







 本文介绍了评分卡模型中定量和定性指标的筛选,特别是WOE值计算。针对连续变量,文章讲解了最优分段方法,包括等距分段和基于条件推理树的最优分段算法。对于离散变量,由于可能出现‘维数灾难’,需要进行降维处理。通过这些步骤,为信用风险评分卡的开发奠定了基础。
本文介绍了评分卡模型中定量和定性指标的筛选,特别是WOE值计算。针对连续变量,文章讲解了最优分段方法,包括等距分段和基于条件推理树的最优分段算法。对于离散变量,由于可能出现‘维数灾难’,需要进行降维处理。通过这些步骤,为信用风险评分卡的开发奠定了基础。
定量指标筛选见上篇:
http://blog.csdn.net/lll1528238733/article/details/76600019
定性指标筛选见上篇:
http://blog.csdn.net/lll1528238733/article/details/76600147
对入模的定量和定性指标,分别进行连续变量分段(对定量指标进行分段),以便于计算定量指标的WOE和对离散变量进行必要的降维。对连续变量的分段方法通常分为等距分段和最优分段两种方法。等距分段是指将连续变量分为等距离的若干区间,然后在分别计算每个区间的WOE值。最优分段是指根据变量的分布属性,并结合该变量对违约状态变量预测能力的变化,按照一定的规则将属性接近的数值聚在一起,形成距离不相等的若干区间,最终得到对违约状态变量预测能力最强的最优分段。
我们首先选择对连续变量进行最优分段,在连续变量的分布不满足最优分段的要求时,在考虑对连续变量进行等距分段。此处,我们讲述的连续变量最优分段算法是基于条件推理树(conditional inference trees, Ctree)的递归分割算法,其基本原理是根据自变量的连续分布与因变量的二元分布之间的关系,采用递归的回归分析方法,逐层递归满足给定的显著性水平,此时获取的分段结果(位于Ctree的叶节点上)即为连续变量的最优分段。其核心算法用函数ctree()表示。
根据表3.13所示的定量入模指标,我们采用上述最优分段算法,得到的最优分段结果分别如下。
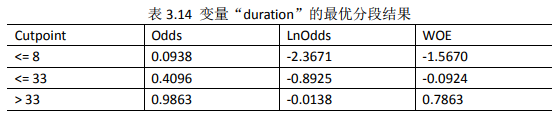
对变量“duration”进行最优分段:
#对duration进行最优分段
library(smbinning)
result<-smbinning(df=data,y="credit_risk",x="duration",p=0.05)
result$ivtable变量“duration”的最优分段结果,如表3.14所示
#对amount进行最优分段
result<-smbinning(df=data,y="credit_risk",x="amount")
result$ivtable 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6476
6476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









