






最近专心看flownet,在跑代码,但愿有个好结果。如果出问题,应该是delay_mult也设置成10的问题了。
训练过程看flownet2论文
从图中结果看,flownet2的结果更加平滑,2代相对于1代在质量和速度上都有了显著的提升

1.注重了训练样本质量
2.提出了网络堆结构,以中间光流状态改变第二张图的形态
3.通过引入专门针对小运动的子网络来增强网络对于小位移的性能
2代速度比1代略有逊色,但是估算误差提升了超过50%。当非要比速度的话,那么在性能等同的情况下,2代速度也是优于1代的。
1.介绍
1代flownet是光流估计中的一股清流,这种用CNN直接从数据中学习光流的新奇想法与以往方法大不相同。想法固然优秀,性能有待提高,毕竟1代,逃不出这样的魔咒。然而可以用合并的方式,势在打破这样的魔咒。所以2代的想法就是要合并flownet。2代继承了1代的某些优点,如对于大位移性能较好,光流域细节不放过,不虚奇葩区域以及运算时间较快。同时,这解决了小位移问题以及估算光流域中的噪声问题。这引领了现实世界应用的潮流,对工作识别和运动分割都带来了划时代的影响。
新的就是引入的数据更多更好,还有,explicit correlation层对flownet很关键?
第二个贡献,引入形变操作,通过形变堆叠多网络能够得到比较好的结果,通过变化堆叠的深度和独立个体的尺寸,可以得到不同尺寸和运行时间的许多网络变种。这让我们在准确度和计算损耗之间进行权衡。我们提供了范围为8到140的网络。
最终,我们专注于小运动和真实世界的数据。因此创造了特别的训练集还有特殊的网络。基于此数据集的特定网络只是对于真实世界中小运动有着良好的效果。为了对于任意位移都能达到最佳的性能,我们添加了融合前面堆叠网络的网络,前面的堆叠网络是针对小位移网络的。
最终结果必然很好
2.相关工作
其他工作有由粗到细的金字塔思想还有端到端的涉及到3DCNN的网络,都效果不好
refinement用多出来的堆CNN代替做这些post-processing
网络包括扭曲层,这些层为第二张图中的初始运动进行补偿。
3.数据集
训练数据质量种类很重要,出场顺序也很重要!
比如先用一个训练强颜色匹配。粗训练。再用3Dthings进行finetuning,学习3D运动的特征以及现实光影。300K的时候网络才有收敛点额趋势,现在才训练20K,不急
4 堆叠网络
两个网络,第一个网络正常算,得到一个估计的光流,然后通过估计的光流对图二进行warp,然后再把新的图二和图一再通过一个网络进行计算,就是算的纯差异。一般第二个网络都是随机初始化的,可以固定第一个网络或者和第二个网络一同更新。或者前400K次迭代,网络一权重固定,这个作为网络二的最佳初始化值。
得到如下观察:1)堆叠网络易过拟合如果只堆叠网络不warp的话,2)stack和warp同时使用比较好。3)如果stack网络非要端到端训练的话,Net1层加intermediate loss比较好。4)固定第一个网络在warp操作之后训练第二个网络可以得到最佳的结果。
堆叠网络是原始网络的两倍。过拟合是个大问题。最好的办法是网络一个接一个的训练。不然会容易过拟合。
4.2 堆叠不同种类的网络
可以堆叠不同种类不同尺寸大小的网络,第一个网络叫做bootstrap网络,第二个网络如果连权重都一样就无脑重复,对结果并没有太多收益,不同权重的stack还好点,因此固定已存网络,添加新网络。可以用C和S同时作为bootstrap网络,因为如果仅仅用C的话双塔结构产生的结构对下一个网络难以理解。可以通过对通道数的减少从而对网络进行精简,最佳精简的尺寸是3/8(这就解释了小网络的通道数192对应了512,384对应1024。这个关系就是3比8的关系)
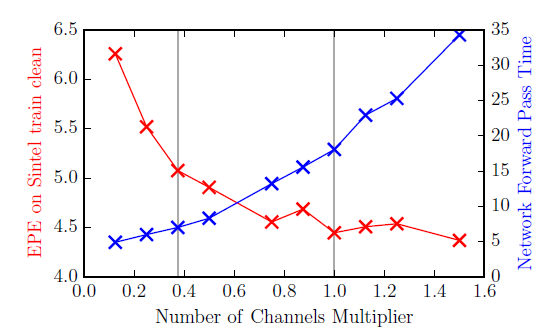
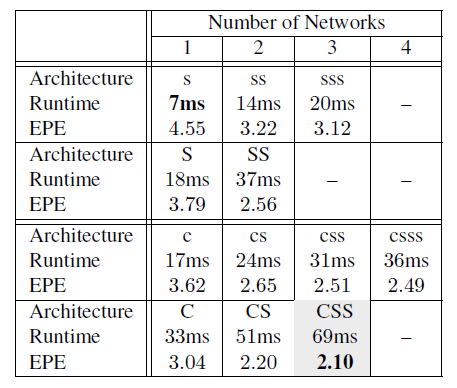
上表每个新网络先用Slong训练Chairs这个模型,再用Sfine训练things3D(以后需要注意一下Solver文件,目前看来fine的时候,学习率下降10倍而已)
网络都是通过一个接一个的方式去训练,瘦版就是通道数缩水3/8。训练样本schedule都是Chairs至Things3D。
CSS一定比C要好,瘦版网络速度快,参数少。
5.Small Displacements
5.1数据集
数据集一定要用包含small displacements的数据进行训练,UCF101数据集挺不错,不过本文作者还创建了ChairsCDHom数据集。
5.2 small displacement网络还有fusion网络
最终的网络不仅能处理small displacements还能够处理large displacements,然而,亚像素运动时,噪声是个大问题,因此SD网络的卷积核前两层都采用3×3,而非7×7和5×5同时移除了第一层中的步长为2。small displacements当中的噪声是个问题,因此,反卷积时加再加一个卷积,使得预测更加平滑。
最后,创造一个小网络联合css和sd网络,fusion网络接受很多,各种都拿来作为输入,扬长避短,最终对fusion网络的性能表示怀疑。如果真如文中所说,那真的神了。同时,作者提供的代码中并没有fusion网络,难不成要根据给的supplementary自己搭建?
文中说对KITTI数据fine-tuning的时候,由于KITTI的数据视差比其他数据视差要小,KITTI视差一般150像素左右,其他数据视差500左右,因此,在KITTI上面finetuned的时候,当网络预测大displacements的时候网络就会失去性能,就会造成大的损失。这也许能解释,为什么displacement设置成40的时候,模型训练6W次可以对测试图片效果好,而displacement设置成60的时候,模型在40的基础上finetuning 14万次之后的输出很糟糕。或许是因为测试数据图像适合displacement为40的模型,不适合displacement为60的模型。文中说displacement为40的时候,代表着输入图像中160像素,不理解,不应该是80像素么。。。看log输出channel也是81啊
up-convolution的时候添加convolution可以使得结果更加的平滑,更好的拟合视差图片

左图没有convolution,右图有,结果更加平滑。也就是S最好都变成SD。















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









