









转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754
本文力求简化SMO的算法思想,毕竟自己理解有限,无奈还是要拿一堆公式推来推去,但是静下心看完本篇并随手推导,你会迎刃而解的。推荐参看SMO原文中的伪代码。
1.SMO概念
上一篇博客已经详细介绍了SVM原理,为了方便求解,把原始最优化问题转化成了其对偶问题,因为对偶问题是一个凸二次规划问题,这样的凸二次规划问题具有全局最优解,如下:
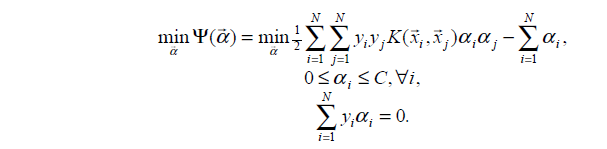
其中
(xi,yi)
表示训练样本数据,
xi
为样本特征,
yi∈{−1,1}
为样本标签,C为惩罚系数由自己设定。上述问题是要求解N个参数
(α1,α2,α3,...,αN)
,其他参数均为已知,有多种算法可以对上述问题求解,但是算法复杂度均很大。但1998年,由Platt提出的序列最小最优化算法(SMO)可以高效的求解上述SVM问题,它把原始求解N个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解2个参数,方法类似于坐标上升,节省时间成本和降低了内存需求。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。
2.SMO原理分析
2.1视为一个二元函数
为了求解N个参数
(α1,α2,α3,...,αN)
,首先想到的是坐标上升的思路,例如求解
α1
,可以固定其他N-1个参数,可以看成关于
α1
的一元函数求解,但是注意到上述问题的等式约束条件
∑Ni=1yiαi=0
,当固定其他参数时,参数
α1
也被固定,因此此种方法不可用。
SMO算法选择同时优化两个参数,固定其他N-2个参数,假设选择的变量为
α1,α2
,固定其他参数
α3,α4,...,αN
,由于参数
α3,α4,...,αN
的固定,可以简化目标函数为只关于
α1,α2
的二元函数,
Constant
表示常数项(不包含变量
α1,α2
的项)。
2.2视为一元函数
由等式约束得:
α1y1+α2y2=−∑Ni=3αiyi=ζ
,可见
ζ
为定值。
等式
α1y1+α2y2=ζ
两边同时乘以
y1,
且
y21=1
,得
2.3对一元函数求极值点
上式中是关于变量
α2
的函数,对上式求导并令其为0得:
∂Ψ(α2)∂α2=(K11+K22−2K12)α2−K11ζy2+K12ζy2+y1y2−1−v1y2+v2y2=0
1.由上式中假设求得了 α2 的解,带回到(2)式中可求得 α1 的解,分别记为 αnew1,αnew2 ,优化前的解记为 αold1,αold2 ;由于参数 α3,α4,...,αN 固定,由等式约束 ∑Ni=1yiαi=0 有 αold1y1+αold2y2=−∑Ni=3αiyi=αnew1y1+αnew2y2=ζ
ζ=αold1y1+αold2y2(4)
2.假设SVM超平面的模型为 f(x)=wTx+b ,上一篇中已推导出 w 的表达式,将其带入得f(x)=∑Ni=1αiyiK(xi,x)+b;f(xi) 表示样本 xi 的预测值, yi 表示样本 xi 的真实值,定义 Ei 表示预测值与真实值之差为Ei=f(xi)−yi(5)
3.由于 vi=∑Nj=3αjyjK(xi,xj),i=1,2 ,因此
v1=f(x1)−∑j=12yjαjK1j−b(6)
v2=f(x2)−∑j=12yjαjK2j−b(7)
把(4)(6)(7)带入下式中:
(K11+K22−2K12)α2−K11ζy2+K12ζy2+y1y2−1−v1y2+v2y2=0
化简得: 此时求解出的
αnew2
未考虑约束问题,先记为
αnew,unclipped2
:
(K11+K22−2K12)αnew,unclipped2=(K11+K22−2K12)αold2+y2[y2−y1+f(x1)−f(x2)]
带入(5)式,并记
η=K11+K22−2K12
得:
2.4对原始解修剪
上述求出的解未考虑到约束条件:
- 0≤αi=1,2≤C
- α1y1+α2y2=ζ
在二维平面上直观表达上述两个约束条件
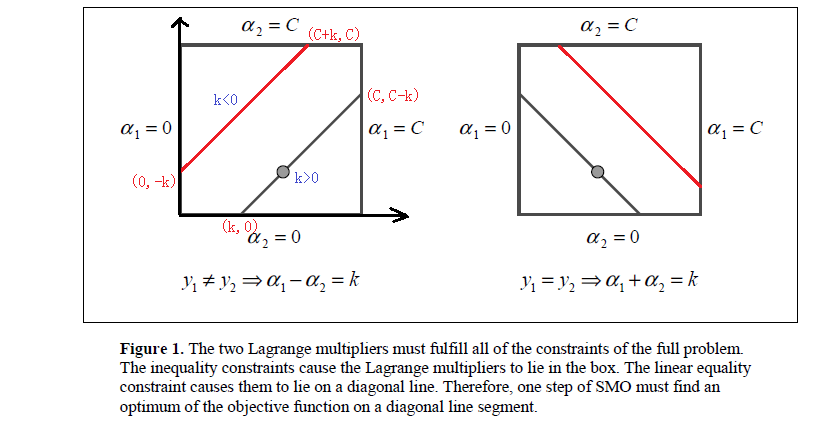
最优解必须要在方框内且在直线上取得,因此
L≤αnew2≤H
;
当
y1≠y2
时,
L=max(0,αold2−αold1);H=min(C,C+αold2−αold1)
当
y1=y2
时,
L=max(0,αold1+αold2−C);H=min(C,αold2+αold1)
经过上述约束的修剪,最优解就可以记为
αnew2
了。
2.5求解 αnew1
由于其他N-2个变量固定,因此
αold1y1+αold2y2=αnew1y1+αnew2y2
所以可求得
2.6取临界情况
大部分情况下,有 η=K11+K22−2K12>0 。但是在如下几种情况下, αnew2 需要取临界值L或者H.
- η<0 ,当核函数K不满足Mercer定理时,矩阵K非正定;
- η=0 ,样本 x1 与 x2 输入特征相同;
也可以如下理解,对(3)式求二阶导数就是
η=K11+K22−2K12
,
当
η<0
时,目标函数为凸函数,没有极小值,极值在定义域边界处取得。
当
η=0
时,目标函数为单调函数,同样在边界处取极值。
计算方法:
即当
αnew2=L
和
αnew2=H
分别带入(9)式中,计算出
αnew1=L1
和
αnew1=H1
,其中
s=y1y2
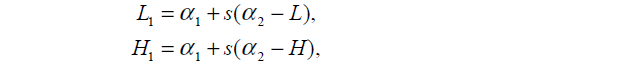
带入目标函数(1)内,比较
Ψ(α1=L1,α2=L)
与
Ψ(α1=H1,α2=H)
的大小,
α2
取较小的函数值对应的边界点。
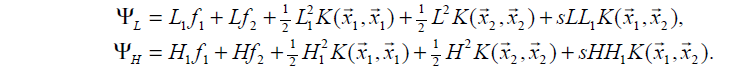
其中
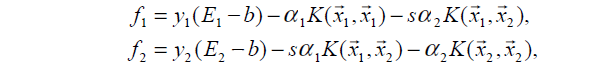
3.启发式选择变量
上述分析是在从N个变量中已经选出两个变量进行优化的方法,下面分析如何高效地选择两个变量进行优化,使得目标函数下降的最快。
第一个变量的选择
第一个变量的选择称为外循环,首先遍历整个样本集,选择违反KKT条件的
αi
作为第一个变量,接着依据相关规则选择第二个变量(见下面分析),对这两个变量采用上述方法进行优化。当遍历完整个样本集后,遍历非边界样本集(
0<αi<C
)中违反KKT的
αi
作为第一个变量,同样依据相关规则选择第二个变量,对此两个变量进行优化。当遍历完非边界样本集后,再次回到遍历整个样本集中寻找,即在整个样本集与非边界样本集上来回切换,寻找违反KKT条件的
αi
作为第一个变量。直到遍历整个样本集后,没有违反KKT条件
αi
,然后退出。
边界上的样本对应的
αi=0或者αi=C
,在优化过程中很难变化,然而非边界样本
0<αi<C
会随着对其他变量的优化会有大的变化。

第二个变量的选择
SMO称第二个变量的选择过程为内循环,假设在外循环中找个第一个变量记为
α1
,第二个变量的选择希望能使
α2
有较大的变化,由于
α2
是依赖于
|E1−E2|
,当
E1
为正时,那么选择最小的
Ei
作为
E2
,如果
E1
为负,选择最大
Ei
作为
E2
,通常为每个样本的
Ei
保存在一个列表中,选择最大的
|E1−E2|
来近似最大化步长。
有时按照上述的启发式选择第二个变量,不能够使得函数值有足够的下降,这时按下述步骤:
首先在非边界集上选择能够使函数值足够下降的样本作为第二个变量,
如果非边界集上没有,则在整个样本集上选择第二个变量,
如果整个样本集依然不存在,则重新选择第一个变量。
4.阈值b的计算
每完成对两个变量的优化后,要对b的值进行更新,因为b的值关系到f(x)的计算,即关系到下次优化时
Ei
的计算。
1.如果
0<αnew1<C
,由KKT条件
y1(wTx1+b)=1
,得到
∑Ni=1αiyiKi1+b=y1
,由此得:
由(5)式得,上式前两项可以替换为:
得出:
2.如果 0<αnew2<C ,则
3.如果同时满足 0<αnewi<C ,则 bnew1=bnew2
4.如果同时不满足 0<αnewi<C ,则 bnew1与bnew2 以及它们之间的数都满足KKT阈值条件,这时选择它们的中点。( 关于这个我不理解…)
建议参看SMO原文的伪代码
参考:
统计学习方法,李航
Sequential Minimal Optimization:A Fast Algorithm for Training Support Vector Machines,John C. Platt
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html

















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









