










论文链接:https://arxiv.org/pdf/1811.08362.pdf
这篇论文讨论的是行为识别中的鲁棒性和泛化能力。
论文简要
0、摘要
作者认为,对乱序的帧序列和多变的视频环境,目前的动作识别方法不够鲁棒性和泛化。造成这种问题的原因,作者认为,一是由于传统方法中有着不同输入的多流网络的决策差异问题,二是在交叉数据实验中,作者发现光流特征很难被迁移,这影响了two-stream网路的泛化能力。
对于鲁棒的动作识别,作者提出了Reversed Two-Stream Networks (Rev2Net),它具有3个属性:(1)通过反转多模态输入作为训练监监督,可以学习到可迁移、更鲁棒的视频特征,并且在帧乱序实验和交叉数据实验中,性能超过其他方法;(2)强调一个适应的、合作的多任务方法,可以应用在编码器中,来惩罚他们在深度特征空间中的不一致,称之为 decoding discrepancy penalty (DDP);(3)编码器在测试时会去除掉,Rev2Net在交叉数据实验中取得了最好结果,在经典动作识别中取得可竞争性结果,UCF101:94.6%,HMDB51:71.1%,Kinetics:73.3%,比很多不止用RGB数据的方法要好很多。
1、介绍
介绍就不怎么说了,大意是说目前的这些方法在鲁棒性和泛化能力上存在的不足,因此作者提出了新的方法。如下图的d所示。

这个新的two-stream网络成为Rev2Net,包含一个编码器流,输入是RGB;一个分类器用于动作识别;一个解码器流,用于光流预测;另一个解码器流,用于反转RGB帧的重建。
解码器流是原来的two-stream的反转形式,使用视频帧的不同模态作为自监督信号。
训练时,编码的视频特征送入三个网络分支;测试时,Rev2Net不需要提前计算的光流,只使用原始的RGB数据做决策。
为了防止解码器流对识别任务可能造成的影响,作者在解码器流间加了特征空间不一致的惩罚。这个惩罚可以使他们自适应学习。他们可以通过反向传播相互影响,最后光流和反转RGB达到一个统一的状态,这可能对编码器特征学习有帮助。
这篇论文的贡献有三个:
-
分析了主流动作识别模型对动作依赖和视频场景变换的鲁棒性,进行了长期、短期的帧乱序实验和不同视频域适应实验。
-
提出Rev2Net,使用多任务自监督,有更好的泛化能力。提出解码差异惩罚,称为DDP,可以在不同解码器流中惩罚他们在特征空间的不一致,从来促成一种可适应、合作的多任务学习。
-
Rev2Net在测试时不需要提前计算光流,UCF101:94.6%,HMDB51:71.1%,Kinetics:73.3%。
2、相关工作
不说了
3、Analysis of Robustness to Frames Disorder
在实际场景中,视频帧的到来可能是乱序的,因此要提高这方面的鲁棒性。作者对三种帧序列的打乱进行了实验,每个视频分为一些视频块,
- long-term shuffle: 表示块内帧序列有序,但块之间是乱序的
- short-term shuffle: 表示块内帧序列无序,但是块之间是有序的
- complete shuffle: 整个视频帧序列完全打乱
实验结果如下表所示:

结果分析:
- 对于完全打乱,光流结果比RGB结果损失的更为严重;得出I3D 光流可能更依赖于动作块的潜在特征,鲁棒性更差。
- long-term和short-term相对I3D来说,差别不是特别大。但都有退化。
- 更完整的比较,借用了tsn的实验结果,不讨论long-term shuffle的原因是tsn已经提前对视频分块了。2DCNN模型不能充分利用long-term motion cube。
4、Analysis of Generalization Ability
4.1 Video Action Domain Adaptation
视频领域适应是对模型泛化能力很好的一个考察,在source domain训练,在target domain测试,两个domain分布不一致。
作者对UCF101和HMDB51这两个数据集中共同相关的16个类别做了交叉数据的实验验证。HMDB51数据来源于电影,UCF101来源于YouTube视频,后者更接近真实环境。两者场景复杂度、摄像头角度等都有差异。如下图:

使用tsn和I3D进行实验验证,使用DANN方法来衡量迁移能力。实验结果如下:

结果分析:
- RGB作为输入时,即使2DCNN学习序列间动作依赖性比较差,但I3D和TSN的结果差异不大;
- 无论是I3D还是TSN,RGB的结果比光流的结果要好,因此当融合RGB和flow时,acc并没有太大提升;
- 因此得出,要提高传统two-stream在交叉数据集上的泛化能力,就要提高光流的泛化能力;因此得出,要提高传统two-stream在交叉数据集上的泛化能力,就要提高光流的泛化能力;
- 光流的特征迁移比较差。
4.2 Decision Discrepancy in Two-Stream Networks
光流特征迁移影响了twostream在交叉数据的准确性,RGB与光流之间的差异导致在决策时的不一致。
4.3 A Brief Summary of the Robustness Analysis Regarding Existing Models.
总结上述,
- 无论哪种方式,帧序打乱后,I3D和TSN都出现性能下降,说明在真实场景下会不够鲁棒;
- 在交叉数据,视频域适应的验证实验中,TSN和I3D性能下降都很严重,目前存在的方法没有关注这一方面;
- twostream-3DCNN的分支并不是理想互补的。
5、Reversed Two-Stream Networks
作者提出Reversed Two-Stream Networks (Rev2Net),如下图:
5.1 Reversing Input Signals as Selfsupervisions
在3DCNN的two-stream中,存在RGB和光流的决策差异问题。这个问题在传统two-stream中不是很严重,但在这里问题却比较严重,光流影响了交叉数据验证,因此作者这里,光流只用作训练中,在测试中不使用光流。
作者将光流输入和RGB输入数据都进行反转(这里有个问题,光流到底反转没,这里作者用了both,应该是都,但后面很多描述,包括前面,都只提了RGB反转,没说过光流反转),作为自监督,称为Reversed Two-Stream Network (Rev2Net) 。

Rev2Net有4个组成成分:一个以RGB为输入数据的编码器流,一个动作识别的分类器,一个用于光流预测的解码器流,一个用于反转的RGB帧重构的解码器流。
说明:
- 编码器在连续帧序列上操作,沿着分类器,它与I3D有同样的结构。
- 两个解码器流都是由3D transpose convolutions组成,只在训练时使用,测试时不使用。
- 光流解码器使用相对应的光流场作为监督,旨在学习短动作特征和前景外观特征。
- 帧解码器旨在学习长动作特征,通过编码3D特征来逆序重构输入帧。
正式由于两个解码器可以使得Rev2Net同时学习到长短动作特征,提高了帧乱序时的鲁棒性。另一方面,使用光流作为自监督信号,对视频决策少了干扰,减少了视频域转换的损失。因此,Rev2Net有更强的鲁棒性和泛化能力。
5.2 Decoding Discrepancy Penalty
传统的two-stream网络在交叉数据验证时会出现决策不一致的问题,Rev2Net为了避免这一问题,只采用RGB进行编码,反转的(到底是光流也反转了吗?)光流和RGB作为自监督信号,但仍然有两个解码器在特征学习时的不一致问题。尽管光流预测任务和重建反转帧任务将促使编码器学习输入帧不同的部分,但在训练编码器时他们并没有相同的作用。
因此,作者定义了一个新的目标函数,来惩罚这个不一致问题,称为Decoding Discrepancy Penalty(DDP),提供两种不同形式的DDP,以及与之相对应的网络结构。
Frobenius Norm and Low-Level Features.
F范数相关解释:https://blog.csdn.net/lthirdonel/article/details/80920199
如图3网络结构中所示,解码器是连接在编码器的低层feature map上,编码器和解码器都只有几层卷积层,因此,会用F范数来惩罚两个解码器在低层特征空间之间的距离。
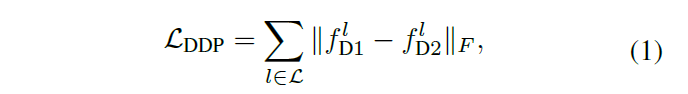
其中,||.||是F范数,L是DDP中的卷积层集合,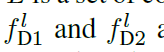 分别是在l卷积层两个解码器的低层feature map。
分别是在l卷积层两个解码器的低层feature map。
在光流解码器中,有两个TransposeConv3D层,在反向传播中,帧解码器的三个加上Conv3D层。这两个解码器都接在了原始I3D网路的Conv3d 2c层之后,16 x 56 x 56作为输入shape。作者这里并不希望解码器特别强,因为需要训练一个好的编码器。
KL Divergence and High-Level Features.
KL Divergence :KL散度,也就是相对熵,有关解释链接:https://blog.csdn.net/weixin_37136725/article/details/53906141
为了减轻高层特征学习的不一致问题,可以通过分配更多层给编码器以及相对应的解码部分。编码器的输出有三部分,作为分类器输入的特征,用来光流预测的高斯分布N(μ1; σ1)的均值μ1和方差σ1,用来反转帧重建的高斯分布N(μ2; σ2)的均值μ2和方差σ2。
使用KL散度用在编码器高层特征的低维输出,
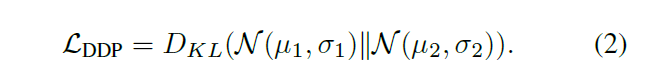
通过光流预测的目标函数或者反转帧重建目标函数,解码器都可以以类似的方式训练成自动编码器。在训练时,使用DDP作为损失函数,包括F范数和KL散度,是的两个解码器相互合作,提高编码器的学习能力。
5.3 Final Objectives
最终损失函数包括四部分:
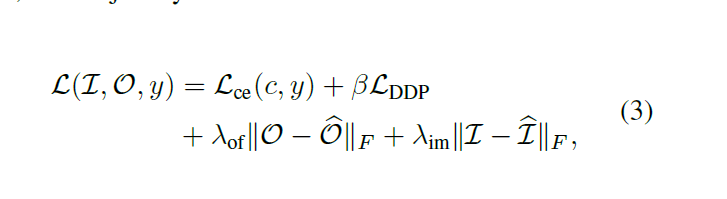
- Lce是分类器输出c和真实标签y之间的softmax交叉熵损失函数,
- O是提前用TLV1计算的光流,O^是生成的光流,λof是光流预测的损失权重;
- I是真实的输入帧,I^是生成的帧,λim是反转帧重建的损失权重;
- DDP
6、Experiments
主要进行了交叉数据验证和打乱验证实验,并与state-of-the-art进行比较,对于F范数和KL散度,只验证了前者,后者留给以后的工作。
6.1 Datasets
UCF101、HMDB51和Kinetics400数据集,耳熟能详,不说了。
6.2 Robustness: LongTerm or ShortTerm
在UCF101进行了帧打乱实验,对比了I3D和Rev2Net,可以看出无论long shuffle还是short shuffle,Rev2Net鲁棒性高,当完全打乱时,由于视频分类不同于图像分类,出现下降在所难免。

6.3 Robustness: Crossdataset Experiments
在UCF101和HMDB51上进行了交叉数据验证,对比了TSN和I3D、Rev2Net,Rev2Net泛化能力更好。

6.4 Final Results
在UCF101和HMDB51数据集上,与state-of-the-art比较的实验,如下

在kinetics400数据集上,与state-of-the-art比较的实验如下:

此外,对于传统动作识别,传统two-stream仍然是有用的,光流有不可或缺的作用,但是在交叉数据验证时,Rev2Net效果更好。
Ablation Study :在表5中,进行了添加不同解码器作用的验证,可以看到都起了作用。而且,当不使用DDP时情况比不使用反转帧重建情况更差,因此,需要DDP来限制特征学习的不一致问题。
7、Conclusions
本文主要通过两个实验(帧打乱和交叉数据实验),说明目前的two-stream方法不具备好的鲁棒性和泛化能力。
基于此,作者发现光流分支会对交叉数据验证时造成损害,因此设计了基于3DCNN的Rev2Net网络,并提出DDP。
最后在三个数据集上做了实验验证,表明Rev2Net更具鲁棒性和泛化能力。















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









