







转自http://blog.csdn.net/lvhao92/article/details/50817110
怀着复杂的心情诉说着SVM。以一个别处听到的故事为开场白,源自Please explain Support Vector Machines (SVM) like I am a 5 year old
某日,见蓝球红球于一桌欲分之

插一筷子于蓝红球之间则蓝红球可分
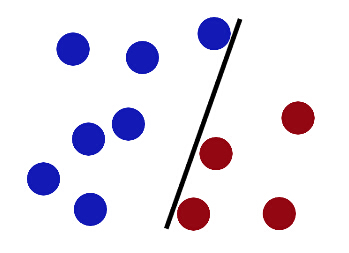
不料,随着球之增多,一红球出界毁吾之分割。可惜可气
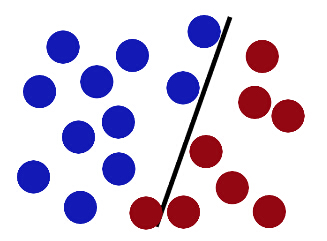
不服,遂变化筷子方向则又可分红蓝球也。
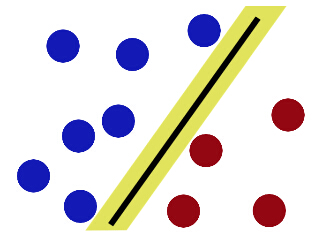
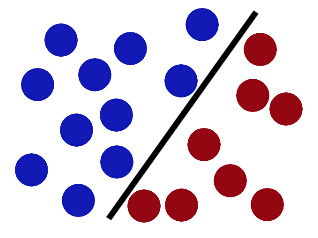
终有体会,欲合理分清红蓝之球,必使得近处红蓝球于筷子越远越好。
他日,又偶遇如下一堆红蓝球,吾又欲分之
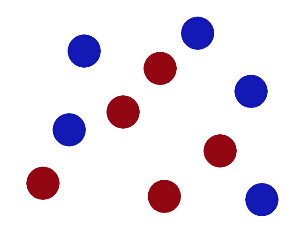
拿筷子比划半天无从分离,百思不得其解。大怒,猛一拍桌。
见桌上之球于空中仿佛有可分之势,蓝上红下。大喜,顺势抽一张纸隔于蓝红球之间,则蓝红之球可分。
遂可得,若桌面上不可分(2维),则拍桌,将球腾空而起(3维),则可分之。
若将3维之图从顶俯视,则分界面可视作下图曲线。

故事终。
以上便是SVM的故事。下面细说。
但凡提及SVM,必走吴老师授课套路。这是比较合理的。
我们先看这个2维的分2类的简单例子。
1.函数距离,几何距离
我们先定义例子中的那双分割的筷子就叫做划分超平面。并定义其为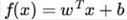
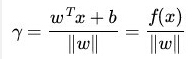
但是,这个只是表示距离。我们不光要知道的是距离,我们需要的是分配正确之后的距离,前提条件还有个分配正确。不着急。重新定义一下,如果我们认为蓝球的标签y为+1而红球的标签y为-1。
所以,一旦碰到一个新的x,将x带入f(x)中,我们希望如果f(x)小于0,那么将f(x)的类别赋予-1,如果f(x)大于0,那么就将f(x)的类别赋予+1。
如果超平面(ωx+b)确定的情况下,则|ωx+b|是不是也可以描述点到超平面的距离呢?那么我们可以用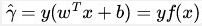
但是这个间隔是有问题的。比如将ω和b扩大2倍,虽然我们的超平面并没有改变。可是我们的函数间隔却硬生生的扩大为原来的两倍。
为什么不能愉快的在点到直线的距离乘那个标签,然后以此来表示分类正确与否的可信度?为什么不带γ中的分母||ω||呢?
这是当然是可以的,于是我们得到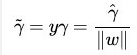
由上面例子中可得,我们希望求得的是离筷子最接近的球到筷子的距离越大越好(也就是例子中我要移动筷子,使得筷子搁两类球的中间并且与两边的球越不挨着越好),所以那么多球里面,比较重要的就是离筷子比较近的球。反正我旋转移动筷子的时候,只考虑筷子与这些球的位置关系就可以了。没必要考虑后面的那么多。(SVM主要思想,这些球也就是支持向量,这是后话)。
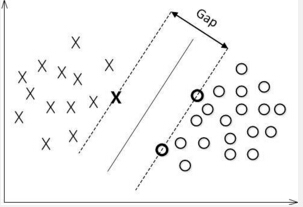
2.最大化分类间隔
既然如此,那么我就要最大化分类间隔了。那我就要移动筷子使得它与两边离他最近球的距离最大化,即最大化下图的Gap
函数间隔不适合用来表述这个Gap。关键是因为函数间隔会随着ω的变化而变化,而几何间隔只随着超平面的变化而变化,是不随着ω的改变而改变的。因此,我们选用几何间隔来描述这个Gap。同时,为了简化计算,我们设定这些离筷子最近的球的函数距离为1。(其实这里函数距离设定成任何值都可以,因为之前所说函数距离会随着ω和b同比扩大或者缩小,这就好像是我的坐标轴上的值一直都在变化,而球和筷子的位置却没有变化,而SVM我们是固定球的位置,需要改变筷子的位置,所以几何意义显得比较有意义,所以把函数距离设定成1只是方便计算)
因此,可以得到下图。
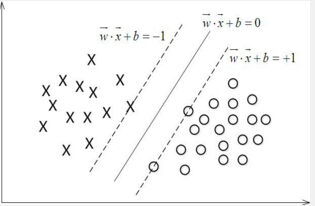
那这个Gap的值为多大呢?既然这些点的函数距离都为1了,那么根据函数距离和几何距离的关系
而同时,我们也要有个约束条件
于是,我们得到如下的式子:
对式子做个变形
为什么变这样?因为好算。怎么变的?自己看吧。
这个式子就叫做SVM的基本型。
3.拉格朗日对偶
注意上面我们需要优化的东西,竟然还有不等式约束,因此,立马反应到拉格朗日
这一个式子就可以表示

接下来就是要求解
但是可以解它的对偶问题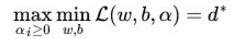
所以,立刻有思路了。
1)先对ω和b求偏导,另其等于0
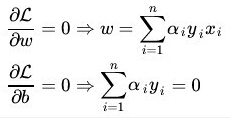
将其回代到L中,可得
最大化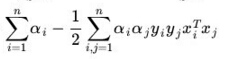
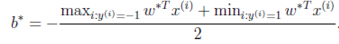

模型不就可以转化为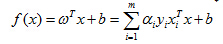
那么我们的超平面就能被唯一确定啦,那么我们筷子的位置就唯一确定了。想想还真激动呢。下面快速说下两个问题。1.KKT。2.SMO。
3.1 KKT
虽然,我们上面通过将式子转化为对偶问题解的非常开心,但是你这么随意的转化为对偶问题了,人家同意吗?
我们之前默认了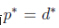
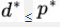
即要求
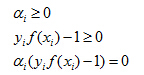
对于训练样本(xi,yi)如果αi为0,那么根据
3.2 SMO
SMO算法是在求α的时候用到的算法。基本思路就是固定除αi之外的所有参数,然后求αi的极值。由于存在约束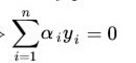
所以,如果你固定除αi之外的所有参数的话,αi也是可以由其他变量求出来的。于是SMO每次选择两个变量αi和αj,并固定其他的参数。这样SMO不断执行两个步骤直至收敛。
1.选取一对需要更新的变量αi和αj;2.固定αi和αj以外的参数,求解最大化
在选取要更新的变量αi和αj的时候比较有意思。直观上看,选取的αi和αj违背KKT条件的程度越大,那么变量更新后可能导致函数值减幅增大,所以,SMO使选取的两变量所对应样本之间的间隔最大。直观的解释就是,这样的两个变量有很大的差别。这样会给目标函数值带来更大的变化。
4.核技巧
好了,之前所说的是线性可分的,而如果存在线性不可分的怎么办?
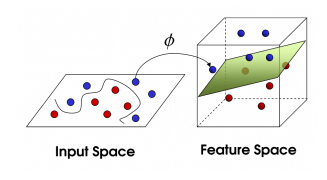
通过前面的例子,各位可能知道了,一根筷子解决不了的问题,拍一下桌子,将球弹起来,然后去区分。也就是升维。
科学的说,是将原来的样本从原始空间映射到一个高维的特征空间,使得样本在这个特征空间内线性可分。如果原始空间是有限维的。那么一定存在一个高维特征空间使样本可分。
令Φ(x)表示将x映射后的特征向量,可是,这样每次都会涉及到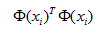
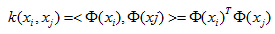
记住,特征映射就只是特征映射,他不是核技巧,核技巧只是使得
不过,如果已知Φ(x)的具体形式了,那么核函数k(.,.)也可以得到,但是特征空间在现实生活中我们并不知道而且它的好坏对支持向量机的性能至关重要。所以,我们并不知道什么样的核函数是合适的,而核函数仅仅是隐式的定义这个特征空间。“核函数的选择”成为支持向量机的最大变数。若核函数选的不合适,效果肯定不好。
就先这样吧
















 5532
5532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









