因,改正如下:
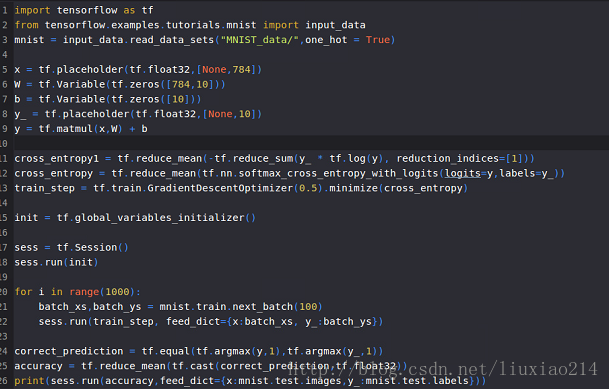
—–最后运行结果:
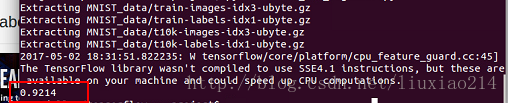
——以上,终于跑完第一个例程。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









