






LeCun经典论文,现在才分析,罪过罪过
摘:本文其实通过卷积神经网络得到一个立体匹配成本stereo matching cost,而后面则是一系列的后处理:cross-based cost aggregation, semiglobal matching, a left-right consistency check, subpixel enhancement,a median filter, a bilateral filter.
(重点是分析这些传统的后处理,看能否用在现在的网络上,其次回顾一下经典的mc-cnn)
介:
经典的立体匹配算法分为四步: matching cost computation, cost aggregation, optimization, disparity refinement。本文关键就是计算出一个优秀的matching cost,可以用cross-based cost aggregation来将matching cost 与有着相似图像强度的领域像素结合起来,再用semiglobal matching(SGM)和left-right consistency来消除一些错误让整个结果图看上去更加的平滑,最后可以用subpixel enhancement ,median filter 和 bilateral filter得到一个最佳的最终结果。
Matching Cost
一个简单的matching cost成本函数就是左图右图对应位置亮度差之和
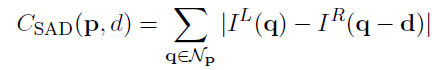
constructing the data set
不明白为何还要建立一个立体匹配数据的正负样本,二分类?建这个样本库有什么用呢?
Network architectures
建立两个网络,一个为了速度,一个为了性能。二者输入都是小图像块输出都是它们之间的相似度的测量。二者都用特征提取器来将每个图像块提取成特征向量。块之间相似度是作用在特征向量上而不是原始图像像素强度值上。fast结构是用一个固定的相似性测量,而accurate结构是用一个更好的相似性测量
Fast Architecture
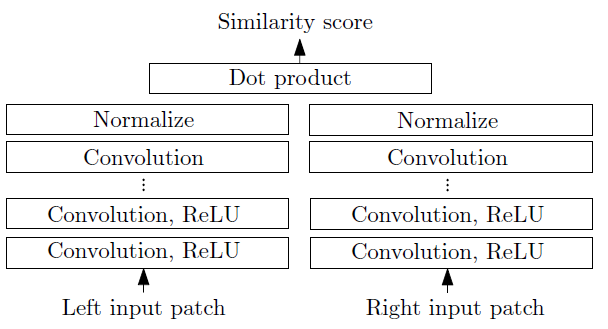
图1 快结构 fast architecture
快结构是一个双塔网络,两个子网络均由一系列的带有Relu的卷积层构成。两个输入块的特征向量之间的余弦cosine相似度作为相似度得分。余弦相似度计算被分为两个步骤:正则规范化和点乘。因为每个位置上面正则规范化只需要运行一次因此这非常节约时间。同时,网络训练的loss是hinge loss(难怪前文强行给样本做成正负样本),loss是根据在图像中同样位置的样本对来计算得到的。这个样本对呢,一个是正样本,一个属于负样本。
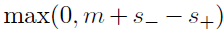
其中S+就是正样本经过网络输出的相似度,S-就是负样本经过网络输出的相似度,m是一个正实数,一般设置成0.2。也就是说当正样本的输出相似度比负样本相似度大的超过m的时候,这个loss会是0,这么看来也是有点道理的!
准确结构 accurate architecture
这个准确网络与快网络最大的不同就是,用一个全连接层来代替余弦相似性度量。这样使得运行时间增加了,但是使得error降低了。同样子网络由很多带Relu的卷积层构成。两个经过特征提取的特征向量会concated然后前向经过很多全连接层(带Relu)。最后一个全连接层会产生一个单独的数字(sigmoid输出),这个数字可以看作输入块的相似性得分。
训练的loss是二元cross-entropy loss(注意与快网络的hinge loss不同),式子就是
那有人要问了,为什么要用两个不同的loss呢,一个原因,经验!而实验告诉我们,cross-entropy loss性能要好于hinge loss,然而,在fast 结构当中,由于我们需要求的是余弦相似计算,所以cross-entropy loss并不直接适用
computing the matching cost
网络的输出是用来初始化matching cost:
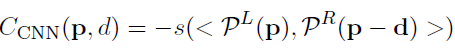
P^L(P)与P^R(p-d)是输入块,此刻,并非计算相似性得分而是匹配成本。
既然要计算全部的匹配成本Cnn(p,d)。应该考虑到每个位置以及每个视差。这样的话非常耗时且低效,不过有三条策略让运行时间可控;
1.每个位置值需要对两个子网络的输出计算一次,不需要对每个视差重复计算。
2.两个子网络的输出以图像全分辨率的大小一次性的计算所有的像素。这样只需要进行一次单独的前向,而不是将图片分成若干小块,只在W×H的图像上进行一次前向总比进行wh次前向要快得多。
3.accurate结构中的全连接层的输出也可以仅在一个前向传播中计算。这需要以1×1大小核的卷积层来代替每个全连接层。我们仍然需要考虑每个视差,因此,网络全连接需要运行d次,这就是accurate结构一个瓶颈。
为了计算图像对的匹配成本,对于每个图像运行一次子网络然后运行d次全连接层,其中d就是最大的视差。视野在设计网络结构的时候非常重要。首先,我们应该选择一种结构,接着两个图像concatenated,这确实挺耗时间的,因为整个网络需要运行d次,insight也带来了快结构的进步,其中唯一需要运算d次的是特征向量的dot product。















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









