







 本文深入讲解了Huffman编码原理及其实现方式,介绍了如何利用字符出现的概率构建Huffman树,并生成最优前缀码以实现数据的高效无损压缩。
本文深入讲解了Huffman编码原理及其实现方式,介绍了如何利用字符出现的概率构建Huffman树,并生成最优前缀码以实现数据的高效无损压缩。
转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/50374452
勿在浮沙筑高台
Huffman算法也是一种无损压缩算法,但与上篇文章LZW压缩算法不同,Huffman需要得到每种字符出现概率的先验知识。通过计算字符序列中每种字符出现的频率,为每种字符进行唯一的编码设计,使得频率高的字符占的位数短,而频率低的字符长,来达到压缩的目的。通常可以节省20%~90%的空间,很大程度上依赖数据的特性!Huffman编码是变长编码,即每种字符对应的编码长度不唯一。
前缀码:任何一个字符的编码都不是同一字符集中另一种字符编码的前缀。Huffman编码为最优前缀码,即压缩后数据量最小。
---------------------------------------------------------------------------------------------------------------
Huffman算法:
1.统计字符序列的每种字符的频率,并为每种字符建立一个节点,节点权重为其频率;
2.初始化最小优先队列中,把上述的结点全部插入到队列中;
3.取出优先队列的前两种符号节点,并从优先队列中删除;
4.新建一个父节点,并把上述两个节点作为其左右孩子节点,父节点的权值为左右节点之和;
5.如果此时优先队列为空,则退出并返回父节点的指针!否则把父节点插入到优先队列中,重复步骤3;
----------------------------------------------------------------------------------------------------------------
通过上述建造的Huffman树,可以看到,每种字符结点都是叶子结点,编码方法:从根节点开始向左定义编码'0',向右定义为'1',遍历到叶子结点所得到的二值码串,即为此种字符的编码值。由于字符码字为前缀码,在译码过程中,每种字符可以参照Huffman树被唯一的译码出,但是前缀码的缺点是,错误具有传播功能,当有1位码字错误,此后的译码过程很可能都不正确;
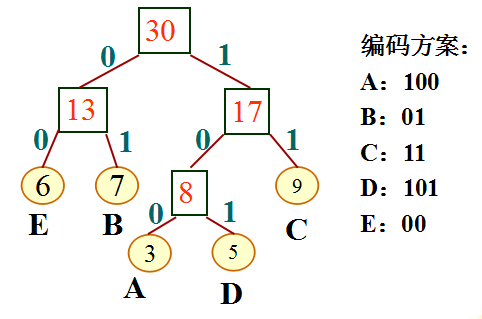
代码实现:
优先队列采用堆排序算法
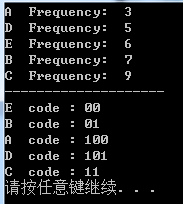
/*
CSDN 勿在浮沙筑高台
http://blog.csdn.net/luoshixian099
数据压缩--Huffman编码 2015年12月21日
*/
//main.cpp
#include <iostream>
#include <vector>
#include "compress.h"
using namespace std;
void ShowCode(PNode root, vector<char> &code);//显示编码
void FreeTREE(PNode root);
int main()
{
char A[] = "EEEEEEBBBBBBBAAADDDDDCCCCCCCCC";//原始数据
UINT Length = sizeof(A)-1;
Priority_Q queue(A, Length); //建立优先队列-堆排序
//输入每组字符的频率
for (UINT i = 0; i <= queue.Heap_Size;i++)
{
cout << (char)(queue.table[i]->key) << " Frequency: " << queue.table[i]->Frequency << endl;
}
cout << "--------------------" << endl;
PNode root = Build_Huffman_Tree(queue);//构建Huffman树
vector<char> code;
ShowCode(root, code); //显示编码数据
FreeTREE(root);
return 0;
}
void FreeTREE(PNode root)//释放内存
{
if ( root!=NULL)
{
FreeTREE(root->_left);
FreeTREE(root->_right);
delete root;
}
}
void ShowCode(PNode root,vector<char> &code)
{
if (root!=NULL)
{
if (root->_left == NULL && root->_right == NULL) //叶子结点
{
cout << (char)(root->key) << " code : " ;
for (UINT i = 0; i < code.size() ; i++)
{
cout << (int)code[i];
}
cout << endl;
return;
}
code.push_back(0);
ShowCode(root->_left,code);
code[code.size()-1] = 1;
ShowCode(root->_right,code);
code.resize(code.size()-1);
}
}/*
compress.cpp
*/
#include "compress.h"
Priority_Q::Priority_Q(char *A,int Length) //统计各种字符的频率
{
for (int i = 0; i < 256; i++)
{
table[i] = new Node;
}
Heap_Size = 0;
for (int i = 0; i < Length; i++) //统计字符频率
{
bool Flag = true;
for (int j = 0; j < Heap_Size; j++)
{
if ( table[j]->key == *(A+i) )
{
table[j]->Frequency = table[j]->Frequency + 1;
Flag = false;
break;
}
}
if (Flag) //加入新的字符
{
table[Heap_Size]->key = *(A + i);
table[Heap_Size]->Frequency = table[Heap_Size]->Frequency + 1;
Heap_Size++;
}
}
Heap_Size--;
Build_Min_Heap(Heap_Size); //建立优先队列
}
void Priority_Q::Build_Min_Heap(UINT Length)//建立优先队列
{
for (int i = (int)(Length / 2); i >= 0; i--)
{
Min_Heapify(i);
}
}
void Priority_Q::Min_Heapify(UINT i)
{
UINT Smaller = i;
UINT Left = 2 * i + 1;
UINT Right = 2 * i + 2;
if (Left <= Heap_Size && table[Left]->Frequency < table[i]->Frequency) //判断是否小于其孩子的值
{
Smaller = Left;
}
if (Right <= Heap_Size && table[Right]->Frequency < table[Smaller]->Frequency)
{
Smaller = Right;
}
if (Smaller != i) //如果小于,就与其中最大的孩子调换位置
{
Swap(i, Smaller);
Min_Heapify(Smaller);
}
}
void Priority_Q::Swap(int x, int y) //交换两个元素的数据
{
PNode temp = table[x];
table[x] = table[y];
table[y] = temp;
}
PNode CopyNode(PNode _src, PNode _dst)//拷贝数据
{
_dst->Frequency = _src->Frequency;
_dst->key = _src->key;
_dst->_left = _src->_left;
_dst->_right = _src->_right;
return _dst;
}
PNode Priority_Q::Extract_Min() //输出队列最前结点
{
if (Heap_Size == EMPTY)
return NULL;
if (Heap_Size == 0)
{
Heap_Size = EMPTY;
return table[0];
}
if (Heap_Size >= 0)
{
Swap(Heap_Size, 0);
Heap_Size--;
Min_Heapify(0);
}
return table[Heap_Size+1];
}
void Priority_Q::Insert(PNode pnode)//优先队列的插入
{
Heap_Size++;
CopyNode(pnode, table[Heap_Size]);
delete pnode;
UINT i = Heap_Size;
while ( i > 0 && table[Parent(i)]->Frequency > table[i]->Frequency )
{
Swap(i, Parent(i));
i = Parent(i);
}
}
Priority_Q::~Priority_Q()
{
for (int i = 0; i < 256; i++)
{
delete table[i];
}
}
PNode Build_Huffman_Tree(Priority_Q &queue) //建立Huffman树
{
PNode parent=NULL,left=NULL,right=NULL;
while (queue.Heap_Size != EMPTY)
{
left = new Node;
right = new Node;
parent = new Node;
CopyNode(queue.Extract_Min(), left); //取出两个元素
CopyNode(queue.Extract_Min(), right);
//复制左右节点数据
parent->Frequency = right->Frequency + left->Frequency;//建立父节点
parent->_left = left;
parent->_right = right;
if (queue.Heap_Size == EMPTY)
break;
queue.Insert(parent); //再插入回优先队列
}
return parent;
}/*
compress.h
*/
#ifndef COMPRESS
#define COMPRESS
#include <vector>
#define UINT unsigned int
#define UCHAR unsigned char
#define EMPTY 0xFFFFFFFF
#define Parent(i) (UINT)(((i) - 1) / 2)
typedef struct Node //结点
{
Node::Node():key(EMPTY), Frequency(0),_left(NULL),_right(NULL){}
UINT key;
UINT Frequency;
struct Node * _left;
struct Node * _right;
}Node,*PNode;
class Priority_Q //优先队列
{
public:
Priority_Q(char *A, int Length);
~Priority_Q();
void Insert(PNode pnode); //插入
PNode Extract_Min(); //取出元素
UINT Heap_Size; //队列的长度
PNode table[256]; //建立256种结点
private:
void Build_Min_Heap(UINT Length); //建立队列
void Swap(int x, int y); //交换两个元素
void Min_Heapify(UINT i); //维护优先队列的性质
};
PNode Build_Huffman_Tree(Priority_Q &queue);//构建优先队列
#endif // COMPRESS
参考:
http://wenku.baidu.com/view/04a8a13b580216fc700afd2e.html
http://blog.csdn.net/abcjennifer/article/details/8020695

















 7054
7054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









